数据显示及训练方法
转自:http://blog.csdn.net/sileixinhua/article/details/70477303源码地址:https://github.com/sileixinhua/Python_data_science_by_iris本项目为机器学习的学习笔记 用iris.csv作为数据集 测试了一下功能代码实验环境:Windows10Sub
·
转自:http://blog.csdn.net/sileixinhua/article/details/70477303
本项目为机器学习的学习笔记 用iris.csv作为数据集 测试了一下功能代码
实验环境:
Windows10
Sublime
Anaconda 1.6.0
Python3.6
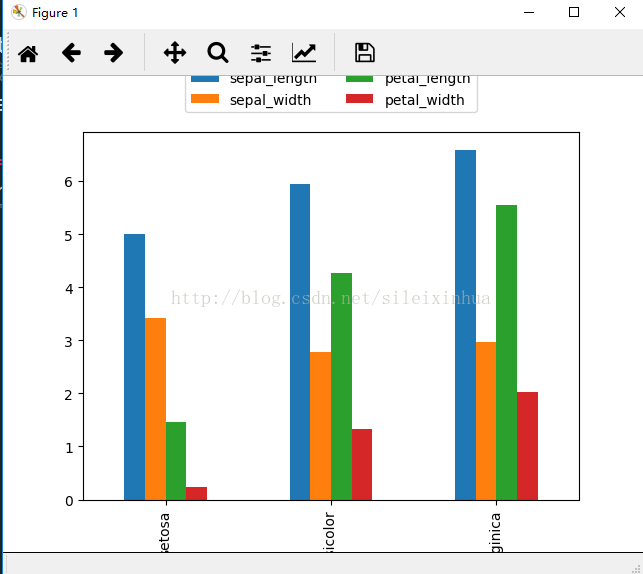
1.条状图显示组平均数,可以从图上看出不同的花种类中,他们的属性特点。
运行结果
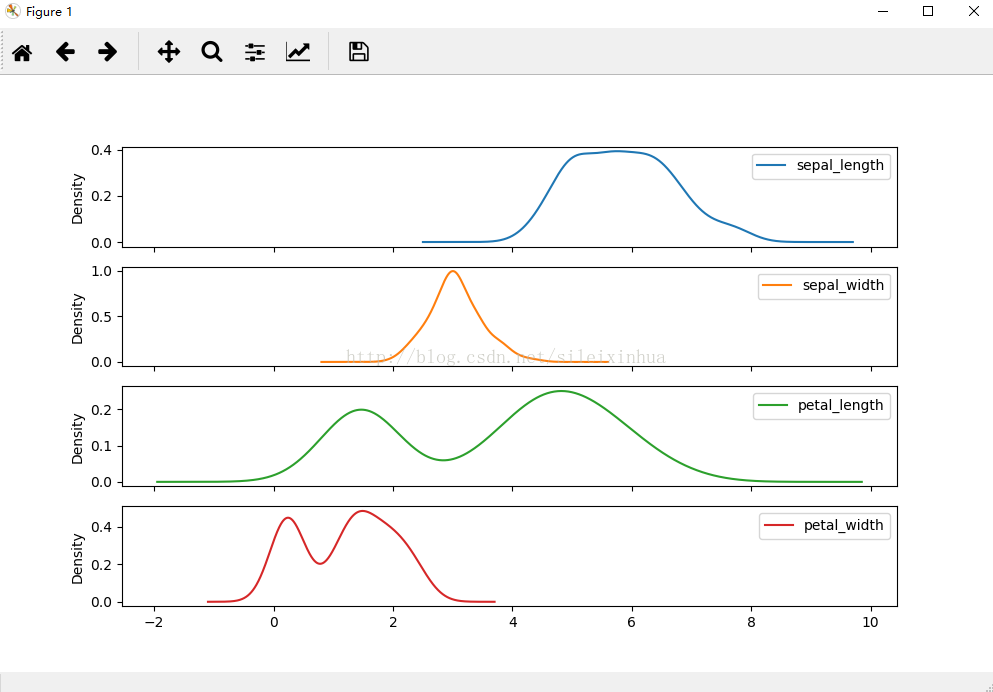
