
FinGPT: Open-Source Financial Large Language Models FinGPT:开源金融大型语言模型
大型语言模型(LLMs)已展现出在多个领域革新自然语言处理任务的潜力,因此在金融领域引起了极大的兴趣。访问高质量金融数据是金融LLMs(FinLLMs)面临的首个挑战。尽管像BloombergGPT这样的专有模型利用了其独特的数据积累优势,这种特权访问促使人们寻求一个开源的替代方案,以民主化互联网规模的金融数据。在本文中,我们介绍了一个针对金融部门的开源大型语言模型,FinGPT。与专有模型不同,
Abstract 摘要
大型语言模型(LLMs)已展现出在多个领域革新自然语言处理任务的潜力,因此在金融领域引起了极大的兴趣。访问高质量金融数据是金融LLMs(FinLLMs)面临的首个挑战。尽管像BloombergGPT这样的专有模型利用了其独特的数据积累优势,这种特权访问促使人们寻求一个开源的替代方案,以民主化互联网规模的金融数据。
在本文中,我们介绍了一个针对金融部门的开源大型语言模型,FinGPT。与专有模型不同,FinGPT采取了以数据为中心的方法,为研究人员和实践者提供了可访问和透明的资源,以开发他们的FinLLMs。我们强调了自动化数据策展管道和轻量级低秩适应技术在构建FinGPT中的重要性。此外,我们展示了几个潜在的应用作为用户的垫脚石,如机器人咨询、算法交易和低代码开发。通过开源AI4Finance社区内的协作努力,FinGPT旨在激发创新,民主化FinLLMs,并在开放金融中解锁新机遇。
两个相关的代码仓库为https://github.com/AI4Finance-Foundation/FinGPT 和 https://github.com/AI4Finance-Foundation/FinNLP。
Large language models (LLMs) have shown the potential of revolutionizing natural language processing tasks in diverse domains, sparking great interest in finance. Accessing high-quality financial data is the first challenge for financial LLMs (FinLLMs). While proprietary models like BloombergGPT have taken advantage of their unique data accumulation, such privileged access calls for an open-source alternative to democratize Internet-scale financial data. In this paper, we present an open-source large language model, FinGPT, for the finance sector. Unlike proprietary models, FinGPT takes a data-centric approach, providing researchers and practitioners with accessible and transparent resources to develop their FinLLMs. We highlight the importance of an automatic data curation pipeline and the lightweight low-rank adaptation technique in building FinGPT. Furthermore, we showcase several potential applications as stepping stones for users, such as roboadvising, algorithmic trading, and low-code development. Through collaborative efforts within the open-source AI4Finance community, FinGPT aims to stimulate innovation, democratize FinLLMs, and unlock new opportunities in open finance.
Two associated code repos are https://github. com/AI4Finance-Foundation/FinGPT and https:// github.com/AI4Finance-Foundation/FinNLP
1 Introduction 引言
人工智能的持续扩展和演化为大型语言模型的增长提供了肥沃的土壤【Vaswani et al., 2017; Radford et al., 2018; Devlin et al., 2018; Ethayarajh, 2019; Lewis et al., 2019; Lewis et al., 2020; Brown et al., 2020; Thoppilan et al., 2022】,从而在多个领域内的自然语言处理景观中引起了变革性的转变。这一彻底的变化在金融领域对这些模型潜在应用的兴趣中激发了极大的兴趣。然而,显而易见的是,获取高质量、相关且最新的数据是开发一个有效且高效的开源金融语言模型的关键因素。
在金融领域使用语言模型揭示了复杂的挑战。这些挑战范围从获取数据的困难、处理多种数据格式和类型、管理数据质量的不一致,到对最新信息的基本需求。特别是,历史或专门的金融数据提取由于数据媒介的不同,如网站平台、API、PDF文档和图像,证明是复杂的。
The continual expansion and evolution of artificial intelligence have provided a fertile ground for the proliferation of large language models [Vaswani et al., 2017; Radford et al., 2018; Devlin et al., 2018; Ethayarajh, 2019; Lewis et al., 2019; Lewis et al., 2020; Brown et al., 2020; Thoppilan et al., 2022], thereby effecting a transformative shift in the landscape of natural language processing across diverse domains. This sweeping change has engendered keen interest in the potential application of these models in the financial realm. It is, however, evident that the acquisition of high-quality, relevant, and up-to-date data stands as a critical factor in the development of an efficacious and efficient open-source financial language model.
Utilizing language models in the financial arena reveals intricate hurdles. These range from difficulties in obtaining data, dealing with diverse data formats and types, and managing data quality inconsistencies, to the essential requirement of up-to-date information. Especially, historical or specialized financial data extraction proves to be complex due to varying data mediums such as web platforms, APIs, PDF documents, and images.
在专有领域,像BloombergGPT【Wu et al., 2023】这样的模型利用其对专门数据的独家访问来训练特定于金融的语言模型。然而,他们的数据收集和训练协议的受限访问性和透明度加剧了对一个更开放和包容性替代品的需求。为了响应这一需求,我们正见证着向在开源领域民主化互联网规模金融数据的趋势转变。
In the proprietary sphere, models like BloombergGPT [Wu et al., 2023] have capitalized on their exclusive access to specialized data to train finance-specific language models. However, the restricted accessibility and transparency of their data collections and training protocols have accentuated the demand for a more open and inclusive alternative. In response to this demand, we are witnessing a shifting trend towards democratizing Internet-scale financial data in the open-source domain.
在本文中,我们讨论了与金融数据相关的上述挑战,并介绍FinGPT,一个端到端的开源金融大型语言模型(FinLLMs)框架。FinGPT采用以数据为中心的方法,强调数据获取、清洗和预处理在开发开源FinLLMs中的关键作用。通过提倡数据可访问性,FinGPT旨在增强金融领域的研究、合作和创新,为开放金融实践铺平道路。我们的贡献总结如下:
-
民主化:作为一个开源框架,FinGPT旨在民主化金融数据和FinLLMs,揭示开放金融中未被挖掘的潜力。
-
以数据为中心的方法:认识到数据策展的重要性,FinGPT采用以数据为中心的方法并实施严格的清洗和预处理方法来处理各种数据格式和类型,从而确保数据的高质量。
-
端到端框架:FinGPT采用了一个完整的FinLLMs框架,包含四个层次:
-
数据源层:该层保证全面的市场覆盖,通过实时信息捕捉解决金融数据的时间敏感性问题。
-
数据工程层:为实时NLP数据处理而设计,该层解决了金融数据高时间敏感性和低信噪比的固有挑战。
-
LLMs层:关注一系列微调方法,该层减轻了金融数据高度动态的本质,确保模型的相关性和准确性。
-
应用层:展示实用应用和演示,该层突出了FinGPT在金融领域的潜在能力。
-
我们对FinGPT的愿景是作为在金融领域内激发创新的催化剂。FinGPT不仅提供技术贡献,而且还培育了一个FinLLMs的开源生态系统,促进实时处理和用户的定制化适应。通过在开源AI4Finance社区内培养一个强大的协作生态系统,FinGPT定位于重塑我们对FinLLMs的理解和应用。
In this paper, we address these aforementioned challenges associated with financial data and introduce FinGPT, an endto-end open-source framework for financial large language models (FinLLMs). Adopting a data-centric approach, FinGPT underscores the crucial role of data acquisition, cleaning, and preprocessing in developing open-source FinLLMs. By championing data accessibility, FinGPT aspires to enhance research, collaboration, and innovation in finance, paving the way for open finance practices. Our contributions are summarized as follows:
• Democratization: FinGPT, as an open-source framework, aims to democratize financial data and FinLLMs, uncovering untapped potentials in open finance.
