
跟着开源项目学因果推断——causalnex(十三)
文章目录1 causalnex 介绍1.1 安装2 使用的模型1 causalnex 介绍1.1 安装pip install causalnexgithub:https://github.com/quantumblacklabs/causalnex文档链接:https://causalnex.readthedocs.io/en/latest/02_getting_started/02_instal

1 causalnex 介绍
是基于因果图的延申,
Pearl and Mackenzie 提出了SCM结构因果模型,将因果推理过程流程化,他们把SCM分为三部分,
- 第一部分就是确定图模型(DAG)
- 第二部分结构化方程,这里通过NOTEARS确定了图结构
- 第三部分是反事实和介入逻辑,第三部分我也可以称它假设性逻辑。这里通过贝叶斯网络进行介入与反事实推理
1.1 安装
pip install causalnex
github:https://github.com/quantumblacklabs/causalnex
文档链接:https://causalnex.readthedocs.io/en/latest/02_getting_started/02_install.html
CausalNex是一个Python库,使用贝叶斯网络将机器学习和领域专业知识结合起来进行因果推理。
您可以使用CausalNex来揭示数据中的结构关系,了解复杂的分布,并观察潜在干预的效果。
CausalNex库有以下特点:
- 采用最先进的结构学习方法,DAG with NO TEARS,理解变量之间的条件依赖关系
- 允许领域知识扩展模型关系
- 建立基于结构关系的预测模型
- 理解概率模型
- 用标准的统计检查评估模型质量
- 可视化简化了因果关系的理解
- 使用微积分分析干预措施的影响
与建立在模式识别和相关性分析基础上的传统机器学习方法相比,利用贝叶斯网络更直观地描述因果关系。
如果能够在图模型中轻松地编码或增加领域专业知识,那么因果关系就会更加准确。
然后,可以使用图表模型来评估变化对潜在特征的影响,即反事实分析,并确定正确的干预。
根据经验,数据科学家通常必须使用至少3-4个不同的开源库,才能到达找到正确干预的最后一步。CausalNex旨在简化因果关系和反事实分析的端到端过程。
2 使用的模型
2.1 NOTEARS的结构方程模型
该开源的库模型有参考NOTEARS的模型:DAGs with NO TEARS: Continuous Optimization for Structure Learning
论文中几个笔者认为的亮点:
- 论文中将DAG学习的无环结构约束由传统的组合约束(离散,无环结构呈几何倍数增长)改进为了一种smooth的连续约束( h ( w ) h(w) h(w) )


F(W)是得分函数, DAG_GNN是另外一款升级模型,会在这个
h
(
w
)
h(w)
h(w) 进行升级;
- h ( w ) h(w) h(w)之后,定义的结构方程模型(structural equation model,SEM)对 X 进行建模,其重点在于寻找一个能使最小二乘(least-squares,LS)损失最小的SEM。
3 建模案例:NOTEARS结构方程模型
3.1 数据加载
案例来源:Structure-Learning
import pandas as pd
data = pd.read_csv('student-por.csv', delimiter=';')
data.head(5)
# 数据加工一下
drop_col = ['school','sex','age','Mjob', 'Fjob','reason','guardian']
data = data.drop(columns=drop_col)
data.head(5)
import numpy as np
struct_data = data.copy()
non_numeric_columns = list(struct_data.select_dtypes(exclude=[np.number]).columns)
# 数据文本 -> 数值化
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
for col in non_numeric_columns:
struct_data[col] = le.fit_transform(struct_data[col])
struct_data.head(5)
加载数据,并对数据进行一些数值化操作之后,接下来建模:
from causalnex.structure.notears import from_pandas
sm = from_pandas(struct_data)

这里可以看到每个变量之间都是互连的,是因为没有任何专家指定,也没有任何筛选边的操作,所以都显示;
那么另一种,可以使用remove_edges_below_threshold设定一些阈值进行删除:
sm.remove_edges_below_threshold(0.8)
viz = plot_structure(
sm,
graph_attributes={"scale": "0.5"},
all_node_attributes=NODE_STYLE.WEAK,
all_edge_attributes=EDGE_STYLE.WEAK,
)
Image(viz.draw(format='png'))
删除了边系数阈值小于0.8的,就会出现现在的图:

结果解读:
- 家庭地位 P s t a t u s Pstatus Pstatus 影响家庭关系 f a m r e l famrel famrel——如果父母分居,家庭关系的质量可能会因此而变差。
- 网络 i n t e r n e t internet internet 影响缺勤 a b s e n c e s absences absences——家里有网络可能会导致学生逃课。