2.画kde图
运行结果
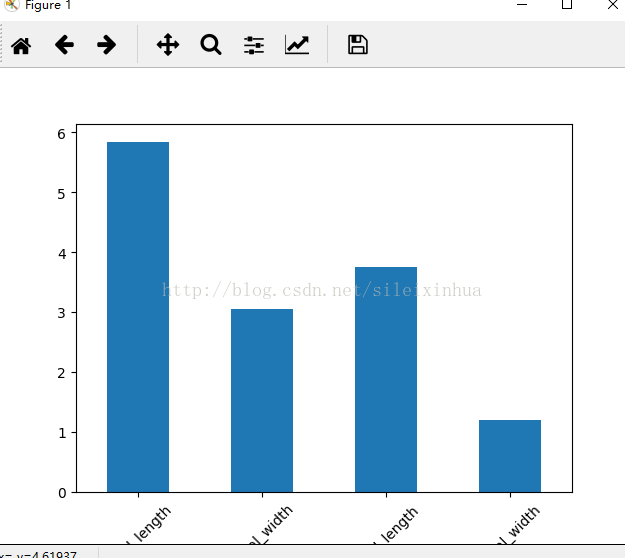
3.四种属性特征的平均值 条状图
运行结果
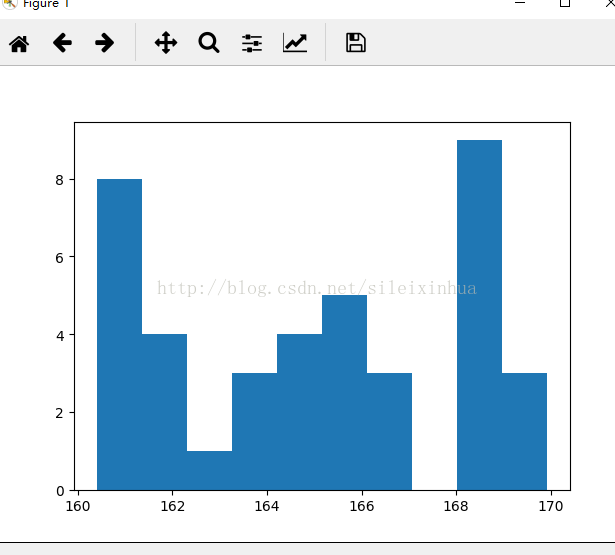
4.用numpy创建随机值,测试,与数据项目无关
运行结果
5.绘制样本图
运行结果
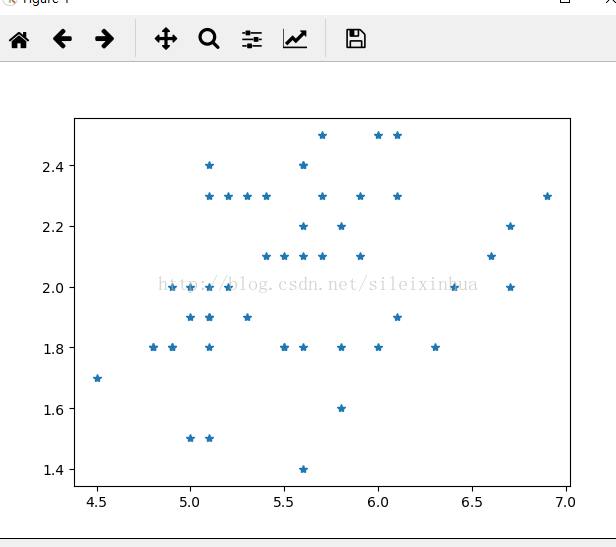
6.用sqlite3读取数据
7.用pandas读取数据
8.用原生Python读取数据
9.用sqlalchemy 读取数据
10.用sklearn的交叉验证 训练数据集
运行结果
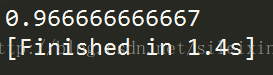
验证精度为0.97
11.用sklearn的KNN 训练数据集
运行结果
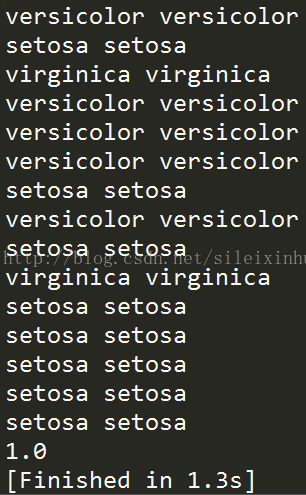
验证精度为1.0
12.用sklearn的逻辑斯蒂回归 训练数据集
运行结果