• Data-centric approach: Recognizing the significance of data curation, FinGPT adopts a data-centric approach and implements rigorous cleaning and preprocessing methods for handling varied data formats and types, thereby ensuring high-quality data.
• End-to-end framework: FinGPT embraces a full-stack framework for FinLLMs with four layers:
– Data source layer: This layer assures comprehensive market coverage, addressing the temporal sensitivity of financial data through real-time information capture.
– Data engineering layer: Primed for real-time NLP data processing, this layer tackles the inherent challenges of high temporal sensitivity and low signal-tonoise ratio in financial data.
– LLMs layer: Focusing on a range of fine-tuning methodologies, this layer mitigates the highly dynamic nature of financial data, ensuring the model’s relevance and accuracy.
– Application layer: Showcasing practical applications and demos, this layer highlights the potential capability of FinGPT in the financial sector.
Our vision for FinGPT is to serve as a catalyst for stimulating innovation within the finance domain. FinGPT is not limited to providing technical contributions, but it also cultivates an open-source ecosystem for FinLLMs, promoting real-time processing and customized adaptation for users. By nurturing a robust collaboration ecosystem within the open-source AI4Finance community, FinGPT is positioned to reshape our understanding and application of FinLLMs.
2 Related Work 相关工作
2.1 LLMs and ChatGPT 大型语言模型与ChatGPT
大型语言模型(LLMs)已被认为是自然语言处理技术的一个重大突破,例如GPT-3和GPT-4【Brown et al., 2020】。它们采用基于变压器的架构,在各种生成任务中展现出令人印象深刻的性能。
作为OpenAI开发的GPT系列的一个分支,ChatGPT旨在基于输入提示产生类似人类的文本。它在多种应用中显示出显著的实用性,从起草电子邮件到编写代码,甚至创造书面内容。
Large Language Models (LLMs) have been recognized as a technological breakthrough in natural language processing, such as GPT-3 and GPT-4 [Brown et al., 2020]. They take transformer-based architectures, demonstrating impressive performance across various generative tasks.
As an offshoot of the GPT family developed by OpenAI, ChatGPT was designed to produce human-like text based on input prompts. It has shown significant utility in diverse applications, from drafting emails to writing code and even in creating written content.
2.2 LLMs in Finance 金融中的大型语言模型
大型语言模型(LLMs)已被应用于金融领域内的各种任务【Dredze et al., 2016; Araci, 2019; Bao et al., 2021; DeLucia et al., 2022】,从预测建模到从原始财务数据生成有洞察力的叙述。最近的文献集中在使用这些模型进行金融文本分析,鉴于该领域存在大量的文本数据,如新闻文章、财报电话会议记录和社交媒体帖子。
金融LLMs的首个示例是BloombergGPT【Wu et al., 2023】,它训练于一个混合了财务和通用来源的数据集上。尽管其能力令人印象深刻,但存在访问限制,且高昂的训练成本激发了对低成本领域适应的需求。
我们的FinGPT响应了这些挑战,提出了一个开源的金融LLM。它采用了来自人类反馈的强化学习(RLHF)来理解和适应个人偏好,为个性化金融助手铺平了道路。我们的目标是结合通用LLMs(如ChatGPT)的优势与金融适应,利用LLM在金融方面的能力。
LLMs have been applied to various tasks within the financial sector [Dredze et al., 2016; Araci, 2019; Bao et al., 2021; DeLucia et al., 2022], from predictive modeling to generating insightful narratives from raw financial data. Recent literature has focused on using these models for financial text analysis, given the abundance of text data in this field, such as news articles, earnings call transcripts, and social media posts.
The first example of financial LLMs is BloombergGPT [Wu et al., 2023], which was trained on a mixed dataset of financial and general sources. Despite its impressive capabilities, access limitations exist, and the prohibitive training cost has motivated the need for low-cost domain adaptation.
Our FinGPT responds to these challenges, presenting an open-source financial LLM. It employs Reinforcement Learning from Human Feedback (RLHF) to understand and adapt to individual preferences, paving the way for personalized financial assistants. We aim to combine the strengths of general LLMs like ChatGPT with financial adaptation, exploiting LLM’s capability in finance.
2.3 Why Open-Source FinLLMs? 为什么要开源FinLLMs?
AI4Finance Foundation是一个非营利的开源组织,它集成了人工智能(AI)与金融应用,包括金融大型语言模型(FinLLMs)。凭借在培育FinTech工具的创新生态系统方面的成熟经验,如FinRL【Liu et al., 2021】和FinRL-Meta【Liu et al., 2022】,该基金会正准备进一步加速FinLLMs的发展。它坚定的承诺和前沿的贡献为AI在金融中的变革性应用铺平了道路。
-
通过民主化FinLLMs推进平等机会:采用开源方法促进了对最先进技术的普遍访问,坚持民主化FinLLMs的精神。
-
培养透明度和信任:开源FinLLMs提供了其基础代码库的全面概述,增强了透明度和信任。
-
加速研究和创新:开源模型在AI领域内的研究与开发进展中提供了动力。它允许研究人员利用现有模型,从而培养了创新和科学发现的更快进程。
-
提高教育质量:开源FinLLMs作为强大的教育工具,为学生和研究人员提供了通过直接参与完全操作的模型探索FinLLMs复杂性的前景。
-
促进社区发展和协作参与:开源促进了一个全球性的贡献者社区。这种协作参与增强了模型的长期耐用性和有效性。
AI4Finance Foundation is a non-profit, open-source organization that integrates Artificial Intelligence (AI) and financial applications, including financial Large Language Models (FinLLMs). With a proven track record of nurturing an innovative ecosystem of FinTech tools, such as FinRL [Liu et al., 2021] and FinRL-Meta [Liu et al., 2022], the foundation is poised to accelerate the evolution of FinLLMs further. It is steadfast commitment and cutting-edge contributions pave the way for AI’s transformative application in finance.
• Advancing equal opportunities via democratizing FinLLMs: Adopting an open-source methodology promotes universal access to state-of-the-art technology, adhering to the ethos of democratizing FinLLMs.
• Cultivating transparency and trust: Open-source FinLLMs offer a comprehensive overview of their foundational codebase, bolstering transparency and trust.
• Accelerating research and innovation: The open-source model fuels progress in research and development within the AI domain. It allows researchers to leverage existing models, thus nurturing a faster progression of innovation and scientific discovery.
• Enhancing education: Open-source FinLLMs serve as robust educational tools, presenting students and researchers with the prospect of exploring the complexities of FinLLMs through direct engagement with fully operational models.
• Promoting community development and collaborative engagement: Open-source promotes a global community of contributors. This collaborative participation bolsters the model’s long-term durability and effectiveness.