- 学习时间长 s t u d y t i m e studytime studytime 对学生的成绩 G 1 G1 G1有积极的影响。
3.2 建模 & 错误指向时需要可以进行的操作
3.2.1 错误指向解决一:新增约束
当然,这里也有可能是错误的指向:
孩子的高等教育
h
i
g
h
e
r
higher
higher 会 影响
M
e
d
u
Medu
Medu (母亲的教育)——这种关系没有意义,因为想要追求高等教育的学生不会影响母亲的教育。
针对这种错误的指向,可以建模的时候加入一些约束条件:
sm = from_pandas(struct_data, tabu_edges=[("higher", "Medu")], w_threshold=0.8)
viz = plot_structure(
sm,
graph_attributes={"scale": "0.5"},
all_node_attributes=NODE_STYLE.WEAK,
all_edge_attributes=EDGE_STYLE.WEAK,
)
Image(viz.draw(format='png'))

3.2.2 错误指向解决二:直接微调结果
新增 / 删除边
sm.add_edge("failures", "G1")
sm.remove_edge("Pstatus", "G1")
sm.remove_edge("address", "G1")

3.3 检索最大子图
我们可以看到在可视化图中有两个独立的子图:Dalc -> Walc和另一个大的子图。
我们可以通过调用StructureModel函数get_largest_subgraph()轻松地检索最大的子图。
sm = sm.get_largest_subgraph()
viz = plot_structure(
sm,
graph_attributes={"scale": "0.5"},
all_node_attributes=NODE_STYLE.WEAK,
all_edge_attributes=EDGE_STYLE.WEAK,
)
Image(viz.draw(format='png'))
3.4 导出结构
使用networkx导出nx_pydot:
import networkx as nx
nx.drawing.nx_pydot.write_dot(sm, 'graph.dot')
3.5 拟合贝叶斯网络的条件分布: 数据离散化
当确认了边结构信息,则可以使用贝叶斯网络去拟合不同特征条件概率分布。
CausalNex中的贝叶斯网络只支持离散分布。任何连续的特征,或具有大量类别的特征,在拟合贝叶斯网络之前都应该被离散化。包含有许多可能值的变量的模型通常不适合,并且表现出较差的性能。
例如,考虑P(G2 | G1),其中G1和G2有可能的值0到20。因此,离散条件概率分布是使用21 × 21(441)种可能的组合来指定的——其中大多数我们将不太可能观察到。
CausalNex提供了一些辅助方法来简化离散化。让我们从通过组合相似的值来减少一些分类特性中的类别数量开始。我们将通过离散化使数字特征分类,然后给桶赋予有意义的标签。
from causalnex.network import BayesianNetwork
bn = BayesianNetwork(sm)
例如,在学习时间功能中,我们把超过2个小时(2在这里意味着2到5个小时,见https://archive.ics.uci.edu/ml/datasets/Student+Performance)的学习时间划分为长学习时间,其余的划分为短学习时间。
discretised_data = data.copy()
data_vals = {col: data[col].unique() for col in data.columns}
failures_map = {v: 'no-failure' if v == [0]
else 'have-failure' for v in data_vals['failures']}
studytime_map = {v: 'short-studytime' if v in [1,2]
else 'long-studytime' for v in data_vals['studytime']}
discretised_data["failures"] = discretised_data["failures"].map(failures_map)
discretised_data["studytime"] = discretised_data["studytime"].map(studytime_map)
Discretising数字特征
为了使数字特征具有分类性,必须首先将它们离散。
CausalNex提供了一个辅助类causalnex.discretiser.Discretiser。
支持多种离散化方法。
对于我们的数据,将应用固定的方法,提供定义桶边界的静态值。
例如,缺勤将被划分为几个部分<1, 1-9,>=10。
每个桶将被标记为从零开始的整数。
from causalnex.discretiser import Discretiser
discretised_data["absences"] = Discretiser(method="fixed",
numeric_split_points=[1, 10]).transform(discretised_data["absences"].values)
discretised_data["G1"] = Discretiser(method="fixed",
numeric_split_points=[10]).transform(discretised_data["G1"].values)
discretised_data["G2"] = Discretiser(method="fixed",
numeric_split_points=[10]).transform(discretised_data["G2"].values)
