
京东搜索产品时只能获取到每页的前30个产品,scrapy+selenium取到后面30个产品
问题描述:京东解析源代码,只能得到30个商品,但是实际一页有60个商品。当我们直接用xpath直接解析源代码时,发现只能得到30个商品,但是在前台,我们明明看到的是60个商品。这是因为刚刷新页面时,先展示源代码的30个商品,后面30个商品,需要下拉进度条,懒加载后面30个商品。scrapy如何结合selenium实现模拟下拉?解决方法:简单的讲,就是加一个selenium中间件,爬虫...
·
问题描述:京东解析源代码,只能得到30个商品,但是实际一页有60个商品。
当我们直接用xpath直接解析源代码时,发现只能得到30个商品,但是在前台,我们明明看到的是60个商品。
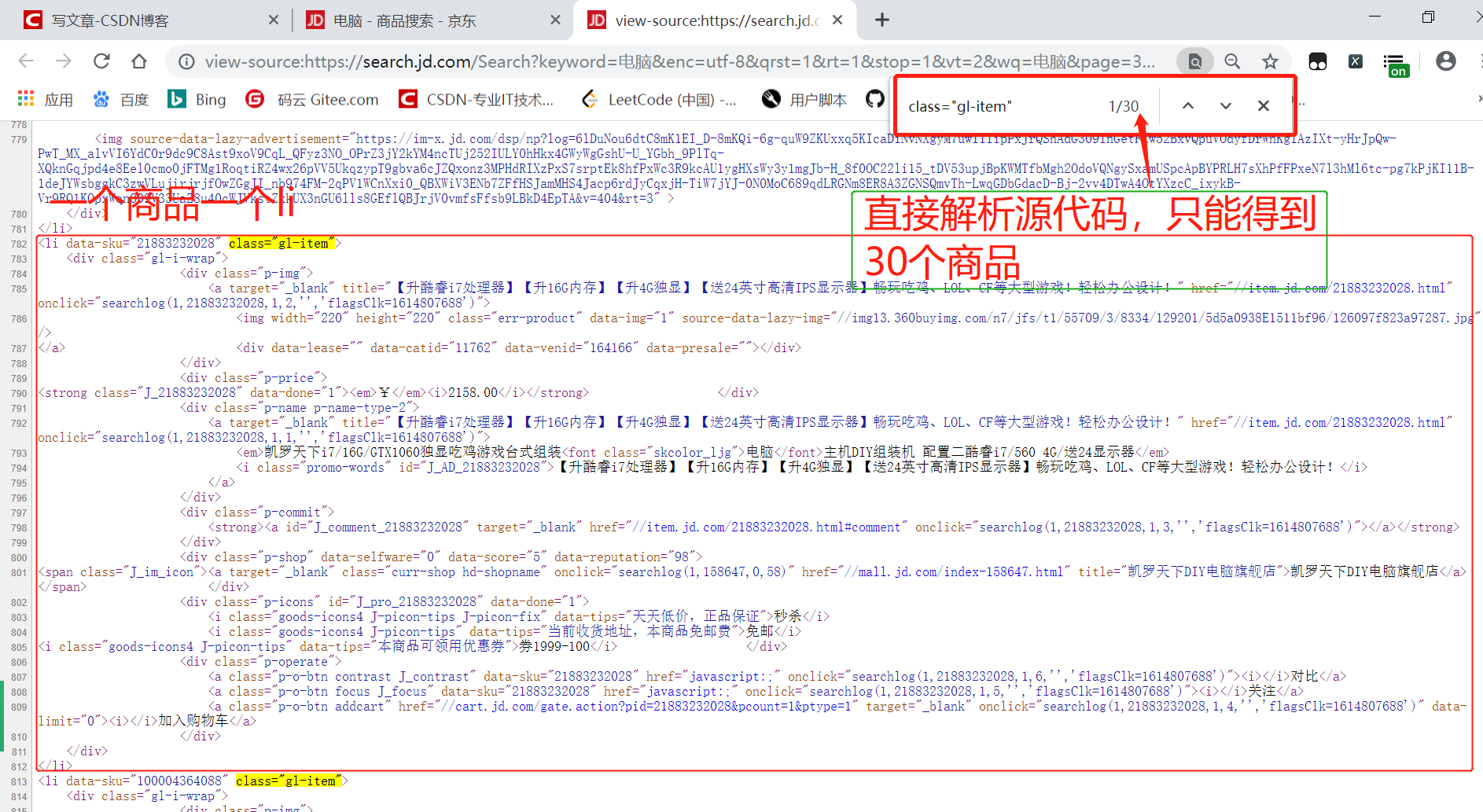
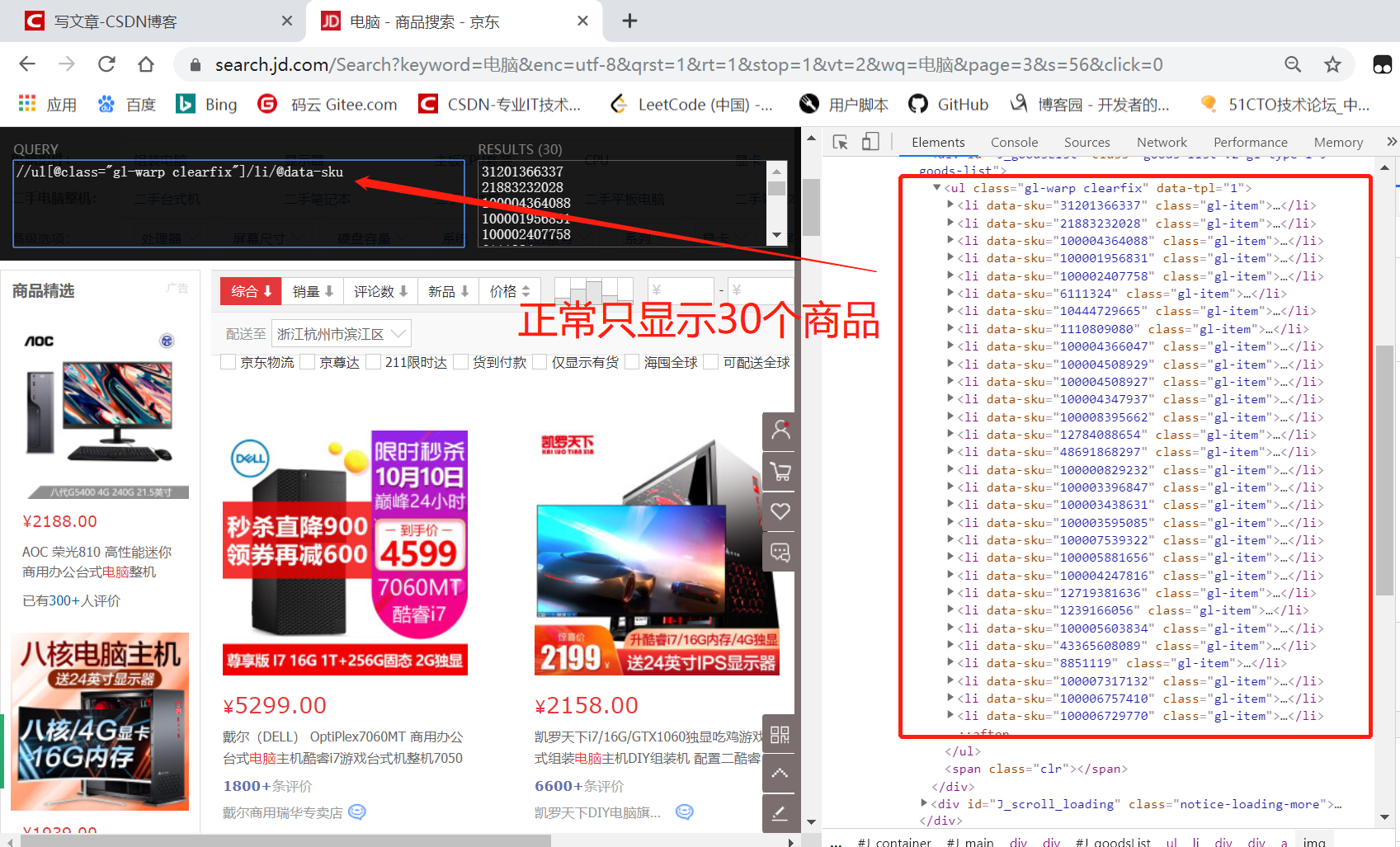
这是因为刚刷新页面时,先展示源代码的30个商品,后面30个商品,需要下拉进度条,懒加载后面30个商品。
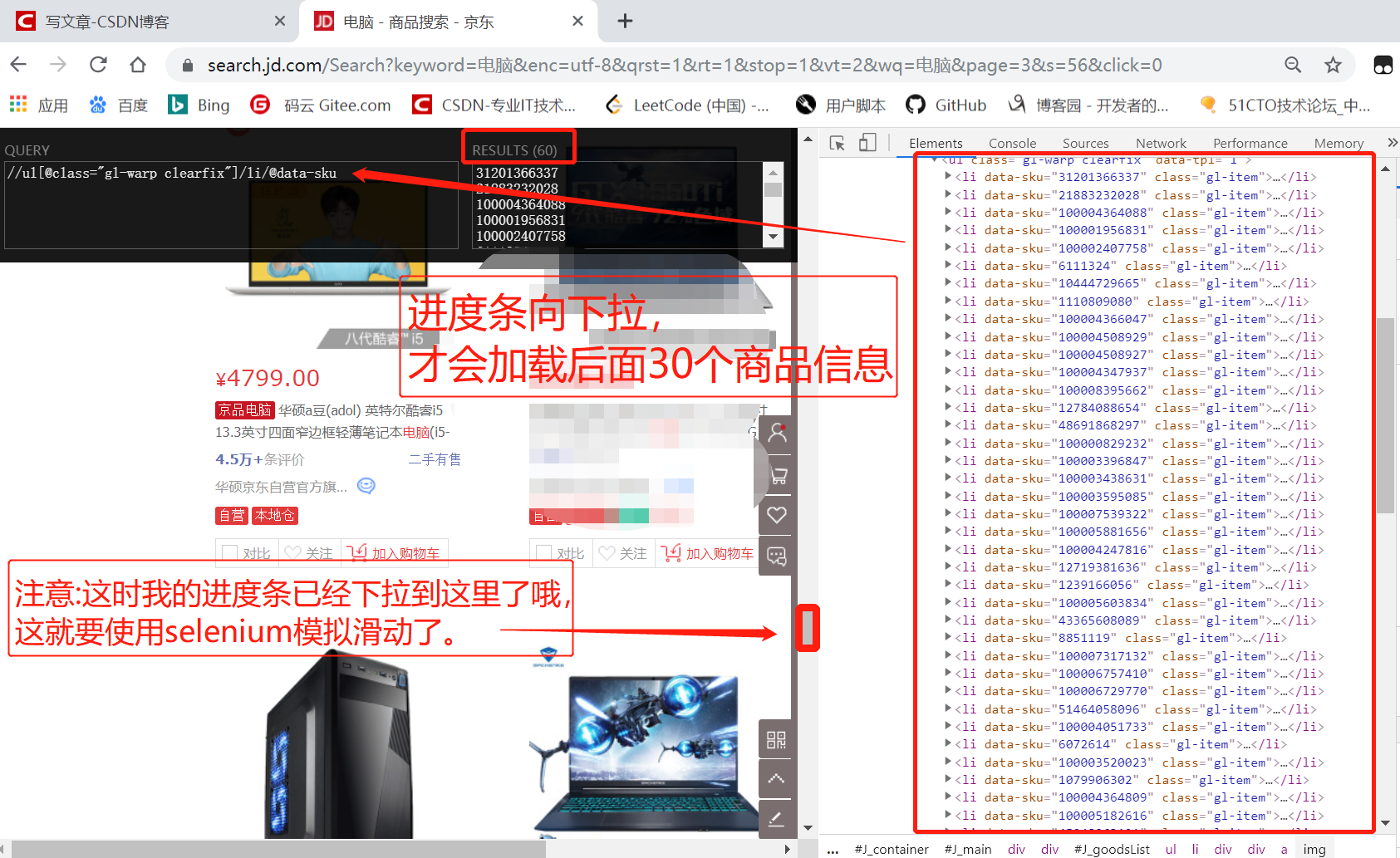
scrapy如何结合selenium实现模拟下拉?
解决方法:简单的讲,就是加一个selenium中间件,爬虫文件在Request请求时,使用这个中间件。但是不是所有的请求都要用selenium,该如何对某个单独的请求使用selenium这个中间件呢?请听我慢慢分享。