3 Data-Centric Approach for FinLLMs 面向数据的FinLLMs方法
对于金融大型语言模型(FinLLMs),成功的策略不仅仅基于模型架构的能力,同样依赖于训练数据。我们的面向数据的方法优先考虑收集、准备和处理高质量数据。
For financial large language models (FinLLMs), a successful strategy is not solely based on the capability of the model architecture but is equally reliant on the training data. Our data-centric approach prioritizes collecting, preparing, and processing high-quality data.
3.1 Financial Data and Unique Characteristics 金融数据及其独特性质
金融数据来源多样,具有独特的特性。我们深入探讨了不同金融数据来源的具体情况,如金融新闻、公司文件、社交媒体讨论和公司公告。
金融新闻携带有关世界经济、特定行业和个别公司的重要信息。这个数据源通常特征为:
-
及时性: 金融新闻报道是及时且最新的,经常捕捉到金融世界的最新发展。
-
动态性: 金融新闻中包含的信息是动态的,随着经济条件和市场情绪的演变而迅速变化。
-
影响力: 金融新闻对金融市场有显著影响,影响交易者的决策,并可能导致市场剧烈波动。
公司文件和公告是企业提交给监管机构的官方文件,提供了公司财务状况和战略方向的洞察。它们的特征包括:
-
粒度: 这些文件提供了关于公司财务状况的细粒度信息,包括资产、负债、收入和盈利能力。
-
可靠性: 公司文件包含由监管机构审核的可靠和核实的数据。
-
周期性: 公司文件是周期性的,通常按季度或年度提交,提供公司财务状况的定期快照。
-
影响力: 公司公告通常对市场有重大影响,影响股价和投资者情绪。
金融相关的社交媒体讨论可以反映公众对特定股票、部门或整个市场的情绪。这些讨论倾向于表现出:
-
差异性: 社交媒体讨论在语气、内容和质量上差异极大,使它们成为丰富但复杂的信息来源。
-
实时情绪: 这些平台经常捕捉到实时市场情绪,使得趋势和公众舆论变化的检测成为可能。
-
波动性: 在社交媒体上表达的情绪可能非常波动,对新闻事件或市场运动的反应迅速变化。
通过Seeking Alpha、Google Trends以及其他金融导向的博客和论坛可观察到的趋势,提供了市场运动和投资策略的关键洞察。它们的特征包括:
-
分析师观点: 这些平台提供了来自经验丰富的金融分析师和专家的市场预测和投资建议。
-
市场情绪: 这些平台上的论述可以反映出关于特定证券、部门或整个市场的集体情绪,提供有关当前市场情绪的宝贵洞察。
-
广泛覆盖: 趋势数据涵盖了多样化的证券和市场细分,提供全面的市场覆盖。
每一种数据源都提供了对金融世界的独特见解。通过整合这些多样化的数据类型,像FinGPT这样的金融语言模型可以促进对金融市场的全面理解,并使有效的金融决策成为可能。
Financial data comes from a variety of sources, with unique characteristics. We delve into the specifics of different financial data sources, such as Financial News, Company Fillings, Social Media Discussions, and Company Announcements.
Financial news carries vital information about the world economy, specific industries, and individual companies. This data source typically features:
• Timeliness: Financial news reports are timely and up-todate, often capturing the most recent developments in the financial world.
• Dynamism: The information contained in financial news is dynamic, changing rapidly in response to evolving economic conditions and market sentiment.
• Influence: Financial news has a significant impact on financial markets, influencing traders’ decisions and potentially leading to dramatic market movement.
Company filings and announcements are official documents that corporations submit to regulatory bodies, providing insight into a company’s financial health and strategic direction. They feature:
• Granularity: These documents offer granular information about a company’s financial status, including assets, liabilities, revenue, and profitability.
• Reliability: Company fillings contain reliable and verified data vetted by regulatory bodies.
• Periodicity: Company fillings are periodic, usually submitted on a quarterly or annual basis, offering regular snapshots of a company’s financial situation.
• Impactfulness: Company announcements often have substantial impacts on the market, influencing stock prices and investor sentiment.
Social media discussions related to finance can reflect public sentiment towards specific stocks, sectors, or the overall market. These discussions tend to exhibit:
• Variability: Social media discussions vary widely in tone, content, and quality, making them rich, albeit complex, sources of information.
• Real-time sentiment: These platforms often capture realtime market sentiment, enabling the detection of trends and shifts in public opinion.
• Volatility: Sentiments expressed on social media can be highly volatile, changing rapidly in response to news events or market movements.
Trends, often observable through websites like Seeking Alpha, Google Trends, and other finance-oriented blogs and forums, offer critical insights into market movements and investment strategies. They feature:
• Analyst perspectives: These platforms provide access to market predictions and investment advice from seasoned financial analysts and experts.
• Market sentiment: The discourse on these platforms can reflect the collective sentiment about specific securities, sectors, or the overall market, providing valuable insights into the prevailing market mood.
• Broad coverage: Trends data spans diverse securities and market segments, offering comprehensive market coverage.
Each of these data sources provides unique insights into the financial world. By integrating these diverse data types, financial language models like FinGPT can facilitate a comprehensive understanding of financial markets and enable effective financial decision-making.
3.2 Challenges in Handling Financial Data 处理金融数据的挑战
我们总结了处理金融数据的三个主要挑战如下:
-
高时间敏感性: 金融数据的特点是它们的时间敏感性。一旦发布市场影响新闻或更新,为投资者提供了一个狭窄的机会窗口来最大化他们的阿尔法(投资相对回报的度量)。
-
高动态性: 金融景观不断演变,每天都有新闻、社交媒体帖子和其他市场相关信息的涌入。频繁地重新训练模型以应对这些变化是不切实际的,且成本过高。
-
低 信噪比 ( SNR ): 金融数据通常表现出低信噪比【Liu et al., 2022】,意味着有用的信息通常被大量的无关或噪声数据所掩盖。从这海量信息中提取有价值的见解需要复杂的技术。
解决这些挑战对于有效利用金融数据和最大化FinLLMs的潜力至关重要。在我们应对这些挑战的过程中,我们提出了一个开源框架FinGPT。
We summarize three major challenges for handling financial data as follows:
• High temporal sensitivity: Financial data are characterized by their time-sensitive nature. Market-moving news or updates, once released, provide a narrow window of opportunity for investors to maximize their alpha (the measure of an investment’s relative return).
• High dynamism: The financial landscape is perpetually evolving, with a daily influx of news, social media posts, and other market-related information. It’s impractical and cost-prohibitive to retrain models frequently to cope with these changes.
• Low signal-to-noise ratio (SNR): Financial data often exhibit a low signal-to-noise ratio [Liu et al., 2022], meaning that the useful information is usually dwarfed by a substantial amount of irrelevant or noisy data. Extracting valuable insights from this sea of information necessitates sophisticated techniques.
Addressing these challenges is critical for the effective utilization of financial data and maximizing the potential of FinLLMs. As we navigate these challenges, we propose an opensource framework FinGPT.