discretised_data["G3"] = Discretiser(method="fixed",
numeric_split_points=[10]).transform(discretised_data["G3"].values)
为数字特性创建标签
为了使离散的类别更具可读性,我们可以将类别标签映射到更有意义的东西上,就像映射类别特征值一样。
absences_map = {0: "No-absence", 1: "Low-absence", 2: "High-absence"}
G1_map = {0: "Fail", 1: "Pass"}
G2_map = {0: "Fail", 1: "Pass"}
G3_map = {0: "Fail", 1: "Pass"}
discretised_data["absences"] = discretised_data["absences"].map(absences_map)
discretised_data["G1"] = discretised_data["G1"].map(G1_map)
discretised_data["G2"] = discretised_data["G2"].map(G2_map)
discretised_data["G3"] = discretised_data["G3"].map(G3_map)
3.6 BN模型训练
数据进行拆分,训练集与测试集:
# Split 90% train and 10% test
from sklearn.model_selection import train_test_split
train, test = train_test_split(discretised_data, train_size=0.9, test_size=0.1, random_state=7)
利用之前学习的结构模型和离散数据,我们现在可以拟合贝叶斯网络的概率分布。
第一步是指定每个节点可以采取的所有状态。这可以通过数据或提供节点值字典来完成。
我们在这里使用完整的数据集,以避免测试集中的状态在训练集中不存在的情况。
对于真实的应用程序,可能需要使用dictionary方法提供这些状态。
# 模型初始化
bn = bn.fit_node_states(discretised_data)
# 拟合条件概率分布
bn = bn.fit_cpds(train, method="BayesianEstimator", bayes_prior="K2")
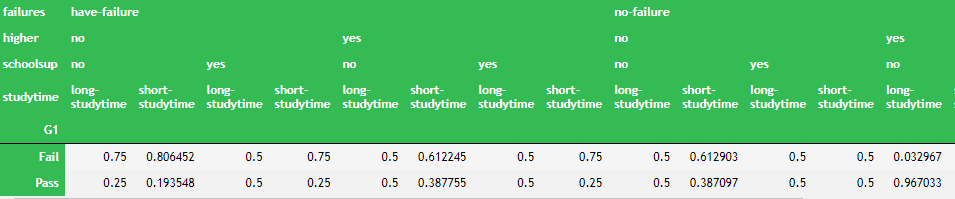
查看BN模型的conditional probablilty distributions (CPDs)条件概率分布字典:
bn.cpds["G1"]
3.7 给定输入数据进行预测
贝叶斯网络的预测方法使我们能够利用学习过的贝叶斯网络对数据进行预测。
例如,我们希望根据输入数据预测一个学生是否通过了考试。
假设我们有一个进入的学生数据是这样的:
discretised_data.loc[18, discretised_data.columns != 'G1']

predictions = bn.predict(discretised_data, "G1")
print(f"The prediction is '{predictions.loc[18, 'G1_prediction']}'")
18号学生,这里学习时间studytime表示为short-studytime,感觉上是过不了的。
The prediction is 'Fail'
这里的预测结果也是fail,是合理的。
3.8 模型评估:分类报告 + ROC/AUC
3.8.1 Classification Report
from causalnex.evaluation import classification_report
classification_report(bn, test, "G1")
输出结果:
{'G1_Fail': {'precision': 0.7777777777777778,
'recall': 0.5833333333333334,
'f1-score': 0.6666666666666666,
'support': 12},
'G1_Pass': {'precision': 0.9107142857142857,
'recall': 0.9622641509433962,
'f1-score': 0.9357798165137615,
'support': 53},
'accuracy': 0.8923076923076924,
'macro avg': {'precision': 0.8442460317460317,
'recall': 0.7727987421383649,
'f1-score': 0.8012232415902141,
'support': 65},
'weighted avg': {'precision': 0.8861721611721611,
'recall': 0.8923076923076924,
'f1-score': 0.8860973888496825,
'support': 65}}
3.8.2 ROC/AUC
from causalnex.evaluation import roc_auc
roc, auc = roc_auc(bn, test, "G1")
print(auc)
3.9 Querying Marginals
3.9.1 基本查询:Baseline Marginals
如果要查询一些节点的概率值的时候,之前的模型是不可以查询的,现在需要重建一个查询引擎:
bn = bn.fit_cpds(discretised_data, method="BayesianEstimator", bayes_prior="K2")
from causalnex.inference import InferenceEngine
