
(5分钟速读!)中科院自动化所发布目标检测大模型-满足用户指定需求的迁移学习系统
设计良好的子网采样空间对网络的训练至关重要,在我们进行探索的过程中发现网络深度和输入图像分辨率是影响模型性能的核心因素,网络宽度是模型运行占用显存的关键因素。用户在本地下游任务中,能提供的有标签数据十分有限,已有的开源数据集虽然包含的数据类别十分丰富,数量也十分庞大,但是相同类别的数据存在域间差异,比如漫画图片中的鸟和自然场景中的鸟存在很大差异,直接通过类别使用开源数据集,只会对用户本地下游任务产
如有需要,请关注微信公众号“笔名二十七画生”!
先给大家介绍一下迁移学习的概念:
迁移学习一直以来都是深度学习历史上最强大的技术之一。在计算机视觉(CV)和自然语言处理(NLP)的广泛任务范围内,预先在大规模源数据集上进行预训练,然后在目标数据集或任务上进行微调的范式被应用于各种任务。其动机是赋予模型通用能力并将知识转移到下游任务,以获取更高性能或更快的收敛速度。
GAIA文章摘要
最近,基于大规模预训练数据集的迁移学习在计算机视觉和自然语言处理领域发挥着越来越重要的作用。然而,由于存在许多具有独特需求的应用场景,因此要利用大规模预训练来满足特定任务的要求是极为昂贵的。中国科学院自动化研究所智能感知与计算研究中心联合华为等企业专注于目标检测领域,提出了一种名为GAIA的迁移学习系统,该系统可以根据异构的下游需求自动而高效地生成定制解决方案。GAIA能够提供强大的预训练权重,选择符合下游需求(如指定的数据领域)的模型,并为那些任务数据点非常有限的从业者收集相关数据。GAIA在10余种数据集上取得了令人满意的结果。该成果发表在 CVPR 2021会议。

论文地址:
https://arxiv.org/pdf/2106.11346.pdf
代码网址:
https://github.com/GAIA-vision
https://github.com/GAIA-vision/GAIA-det
https://github.com/GAIA-vision/GAIA-seg
GALA前世今生
随着数据规模呈指数级增长,迁移学习的影响已经进入了下一个层次。在BiT 和WSL 中,对庞大数据(如JFT-300M和Instagram的35亿张图像)进行预训练已被证明在下游任务上产生了非凡的改进,超过了传统的ImageNet预训练方法。类似的趋势也出现在NLP中,如BERT ,T5 和GPT-3中所示。