4 Overview of FinGPT: An Open-Source Framework for FinLLMs FinGPT概览:一个针对FinLLMs的开源框架
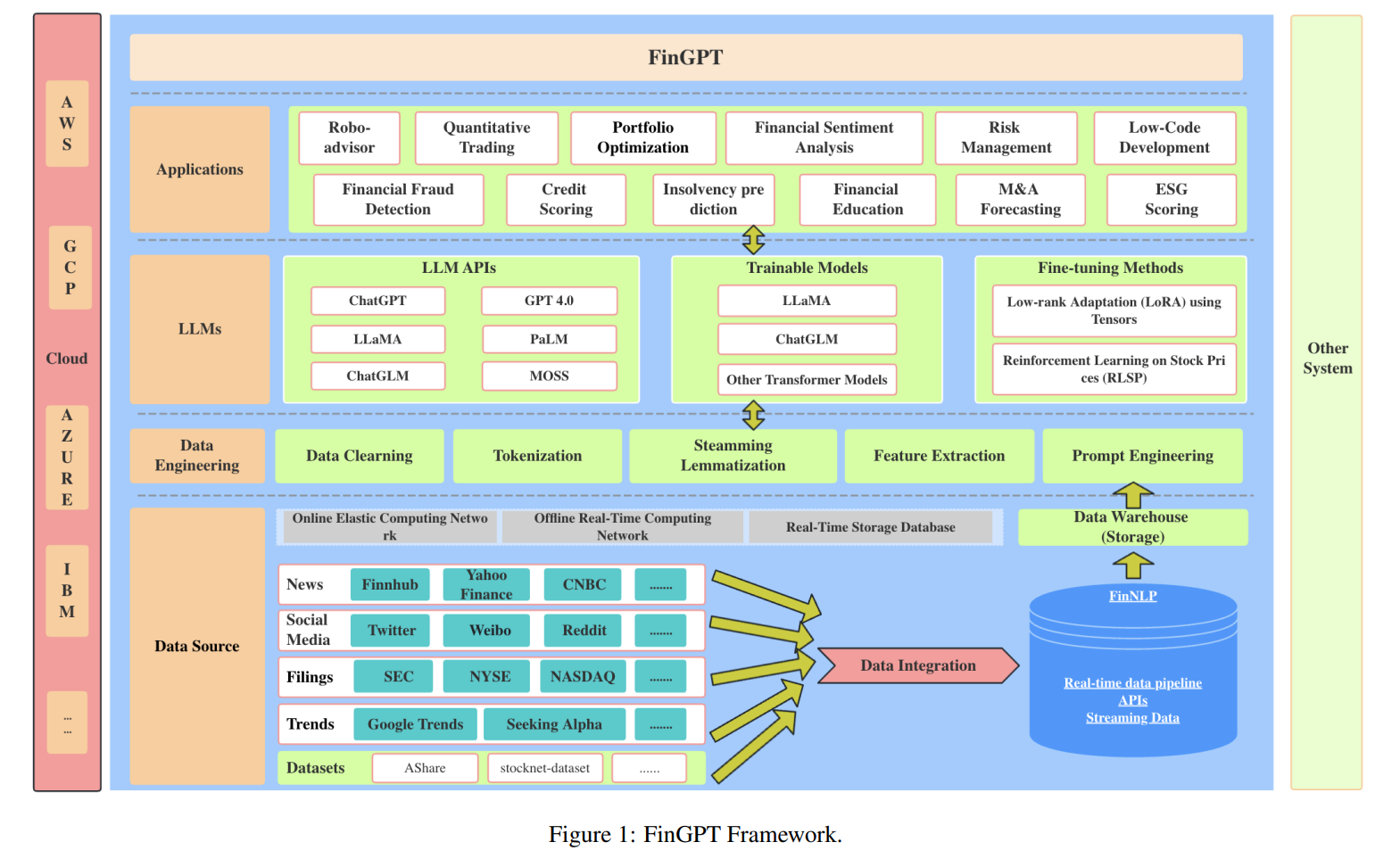
FinGPT代表了一个专为金融领域内应用大型语言模型(LLMs)而设计的创新性开源框架。如图1所示,FinGPT由四个基本组成部分构成:数据源、数据工程、LLMs和应用。这些组件中的每一个都在保持FinGPT功能和适应性方面发挥着关键作用,以应对动态的金融数据和市场条件。
-
数据源 层: FinGPT流程的起点是数据源层,该层协调从广泛的在线来源获取大量金融数据。通过整合来自新闻网站、社交媒体平台、财务报表、市场趋势等的数据,此层确保了全面的市场覆盖。其目标是捕捉市场的每一个细微差别,从而解决金融数据固有的时间敏感性问题。
-
数据工程层: 此层专注于NLP数据的实时处理,以应对金融数据固有的高时间敏感性和低信噪比的挑战。它采用最先进的NLP技术来过滤噪声并突出最重要的信息。
-
LLMs 层: 位于核心位置,它涵盖了各种微调方法,优先考虑轻量级适应性,以保持模型的更新和相关性。通过维护一个更新的模型,FinGPT能够处理金融数据的高度动态性,确保其响应与当前金融气候同步。
-
应用层: FinGPT的最终组成部分是应用层,旨在展示FinGPT的实际应用性。它提供了针对金融任务的实操教程和演示应用,包括机器人咨询服务、量化交易和低代码开发。这些实践演示不仅作为潜在用户的指南,而且强调了LLMs在金融中的变革潜力。
FinGPT represents an innovative open-source framework designed specifically for applying large language models (LLMs) within the financial domain. As delineated in Fig. 1, FinGPT consists of four fundamental components: Data Source, Data Engineering, LLMs, and Applications. Each of these components plays a crucial role in maintaining the functionality and adaptability of FinGPT in addressing dynamic financial data and market conditions.
• Data source layer: The starting point of the FinGPT pipeline is the Data Source Layer, which orchestrates the acquisition of extensive financial data from a wide array of online sources. This layer ensures comprehensive market coverage by integrating data from news websites, social media platforms, financial statements, market trends, and more. The goal is to capture every nuance of the market, thereby addressing the inherent temporal sensitivity of financial data.
• Data engineering layer: This layer focuses on the realtime processing of NLP data to tackle the challenges of high temporal sensitivity and low signal-to-noise ratio inherent in financial data. It incorporates state-of-the-art NLP techniques to filter noise and highlight the most salient pieces of information.
• LLMs layer: Lying at the heart, it encompasses various fine-tuning methodologies, with a priority on lightweight adaptation, to keep the model updated and pertinent. By maintaining an updated model, FinGPT can deal with the highly dynamic nature of financial data, ensuring its responses are in sync with the current financial climate.
• Application layer: The final component of FinGPT is the Applications Layer, designed to demonstrate the practical applicability of FinGPT. It offers hands-on tutorials and demo applications for financial tasks, including roboadvisory services, quantitative trading, and low-code development. These practical demonstrations not only serve as a guide to potential users but also underscore the transformative potential of LLMs in finance.