ie = InferenceEngine(bn)
marginals = ie.query()
marginals["G1"]
>>> {'Fail': 0.25260687281677224, 'Pass': 0.7473931271832277}
得到每一个节点的条件概率,这里可以看到G1这个节点,0.252是fial的数字,0.747是pass
可以拿到整体数字进行验算,是一致的
import numpy as np
labels, counts = np.unique(discretised_data["G1"], return_counts=True)
list(zip(labels, counts))
3.9.2 条件查询
我们还可以在给定一些观测值的情况下查询网络中状态的边际似然。
这些观察可以在网络的任何地方进行,它们的影响将通过感兴趣的节点传播。
让我们根据学习时间来看看G1的可能性有什么不同。
marginals_short = ie.query({"studytime": "short-studytime"})
marginals_long = ie.query({"studytime": "long-studytime"})
print("Marginal G1 | Short Studtyime", marginals_short["G1"])
print("Marginal G1 | Long Studytime", marginals_long["G1"])
输出为:
Marginal G1 | Short Studtyime {'Fail': 0.2776556433482524, 'Pass': 0.7223443566517477}
Marginal G1 | Long Studytime {'Fail': 0.15504850337837614, 'Pass': 0.8449514966216239}
这里可以看到,有Short Studtyime状态的,G1有0.722是通过的;
有Long Studytime状态的,G1有0.844是通过的
那么相对来说,Long Studytime比Short Studtyime 更容易通过。
3.10 【终于/核心环节】Do Calculus - 混杂因子下的情况
我们可以对数据中的任何节点应用干预,使用do操作符更新其分布。这可以被认为是在问我们的模型“如果有什么不同会怎么样”。
例如,我们可以问,如果100%的学生都想继续接受高等教育,会发生什么:
print("marginal G1", ie.query()["G1"])
ie.do_intervention("higher",
{'yes': 1.0,
'no': 0.0})
print("updated marginal G1", ie.query()["G1"])
结论:
marginal G1 {'Fail': 0.25260687281677224, 'Pass': 0.7473931271832277}
updated marginal G1 {'Fail': , 'Pass': 0.79?????}
这里可以看到如果90%的人意愿继续接受高等教育,G1成绩为0.74;
如果上升到100%意愿接受,G1平均成绩提升到0.79
4 Scikit-learn 集成接口
DAGRegressor / DAGClassifier是因果图Scikit-learn 的回归/分类函数
这里使用起来看上去更加方便。
4.1 线性回归:Linear DAGRegressor
from sklearn.datasets import load_diabetes
import torch
torch.manual_seed(42)
data = load_diabetes()
X, y = data.data, data.target
names = data["feature_names"]
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
X = ss.fit_transform(X)
y = (y - y.mean()) / y.std()
from causalnex.structure import DAGRegressor
reg = DAGRegressor(
alpha=0.1,
beta=0.9,
hidden_layer_units=None,
dependent_target=True,
enforce_dag=True,
)
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
scores = cross_val_score(reg, X, y, cv=KFold(shuffle=True, random_state=42))
print(f'MEAN R2: {np.mean(scores).mean():.3f}')
X = pd.DataFrame(X, columns=names)
y = pd.Series(y, name="DPROG")
reg.fit(X, y)
print(pd.Series(reg.coef_, index=names))
reg.plot_dag(enforce_dag=True)
同时输出:
MEAN R2: 0.478
age 0.000000
sex 0.000000
bmi 0.304172
bp 0.000000
s1 0.000000
s2 0.000000
s3 0.000000
s4 0.000000
s5 0.277010
s6 0.000000
dtype: float64
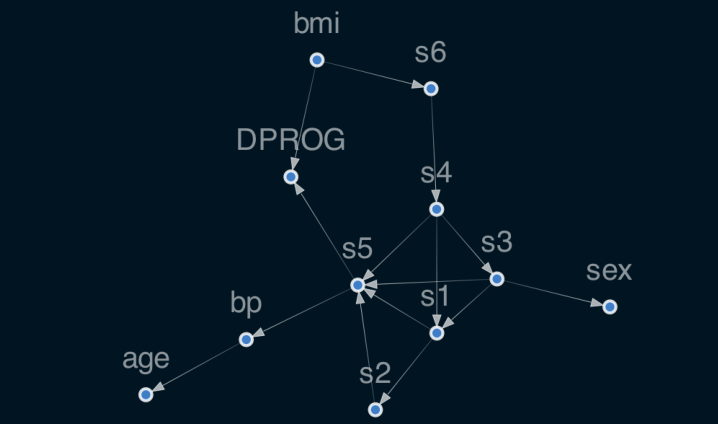
这里有几个特殊模型参数,
- dependent_target:是否 x-> y 的同时,y-> x,如果是true,可以反向指向,默认是True
- enforce_dag,是否在展示的可视化图的时候删除一些边,但是实际运行模型的时候,不会删除。默认是开的