(为了解决什么问题)正如“没有免费午餐”定理所述,没有单一算法适用于所有可能的场景和数据集。不同的数据集可能需要不同的模型架构,不同的应用场景可能需要不同规模的模型。为了利用迁移学习,这些定制模型被迫在整个上游数据集上从头开始训练,这是极其昂贵的。尤其是在目标检测中,检测器总是被假设在具有不同资源限制的各种设备上运行,这要求检测器具有相应的输入大小和架构。因此,在目标检测中,对于任务特定的架构适应的需求要比其他任务(如图像分类或语义分割)更为强烈。
在这篇论文中,作者介绍了一种目标检测的迁移学习系统,旨在弥合大规模上游训练与下游定制之间的差距,并将系统命名为GAIA。GAIA有两个组成部分:任务不可知的统一和任务特定的自适应。论文的贡献如下:
-
1.演示了如何将迁移学习和权重共享学习巧妙结合,同时在各种架构上产生强大的预训练模型。
-
2.提出了一种高效可靠的方法,找到适应于特定下游任务的网络架构。在预训练和任务特定架构选择的支持下,GAIA在不对超参数进行专门调整的情况下,在10个下游任务上取得了令人惊讶的好结果。
-
3.GAIA能够根据下游任务中每个类别的2张图像找到相关数据,以支持微调(这个比较有用)。这进一步扩展了GAIA在数据稀缺环境中的效用。
GALA匠心独运
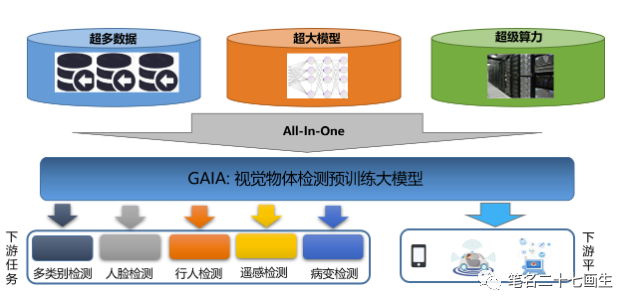
视觉目标检测大模型GAIA作为面向行业打造的下一代一站式目标检测新方案,包含上游数据集、全模型训练、稀疏数据下数据选取和部署模型提取四个模块。
视觉目标检测大模型GAIA技术框架
上游数据集赋能
借鉴大规模预训练模型 BERT、GPT-3 等在自然语言处理领域中的成功,GAIA 将该范式延拓到视觉目标检测领域,对所有可用公开数据集整合并进行大规模预训练,增加模型的泛化能力和表示能力。由于自然语言中语料数据集本身是离散型,自然语言处理中的大规模预训练很容易构建无监督训练任务。但是这种方法迁移至计算机视觉领域就会遇到很多瓶颈,不同数据集的类别标签很容易出现歧义,比如像 earth、ground 可能在不同的数据集中都表示地面,或不同数据集类别标签之间存在包含关系,像绿植和树。GAIA 通过语义模型对类别建立语义相似度,将不同数据集中类别语义相似度大于阈值的归为同一类别,从而梳理出最终的类别和 ID 的映射关系。(不知道之前有没有人做过)
全模型训练
神经网络架构搜索算法 OFA、BigNAS 等在训练超网时,对其中的子网同时训练,这样只需花费很小的代价就可得到不需要微调就性能优异的子网络。与 BERT、GPT 等预训练大模型相比,GAIA 不同之处在于将 NAS 与大规模预训练进行结合,提供涵盖各种 latency 下的高性能预训练网络。(强大的算力)设计良好的子网采样空间对网络的训练至关重要,在我们进行探索的过程中发现网络深度和输入图像分辨率是影响模型性能的核心因素,网络宽度是模型运行占用显存的关键因素。因此 GAIA 的采样空间从网络深度、输入分辨率、网络宽度三个维度出发,根据已有的经典网络模型设置锚点,在锚点周围空间从三个维度进行子网抽取,让整个模型训练过程更加有效。