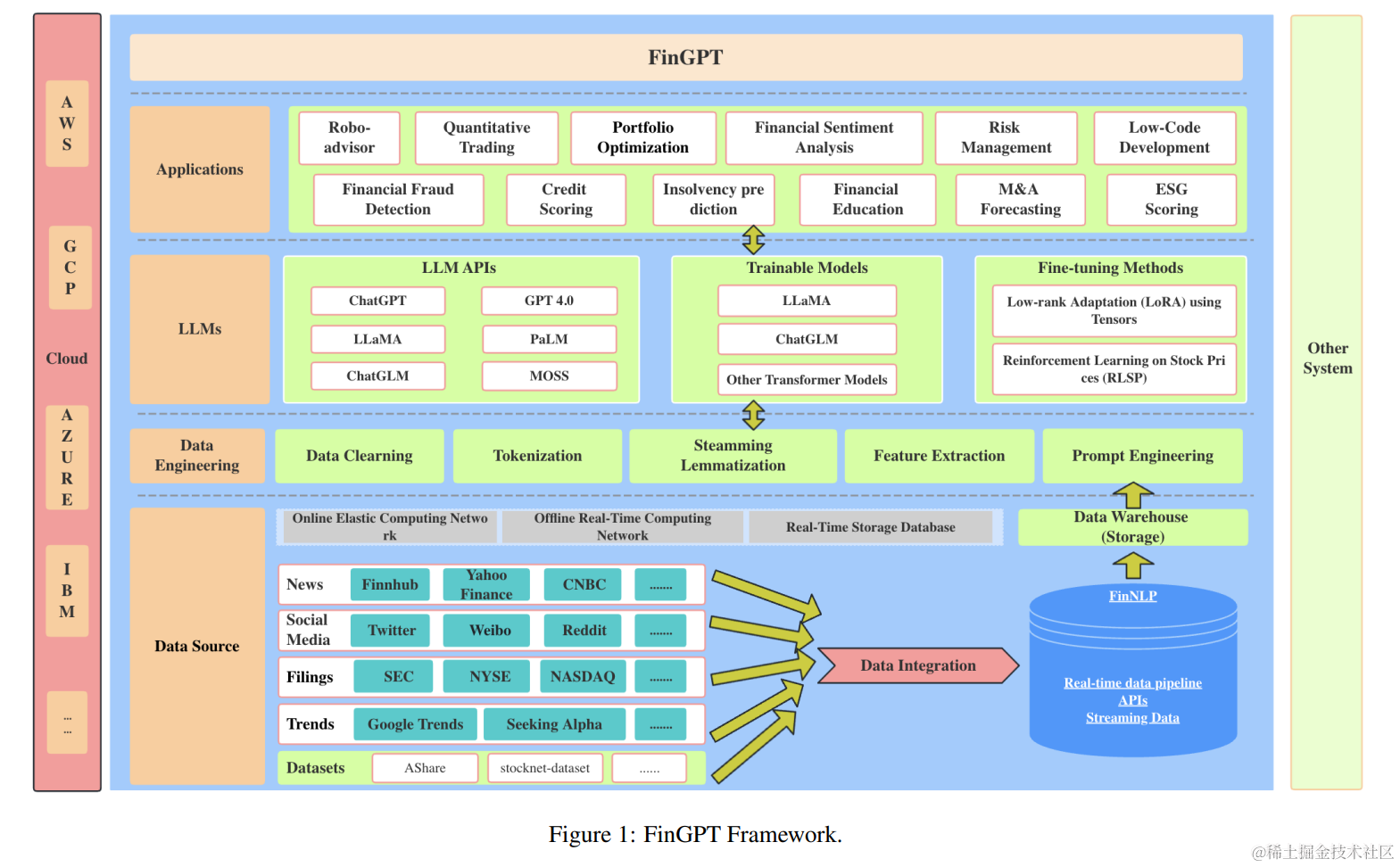
4.1 Data Sources 数据源
FinGPT流程的第一阶段涉及从广泛的在线来源收集大量金融数据。这些包括但不限于:
-
金融新闻: 如路透社、CNBC、雅虎财经等网站是获取金融新闻和市场更新的丰富来源。这些站点提供有关市场趋势、公司盈利、宏观经济指标和其他金融事件的宝贵信息。
-
社交媒体: 如Twitter、Facebook、Reddit、微博等平台提供了有关公众情绪、趋势话题和对金融新闻及事件的即时反应的丰富信息。
-
文件: 如美国证券交易委员会(SEC)等金融监管机构的网站提供了公司文件的访问。这些文件包括年度报告、季度盈利、内部交易报告和其他重要的公司特定信息。各大股票交易所(纽约证券交易所、纳斯达克、上海证券交易所等)的官方网站提供关键的股票价格、交易量、公司上市、历史数据和其他相关信息。
-
趋势: 如Seeking Alpha、Google Trends以及其他金融重点博客和论坛提供了分析师意见、市场预测、特定证券或市场细分的走向和投资建议的访问。
-
学术数据集: 提供精选和核实信息的研究基础数据集,用于复杂的金融分析。
为了利用这些多样化来源的信息丰富性,FinGPT整合了能够抓取结构化和非结构化数据的数据获取工具,包括API、网络抓取工具和直接数据库访问(在可用的情况下)。此外,系统设计遵守这些平台的服务条款,确保数据收集是合乎伦理和法律的。
数据API: 在FinGPT框架中,API不仅用于初始数据收集,还用于实时数据更新,确保模型训练基于最新数据。此外,实施错误处理和速率限制策略,以尊重API使用限制并避免数据流中断。
The first stage of the FinGPT pipeline involves the collection of extensive financial data from a wide array of online sources. These include, but are not limited to:
• Financial news: Websites such as Reuters, CNBC, Yahoo Finance, among others, are rich sources of financial news and market updates. These sites provide valuable information on market trends, company earnings, macroeconomic indicators, and other financial events.
• Social media: Platforms such as Twitter, Facebook, Reddit, Weibo, and others, offer a wealth of information in terms of public sentiment, trending topics, and immediate reactions to financial news and events.
• Filings: Websites of financial regulatory authorities, such as the SEC in the United States, offer access to company filings. These filings include annual reports, quarterly earnings, insider trading reports, and other important companyspecific information. Official websites of stock exchanges (NYSE, NASDAQ, Shanghai Stock Exchange, etc.) provide crucial data on stock prices, trading volumes, company listings, historical data, and other related information.
• Trends: Websites like Seeking Alpha, Google Trends, and other finance-focused blogs and forums provide access to analysts’ opinions, market predictions, the movement of specific securities or market segments and investment advice.
• Academic datasets: Research-based datasets that offer curated and verified information for sophisticated financial analysis. To harness the wealth of information from these diverse sources, FinGPT incorporates data acquisition tools capable of scraping structured and unstructured data, including APIs, web scraping tools, and direct database access where available. Moreover, the system is designed to respect the terms of service of these platforms, ensuring data collection is ethical and legal.
Data APIs: In the FinGPT framework, APIs are used not only for initial data collection but also for real-time data updates, ensuring the model is trained on the most current data. Additionally, error handling and rate-limiting strategies are implemented to respect API usage limits and avoid disruptions in the data flow.