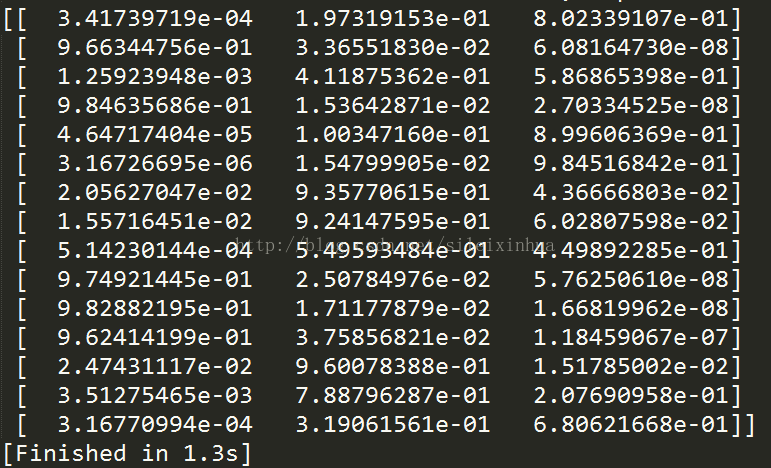
图上为预测的数据
13.用sklearn的朴素贝叶斯 训练数据集
运行结果
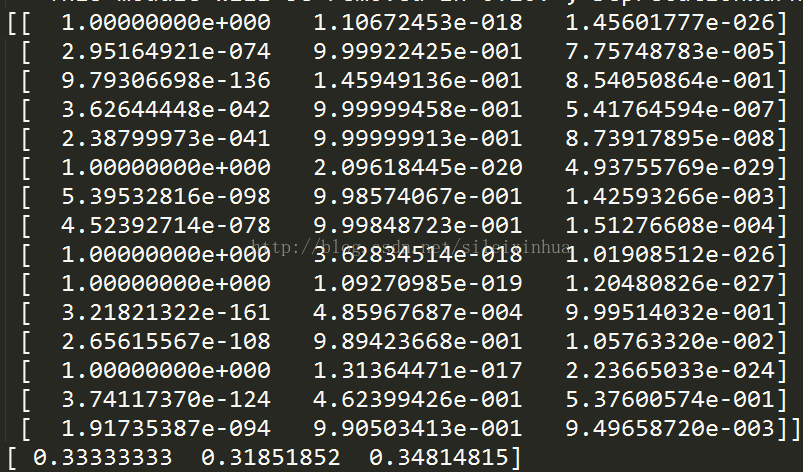
图上为预测的数据和分组的结果
14.用sklearn的交叉验证 KNN 逻辑蒂斯回归 三种方式 训练数据集 并对比
运行结果
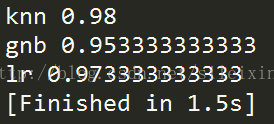
KNN算法的验证精度为0.98
朴素贝叶斯算法的验证精度为0.95
逻辑斯蒂回归算法的验证精度为0.97
15.
用sklearn的SVM 训练数据集
运行结果
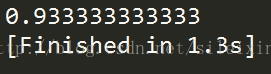
验证精度为0.93
参考文献:
《统计学习方法》
《
Web scraping and machine learning by python》

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)