
购物篮分析的数据分层案例解析----(以R语言案例包的Groceries数据集为例)
Groceries数据集来自一个现实中真实存在的欧洲超市,是其经营一个月的购物篮数据,共包含9835次交易,由169个商品完成销售,按照一个月30天计算,该超市每天平均为328笔交易,根据Groceries数据集的交易笔数、商品品类构成,应该是一家社区型小型食品超市。下表来自于一个真实南方超市的交易数据,表中共有8个购物篮,购物篮中商品是真实超市售卖的商品,该超市经营面积大致在1500平米,属于标
我们以R语言的Apriori算例库中,arules包中自带的Groceries数据集为例,介绍购物篮分析的数据分层方法。
Groceries数据集来自一个现实中真实存在的欧洲超市,是其经营一个月的购物篮数据,共包含9835次交易,由169个商品完成销售,按照一个月30天计算,该超市每天平均为328笔交易,根据Groceries数据集的交易笔数、商品品类构成,应该是一家社区型小型食品超市。
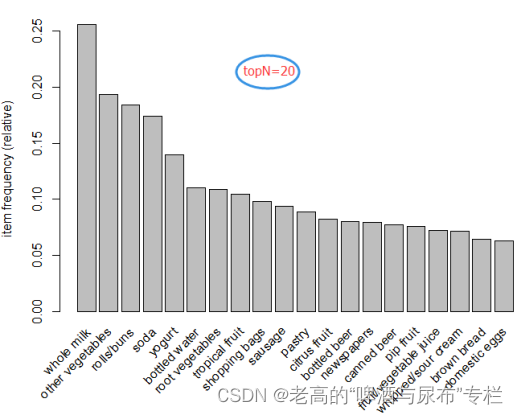
从Groceries数据集提供的TOP 20商品销售列表(见下图)可以看出,前20个出现次数最多的商品都是食品,销售排行依次为全脂牛奶、蔬菜、面包、苏打水、酸奶等,也印证了这是一家小型食品超市。
Groceries数据集中Top 20商品购买频率
在现有的关联分析算例数据集中,Groceries数据集是目前所见最完整、最真实、且最大规模的购物篮数据,Groceries数据集代表了学术界心中的真实超市购物篮,是学习Apriori算法的最佳入门级数据集。
需要注意的是,Groceries数据集是经过整理后的超市购物篮数据 ,需要在此对Groceries数据集进行详细说明一下,否则会误导学习购物篮分析的新手。
下表是从Groceries数据集中提取的11个购物篮数据,Items是购物篮中的商品,如citrus fruit(柑橘类水果),semi-finished bread(半成品面包),margarine(人造奶油),ready soups(成品汤)等。
初次看Groceries数据集,感觉超市的真实购物篮数据就应该这样,但当有了真实的超市购物篮分析经验后,会发现Groceries购物篮数据中暗藏的陷阱。
一家每天可以卖到300多笔交易的超市,怎么可以只靠169个商品完成的?
一家7-11便利店,每天的800-1000笔交易,是靠2000-3000个商品完成的。
如果仔细研究一下下表购物篮数据中的商品名称(Items)后,会恍然大悟:原来Groceries数据集的商品项目做了品类升级处理!

表 Groceries购物篮商品列表
比如第一个购物篮中的有citrus fruit(柑橘类水果),semi-finished bread(半成品面包),margarine(人造奶油),ready soups(成品汤类)四个商品,其实都不是具体商品,而是上升到了上一级商品品类。
citrus fruit(柑橘类水果)是一个品类,这个品类可能有3-5个商品,对应了3-5个不同售价的柑橘类水果。
semi-finished bread(半成品面包),margarine(人造奶油),ready soups(成品汤)不是三个商品,而是各自对应了5-10种半成品面包、人造奶油、成品汤等商品单品,是三个品类的名称。
因此Groceries数据集中的169个商品是商品的细分品类,应该对应了1000-2000个具体的真实商品。
Groceries数据集将1000-2000个商品简化为169个商品品类,购物篮中的商品做了品类升级处理,简化了商品的品类层级维度,聚焦到商品品类,便于学习数据挖掘算法,简化购物篮分析的入门难度。
但在现实中,可以看到大量超市购物篮分析的案例,都是直接把超市的购物篮数据拿过来,直接上手分析,这样会带来很多问题。
下表来自于一个真实南方超市的交易数据,表中共有8个购物篮,购物篮中商品是真实超市售卖的商品,该超市经营面积大致在1500平米,属于标准超市,主营商品以生鲜为主,经营商品在5000个左右,每天交易笔数在2000-2500笔左右。

某超市购物篮的商品项集
上表省略了商品编码、包装规格、销售价格、销售金额等项目,商品名称采取了简写,便于打印在收银小票上,而商品名称不代表商品的唯一性,如二个商品名称都是东北大米,包装规格都是5公斤,但是销售价格不一致,因此是二个商品。
如果把上面的购物篮数据直接进行分析,会就掉进关联分析的层级陷阱中。
这是因为真实购物篮中的商品层级太低了,直接拿某一个具体的猪前腿作为分析对象,关联商品就会混杂在几千个购物篮中,即使找到了关联商品,商品之间关联指标也会被稀释,淹没在庞大的购物篮数据中。
如果进行品类升层处理,如同上面的Groceries数据集一样,将几千个商品升级为100-200个商品品类(小品类),这样构成的购物篮数据才有可能方便地挖掘出商品之间的关联关系。
因此在对上述的购物篮数据进行分析时,可以将东北大米升级为大米品类,其他商品也同样上升一级品类,比如分别升级为糖、蔬菜、鸡蛋、猪肉等,这样可以使得关联规则更加聚焦。

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)