4.2 Real-Time Data Engineering Pipeline for Financial NLP 面向金融NLP的实时数据工程管道
金融市场实时运行,并对新闻和情绪高度敏感。证券价格可以迅速响应新信息变化,处理这些信息的延迟可能导致错失机会或增加风险。因此,实时处理在金融NLP中至关重要。
实时NLP管道的主要挑战是高效管理和处理持续流入的数据。管道的第一步是建立一个系统来实时摄取数据。这些数据可能来自我们的数据源API。以下是设计实时NLP管道进行数据摄取的步骤。
数据清洗: 实时数据可能是嘈杂且不一致的。因此,实时数据清洗包括移除不相关数据、处理缺失值、文本规范化(如小写化)和错误更正。
分词: 在实时应用中,需要即时进行分词。这涉及将文本流分解成较小的单位或令牌。
停用词移除和词干提取/词形还原: 对于实时处理,可以使用预定义的停用词列表从令牌流中过滤掉这些常见词。同样,可以应用词干提取和词形还原技术,将词汇还原到它们的词根形式。
特征提取和 情感分析 : 特征提取涉及将原始数据转换为机器学习模型可以理解的输入。在实时系统中,这通常需要是一个快速且高效的过程。可以使用TF-IDF、词袋模型或如Word2Vec的嵌入向量等技术。也可以对清洗后的数据进行情感分析。这里我们将文本范围分类为积极、消极或中性。
提示工程: 创建有效的提示,可以引导语言模型的生成过程朝向期望的输出。
警报/决策制定: 一旦输入提示,就需要通报或采取行动。这可能涉及基于某些条件触发警报,通知实时决策过程,或将输出馈送到另一个系统。
持续学习: 在实时系统中,模型应适应数据的变化。可以实现持续学习系统,其中模型定期在新数据上重新训练,或使用在线学习算法,这些算法可以用每个新数据点更新模型。
监控: 实时系统需要持续监控以确保它们正确运行。管道中的任何延迟或问题都会立即产生影响,因此重要的是要有强大的监控和警报系统。
Financial markets operate in real-time and are highly sensitive to news and sentiment. Prices of securities can change rapidly in response to new information, and delays in processing that information can result in missed opportunities or increased risk. As a result, real-time processing is essential in financial NLP.
The primary challenge with a real-time NLP pipeline is managing and processing the continuous inflow of data efficiently. The first step in the pipeline is to set up a system to ingest data in real-time. This data could be streaming from our data source APIs. Below are the steps to design a realtime NLP pipeline for data ingestion. Data cleaning: Real-time data can be noisy and inconsistent. Therefore, real-time data cleaning involves removing irrelevant data, handling missing values, text normalization (like lowercasing), and error corrections. Tokenization: In real-time applications, tokenization has to be performed on the fly. This involves breaking down the stream of text into smaller units or tokens.
Stop word removal and stemming/lemmatization: For real-time processing, a predefined list of stop words can be used to filter out these common words from the stream of tokens. Likewise, stemming and lemmatization techniques can be applied to reduce words to their root form.
Feature extraction and sentiment analysis : Feature extraction involves transforming raw data into an input that can be understood by machine learning models. In real-time systems, this often needs to be a fast and efficient process. Techniques such as TF-IDF, Bag of Words, or embedding vectors like Word2Vec can be used. Sentiment analysis can also be performed on the cleaned data. This is where we categorize a span of text as positive, negative, or neutral.
Prompt engineering: The creation of effective prompts that can guide the language model’s generation process toward desirable outputs.
Alerts/Decision making: Once the prompt is entered, the results need to be communicated or acted upon. This might involve triggering alerts based on certain conditions, informing real-time decision-making processes, or feeding the output into another system.
Continuous learning: In real-time systems, the models should adapt to changes in the data. Continuous learning systems can be implemented, where models are periodically retrained on new data or online learning algorithms are used that can update the model with each new data point.
Monitoring: Real-time systems require continuous monitoring to ensure they are functioning correctly. Any delays or issues in the pipeline can have immediate impacts, so it’s important to have robust monitoring and alerting in place.
4.3 Large Language Models (LLMs) 大型语言模型(LLMs)
一旦数据得到适当准备,就使用LLMs进行深入的金融分析。LLM层包括:
-
LLM APIs: 来自成熟LLM的APIs提供基线语言能力。
-
可训练模型: FinGPT提供可训练模型,用户可以在他们的私有数据上进行微调,为金融应用定制。
-
微调方法: 各种微调方法允许FinGPT适应个性化的机器人顾问。
Once the data has been properly prepared, it is used with LLMs to generate insightful financial analyses. The LLM layer includes:
• LLM APIs: APIs from established LLMs provide baseline language capability.
• Trainable models: FinGPT provides trainable models that users can fine-tune on their private data, customizing for financial applications.
• Fine-tuning methods: Various fine-tuning methods allow FinGPT to be adapted to personalized robo-advisor.
Why fine-tune LLMs instead of retraining from scratch?
为什么选择微调 LLMs 而不是从头开始训练?
利用现有的大型语言模型(LLMs)并为金融进行微调提供了一种有效、成本效益高的替代方案,相比于从头开始昂贵且耗时的模型重新训练。
BloombergGPT虽然在金融特定能力方面表现卓越,但需要大量的计算资源。它的训练大约使用了130万GPU小时,按AWS云的2.3美元费率计算,每次训练的成本高达约300万美元。与BloombergGPT等模型的高计算成本相比,FinGPT通过专注于顶级开源LLM的轻量级适配,呈现出更易于获取的解决方案。适配成本大大降低,估计不到每次训练300美元。
这种方法确保了及时更新和适应性,这在动态的金融领域至关重要。作为开源,FinGPT不仅促进了透明度,而且允许用户定制,迎合了个性化金融咨询服务的上升趋势。最终,FinGPT的成本效益高、灵活的框架具有民主化金融语言建模和促进以用户为中心的金融服务的潜力。
Leveraging pre-existing Large Language Models (LLMs) and fine-tuning them for finance provides an efficient, costeffective alternative to expensive and lengthy model retraining from scratch.
BloombergGPT, though remarkable in its finance-specific capabilities, comes with an intensive computational requirement. It used approximately 1.3 million GPU hours for training, which, when calculated using AWS cloud’s 3 million per training. In contrast to the high computational cost of models like BloombergGPT, FinGPT presents a more accessible solution by focusing on the lightweight adaptation of top open-source LLMs. The cost of adaptation falls significantly, estimated at less than $300 per training.
This approach ensures timely updates and adaptability, essential in the dynamic financial domain. Being open-source, FinGPT not only promotes transparency but also allows user customization, catering to the rising trend of personalized financial advisory services. Ultimately, FinGPT’s costeffective, flexible framework holds the potential to democratize financial language modeling and foster user-focused financial services.