第一步:scrapy写一个selenium中间件
# 下载中间件,使用用selenium 爬取
class SeleniumMiddleware(object):
def process_request(self, request, spider):
"""处理一切请求的方法"""
# 这个if条件很重要,用来区分哪个请求使用selenium
if request.meta.get("middleware") == "SeleniumMiddleware":
try:
# url是request自带的属性,可以直接调用请求
spider.browser.get(request.url)
# 这个方法是使窗口下拉
spider.browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
except TimeoutException as e:
print('超时')
# 如果请求超时,就停止
spider.browser.execute_script('window.stop()')
# 休息2s,使页面加载完全
time.sleep(2)
# 返回加载后的页面response
return HtmlResponse(url=spider.browser.current_url, body=spider.browser.page_source,
encoding="utf-8", request=request)
第二步:settings里使用中间件
# settings的部分节选
DOWNLOADER_MIDDLEWARES = {
'JD.middlewares.JdDownloaderMiddleware': None,
'JD.middlewares.ProcessAllExceptionMiddleware': 297,
'JD.middlewares.JdDownloadmiddlewareRandomUseragent': 299,
'JD.middlewares.SeleniumMiddleware': 300, # 看这里,我已经开启了这个中间件
'JD.middlewares.StatCollectorMiddleware': 400
}
第三步:爬虫文件要记得传递meta参数,才会调用selenium中间件

看着是不是很眼熟?这个就是传递给selenium中间件那个参数,只有指定这个参数时,才会调用selenium。
以上,就轻松解决这个问题啦! 是不是还挺简单的!这个中间件还是挺方便的呢~

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)