4.2 非线性回归Nonlinear DAGRegressor
数据处理过程中比较重要的是,需要对数据进行标准化
from sklearn.datasets import load_diabetes
import torch
torch.manual_seed(42)
data = load_diabetes()
X, y = data.data, data.target
names = data["feature_names"]
from causalnex.structure import DAGRegressor
reg = DAGRegressor(
threshold=0.0,
alpha=0.0001,
beta=0.2,
hidden_layer_units=[2],
standardize=True,
enforce_dag=True,
)
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
scores = cross_val_score(reg, X, y, cv=KFold(shuffle=True, random_state=42))
print(f'MEAN R2: {np.mean(scores).mean():.3f}')
X = pd.DataFrame(X, columns=names)
y = pd.Series(y, name="DPROG")
reg.fit(X, y)
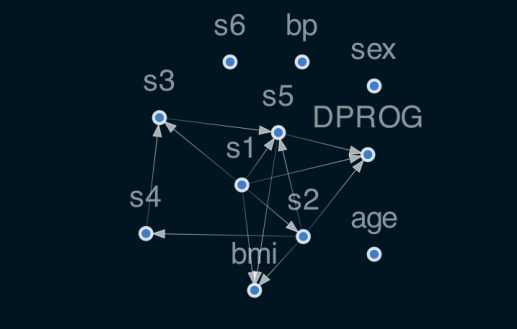
reg.plot_dag(enforce_dag=True)
非线性层包含s型非线性,它会因未缩放的数据而饱和。
此外,未缩放的数据意味着正则化参数不会对各特征的权重产生同等的影响。
其中,standardize = True,代表对X/Y都进行标准化。
它还将y on predict进行逆变换,类似于sklearn TransformedTargetRegressor。
4.3 分类模型:DAGClassifier
from sklearn.datasets import load_breast_cancer
data = load_breast_cancer()
X, y = data.data, data.target
names = data["feature_names"]
from causalnex.structure import DAGClassifier
clf = DAGClassifier(
alpha=0.1,
beta=0.9,
hidden_layer_units=[5],
fit_intercept=True,
standardize=True
)
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
scores = cross_val_score(clf, X, y, cv=KFold(shuffle=True, random_state=42))
print(f'MEAN Score: {np.mean(scores).mean():.3f}')
X = pd.DataFrame(X, columns=names)
y = pd.Series(y, name="NOT CANCER")
clf.fit(X, y)
for i in range(clf.coef_.shape[0]):
print(f"MEAN EFFECT DIRECTIONAL CLASS {i}:")
print(pd.Series(clf.coef_[i, :], index=names).sort_values(ascending=False))
clf.plot_dag(True)
输出:
MEAN Score: 0.975
MEAN EFFECT DIRECTIONAL CLASS 0:
fractal dimension error 0.435006
texture error 0.253090
mean compactness 0.225626
symmetry error 0.112259
compactness error 0.094851
worst compactness 0.087924
mean fractal dimension 0.034403
concavity error 0.030805
mean texture 0.024233
mean symmetry -0.000012
mean perimeter -0.000603
mean area -0.003670
mean radius -0.005750
mean smoothness -0.007812
perimeter error -0.021268
concave points error -0.088604
smoothness error -0.173150
worst smoothness -0.174532
worst fractal dimension -0.193018
worst perimeter -0.241930
worst concavity -0.251617
worst symmetry -0.253782
worst concave points -0.255410
mean concavity -0.317477
mean concave points -0.322275
worst area -0.427581
worst radius -0.448448
radius error -0.489342
area error -0.518434
worst texture -0.614594
dtype: float64


瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 3
3 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)