Fine-tuning via Low-rank Adaptation ( LoRA )
通过低秩适应(LoRA)进行微调
在FinGPT中,我们利用一个新颖的金融数据集对预训练的LLM进行微调。众所周知,高质量的标记数据是许多成功LLM,包括ChatGPT,的关键决定因素。然而,获取这样顶级的标记数据在时间和资源上往往证明是昂贵的,并且通常需要金融专业人士的专业知识。
如果我们的目标是使用LLM分析与金融相关的文本数据并协助量化交易,利用市场的内在标记能力似乎是明智的。因此,我们使用每条新闻项目的相对股价变化百分比作为输出标签。我们设立阈值,根据新闻项目的情感将这些标签划分为三类——正面、负面和中性。
在相应的步骤中,在提示工程过程中,我们还提示模型从正面、负面和中性输出中选择一个。这一策略确保了对预训练信息的最优利用。通过部署LLM的低秩适应(LoRA)【Hu et al., 2021; Dettmers et al., 2023】,我们设法将可训练参数的数量从61.7亿减少到仅367万。
In FinGPT, we fine-tune to a pre-trained LLM utilizing a novel financial dataset. It’s well recognized that high-quality labeled data is a pivotal determinant for many successful LLMs, including ChatGPT. However, acquiring such topnotch labeled data often proves costly in terms of time and resources and generally requires the expertise of finance professionals.
If our objective is to employ LLMs for analyzing financialrelated text data and assisting in quantitative trading, it seems sensible to leverage the market’s inherent labeling capacity. Consequently, we use the relative stock price change percentage for each news item as the output label. We establish thresholds to divide these labels into three categories—positive, negative, and neutral—based on the sentiment of the news item.
In a corresponding step, during the prompt engineering process, we also prompt the model to select one from the positive, negative, and neutral outputs. This strategy ensures optimal utilization of the pre-trained information. By deploying the Low-Rank Adaptation (LoRA) of LLMs [Hu et al., 2021; Dettmers et al., 2023], we manage to reduce the number of trainable parameters from 6.17 billion to a mere 3.67 million.
Fine-tuning via Reinforcement Learning on Stock Prices (RLSP)
通过基于股价的强化学习(RLSP)进行微调
同样,我们可以用基于股价的强化学习(RLSP)来代替ChatGPT所利用的基于人类反馈的强化学习。这种替代的理由是股价提供了一个可量化、客观的指标,反映了市场对新闻和事件的情绪反应。这使其成为训练我们模型的强大、实时反馈机制。
强化学习(RL)允许模型通过与环境的互动和接收反馈来学习。在RLSP的情况下,环境是股票市场,反馈以股价变化的形式出现。这种方法允许FinGPT细化其对金融文本的理解和解释,提高其预测各种金融事件对市场反应的能力。
通过将新闻情绪与相关股票的后续表现关联起来,RLSP提供了一种有效的微调FinGPT的方式。本质上,RLSP允许模型推断市场对不同新闻事件的反应,并据此调整其理解和预测。
因此,将RLSP整合到FinGPT的微调过程中,为提高模型的金融市场理解和预测准确性提供了强大的工具。通过使用实际股价变动作为反馈,我们直接利用了市场的智慧,使我们的模型更加有效。
Similarly, we can substitute Reinforcement Learning on Stock Prices (RLSP) for Reinforcement Learning on Human feedback, as utilized by ChatGPT. The reasoning behind this substitution is that stock prices offer a quantifiable, objective metric that reflects market sentiment in response to news and events. This makes it a robust, real-time feedback mechanism for training our model.
Reinforcement Learning (RL) allows the model to learn through interaction with the environment and receiving feedback. In the case of RLSP, the environment is the stock market, and the feedback comes in the form of stock price changes. This approach permits FinGPT to refine its understanding and interpretation of financial texts, improving its ability to predict market responses to various financial events.
By associating news sentiment with the subsequent performance of the related stocks, RLSP provides an effective way to fine-tune FinGPT. In essence, RLSP allows the model to infer the market’s response to different news events and adjust its understanding and predictions accordingly.
Therefore, the integration of RLSP into the fine-tuning process of FinGPT provides a powerful tool for improving the model’s financial market understanding and predictive accuracy. By using actual stock price movements as feedback, we are directly harnessing the wisdom of the market to make our model more effective.
4.4 Applications 应用
FinGPT在金融服务领域可能有广泛的应用,帮助专业人士和个人做出明智的金融决策。潜在的应用包括:
-
机器人顾问:提供个性化的财务建议,减少定期面对面咨询的需求。
-
量化交易:为明智的交易决策产生交易信号。
-
投资组合优化:利用众多经济指标和投资者档案构建最佳投资组合。
-
金融情绪分析:评估不同金融平台的情绪,以提供有洞察力的投资指导。
-
风险管理:通过分析各种风险因素来制定有效的风险策略。
-
金融欺诈检测:识别潜在的欺诈交易模式,增强金融安全。
-
信用评分:从财务数据预测信用价值,以帮助贷款决策。
-
破产预测:基于财务和市场数据预测公司潜在的破产或倒闭。
-
并购(M&A)预测:通过分析财务数据和公司档案预测潜在的并购活动,帮助投资者预测市场动向。
-
ESG(环境、社会、治理)评分:通过分析公共报告和新闻文章来评估公司的ESG得分。
-
低代码开发:通过用户友好的界面促进软件创建,减少对传统编程的依赖。
-
金融教育:作为AI导师简化复杂的金融概念,提高金融素养。
通过连接这些独特而相互关联的组件,FinGPT为在金融领域利用AI提供了一个全面且易于获取的解决方案,促进了金融行业的研究、创新和实际应用。
FinGPT may find wide applications in financial services, aiding professionals and individuals in making informed financial decisions. The potential applications include:
• Robo-advisor: Offering personalized financial advice, reducing the need for regular in-person consultations.
• Quantitative trading: Producing trading signals for informed trading decisions.
• Portfolio optimization: Utilizing numerous economic indicators and investor profiles for optimal investment portfolio construction.
• Financial sentiment analysis: Evaluating sentiments across different financial platforms for insightful investment guidance.
• Risk management: Formulating effective risk strategies by analyzing various risk factors.
• Financial Fraud detection: Identifying potential fraudulent transaction patterns for enhanced financial security.
• Credit scoring: Predicting creditworthiness from financial data to aid lending decisions.
• Insolvency prediction: Predicting potential insolvency or bankruptcy of companies based on financial and market data.
• Mergers and acquisitions (M&A) forecasting: Predicting potential M&A activities by analyzing financial data and company profiles, helping investors anticipate market movements.
• ESG (Environmental, Social, Governance) scoring: Evaluating companies’ ESG scores by analyzing public reports and news articles.
• Low-code development: Facilitating software creation through user-friendly interfaces, reducing reliance on traditional programming.
• Financial education: Serving as an AI tutor simplifying complex financial concepts for better financial literacy.
By linking these distinct yet interconnected components, FinGPT provides a holistic and accessible solution for leveraging AI in finance, facilitating research, innovation, and practical applications in the financial industry.
5 Conclusion 结论
总之,大型语言模型(LLMs)与金融行业的变革性整合带来了独特的复杂性和广阔的机会。面对高时间敏感性、动态的金融环境以及金融数据中低信噪比的挑战,需要高效的解决方案。FinGPT通过利用现有的LLMs并将它们微调至特定金融应用,以创新的方式响应这些挑战。与BloombergGPT等模型相比,这种方法显著降低了适应成本和计算要求,提供了一个更易于获取、灵活且成本效益高的金融语言建模解决方案。因此,它使模型能够持续更新以确保准确性和相关性,这在动态且对时间敏感的金融世界中是一个关键方面。
In conclusion, the transformative integration of large language models (LLMs) into the financial sector brings unique complexities and vast opportunities. Navigating challenges such as high temporal sensitivity, dynamic financial landscape, and a low signal-to-noise ratio in financial data calls for efficient solutions. FinGPT responds innovatively by leveraging pre-existing LLMs and fine-tuning them to specific financial applications. This approach significantly reduces adaptation costs and computational requirements compared to models like BloombergGPT, offering a more accessible, flexible, and cost-effective solution for financial language modeling. Thus, it enables consistent updates to ensure model accuracy and relevance, a critical aspect in the dynamic and time-sensitive world of finance.
6 Future Work 未来工作
金融大型语言模型(FinLLMs)展现了一个未来愿景,在这个愿景中,个性化的机器人顾问或助手触手可及。它旨在民主化获取高质量金融建议的途径,利用先进的语言建模技术解读大量金融数据,并将其转化为可行的洞察。以下蓝图勾勒了FinLLM的未来方向。
-
个性化:FinLLM策略的核心是个性化微调的概念。使用如LoRA和QLoRA等技术,FinLLM使用户能够根据自己的特定需求定制模型,从而创建个人机器人顾问或助手。这与金融服务中向定制化趋势相符,消费者日益要求获得与其独特风险概况和财务目标相符的个性化建议。
-
开源和低成本适应:FinLLM提倡开源价值观,为用户提供以低成本(通常在100到300美元之间)将大型语言模型(LLMs)适应到自己需求的工具。这不仅使得高级金融建模技术的获取民主化,而且还促进了开发者和研究人员的活跃社区的形成,共同推动金融AI领域可能性的边界。
-
获取高质量金融数据的通道:FinLLM不仅提供建模技术,还提供获取高质量金融数据的通道。这确保用户有他们需要的数据来有效地训练他们的模型,同时也简化了数据策展过程。通过提供带演示的数据策展管道,进一步加强了对数据的访问,使用户能够充分利用其金融数据的潜力。
免责声明:我们出于教育目的共享代码,遵循MIT教育许可。此处内容不构成财务建议,也不是进行实际交易的推荐。在交易或投资前,请务必运用常识,并始终先咨询专业人士。
FinLLMs, or Financial Large Language Models, present a vision of the future where personalized robo-advisors or assistants are within everyone’s reach. It aims to democratize access to high-quality financial advice, leveraging advanced language modeling techniques to make sense of vast amounts of financial data and transform it into actionable insights. The following blueprint outlines the future direction of FinLLM.
• Individualization: At the heart of FinLLM’s strategy is the concept of individualized fine-tuning. Using techniques such as LoRA and QLoRA, FinLLM enables users to tailor models to their specific needs, thereby creating a personal robo-advisor or assistant. This aligns with a broader trend towards customization in financial services, as consumers increasingly demand personalized advice that aligns with their unique risk profiles and financial goals.
• Open-source and low-cost adaptation: FinLLM champions open-source values, providing users with the tools they need to adapt Large Language Models (LLMs) to their own requirements at a low cost, typically between 300. This not only democratizes access to advanced financial modeling techniques but also fosters a vibrant community of developers and researchers, collectively pushing the boundaries of what’s possible in the field of financial AI.
• Access to high-quality financial data: FinLLM goes beyond just providing modeling techniques, also offering access to high-quality financial data. This ensures that users have the data they need to train their models effectively, while also simplifying the data curation process. This access is further enhanced by the provision of a data curation pipeline with demos, empowering users to harness the full potential of their financial data.
Disclaimer: We are sharing codes for academic purposes under the MIT education license. Nothing herein is financial advice, and NOT a recommendation to trade real money. Please use common sense and always first consult a professional before trading or investing.
References
[Araci, 2019] Dogu Araci. Finbert: Financial sentiment analysis with pre-trained language models. arXiv preprint arXiv:1908.10063, 2019.
[Bao et al., 2021] Siqi Bao, Huang He, Fan Wang, Hua Wu, Haifeng Wang, Wenquan Wu, Zhihua Wu, Zhen Guo, Hua Lu, Xinxian Huang, et al. Plato-xl: Exploring the largescale pre-training of dialogue generation. arXiv preprint arXiv:2109.09519, 2021.
[Brown et al., 2020] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in Neural Information Processing Systems, 33:1877–1901, 2020.
[DeLucia et al., 2022] Alexandra DeLucia, Shijie Wu, Aaron Mueller, Carlos Aguirre, Philip Resnik, and Mark Dredze. Bernice: a multilingual pre-trained encoder for twitter. In Proceedings of the 2022 conference on empirical methods in natural language processing, pages 6191–6205, 2022.
[Dettmers et al., 2023] Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. QLoRA: Efficient finetuning of quantized llms. arXiv preprint arXiv:2305.14314, 2023.
[Devlin et al., 2018] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
[Dredze et al., 2016] Mark Dredze, Prabhanjan Kambadur, Gary Kazantsev, Gideon Mann, and Miles Osborne. How twitter is changing the nature of financial news discovery. In proceedings of the second international workshop on data science for macro-modeling, pages 1–5, 2016.
[Ethayarajh, 2019] Kawin Ethayarajh. How contextual are contextualized word representations? comparing the geometry of bert, elmo, and gpt-2 embeddings. arXiv preprint arXiv:1909.00512, 2019.
[Hu et al., 2021] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. International Conference on Learning Representations, 2021.
[Lewis et al., 2019] Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, and Luke Zettlemoyer. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461, 2019.
[Lewis et al., 2020] Patrick Lewis, Myle Ott, Jingfei Du, and Veselin Stoyanov. Pretrained language models for biomedical and clinical tasks: understanding and extending the state-of-the-art. In Proceedings of the 3rd Clinical Natural Language Processing Workshop, pages 146–157, 2020.
[Liu et al., 2021] Xiao-Yang Liu, Hongyang Yang, Jiechao Gao, and Christina Dan Wang. FinRL: Deep reinforcement learning framework to automate trading in quantitative finance. ACM International Conference on AI in Finance (ICAIF), 2021.
[Liu et al., 2022] Xiao-Yang Liu, Ziyi Xia, Jingyang Rui, Jiechao Gao, Hongyang Yang, Ming Zhu, Christina Dan Wang, Zhaoran Wang, and Jian Guo. FinRL-Meta: Market environments and benchmarks for data-driven financial reinforcement learning. NeurIPS, 2022.
[Radford et al., 2018] Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. Improving language understanding by generative pre-training. OpenAI, 2018.
[Thoppilan et al., 2022] Romal Thoppilan, Daniel De Freitas, Jamie Hall, Noam Shazeer, Apoorv Kulshreshtha, Heng-Tze Cheng, Alicia Jin, Taylor Bos, Leslie Baker, Yu Du, et al. Lamda: Language models for dialog applications. arXiv preprint arXiv:2201.08239, 2022.
[Vaswani et al., 2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017.
[Wu et al., 2023] Shijie Wu, Ozan Irsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prabhanjan Kambadur, David Rosenberg, and Gideon Mann. BloombergGPT: A large language model for finance. arXiv preprint arXiv:2303.17564, 2023.

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)