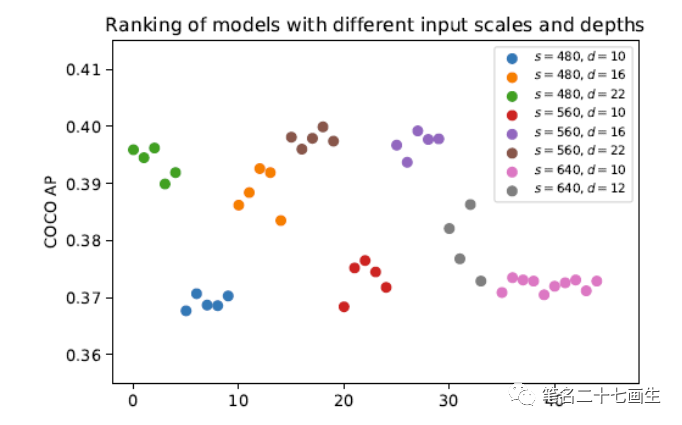
模型性能分析
特定下游任务数据选取
用户在本地下游任务中,能提供的有标签数据十分有限,已有的开源数据集虽然包含的数据类别十分丰富,数量也十分庞大,但是相同类别的数据存在域间差异,比如漫画图片中的鸟和自然场景中的鸟存在很大差异,直接通过类别使用开源数据集,只会对用户本地下游任务产生不利的影响,选取合适数据集,帮助下游任务是一项不小的挑战。通过实验发现,检测框进行分类的全连接层特征图和数据domain有很强的关联性。以person类别为例,对不同数据集中该类别全连接层特征图T-sne降维后进行可视化,发现不同数据集呈现聚簇式地分布在不同的空间区域,说明相同domain数据可以通过分类分支的全连接层特征图进行聚类。GAIA基于此实验现象进行下游任务的数据选取。
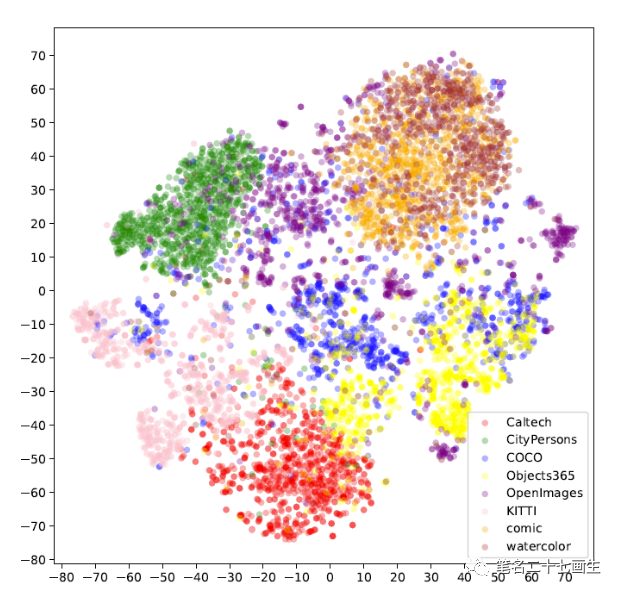
不同数据集下分类全连接层特征图可视化
如果终端用户提供的有标签数据数量没有达到预先设定好的阈值,GAIA会直接根据该使用的语义模型找到本地类别中语义信息最近似的类别,在该类别的上游数据集上通过模型映射向量的相似度找到域间差异最小的一部分图片(如图5),并对提取模型快速训练。通过该功能,即使用户只能够提供几张图片的数据场景下,GAIA同样可以提供十分出色的模型。
下游模型选择
(这个领域不懂)GAIA已经测好所包含各种子网的FLPOPS TABLE,以及多种硬件平台下的LATENCY TABLE(图6)。对于初级使用者而言,只需要在本地提供FLPOPS、LATENCY和硬件平台,就可以获得满足这些约束的性能最佳的子网。对于经验丰富的使用者,可通过GAIA提供的接口,自定义添加其他约束条件,轻松获取性能优异的定制化子网模型。
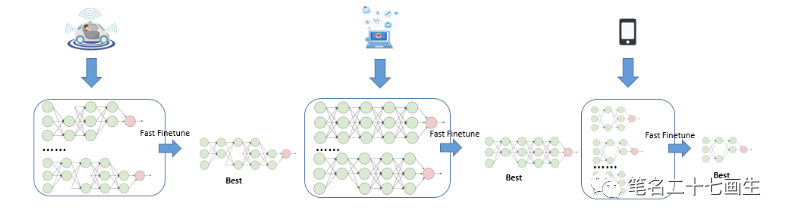
下游模型结构选取
GAIA一鸣惊人
GAIA的强大之处最直接体现在可以满足用户给出的任意时延或任意下游数据,快速定制可部署检测模型,以COCO数据集为例,GAIA-det可以快速提供时延16~53ms、AP 38.2~46.2的模型。用户不需要再花费很大的精力从数据到模型重新开发。
GAIA已经在VOC、Object365、OpenImages、Caltech、KITTI等15个目标检测常用公开数据集上通过测试(图7),发现GAIA提供的模型可以很好的满足终端用户的定制需求。
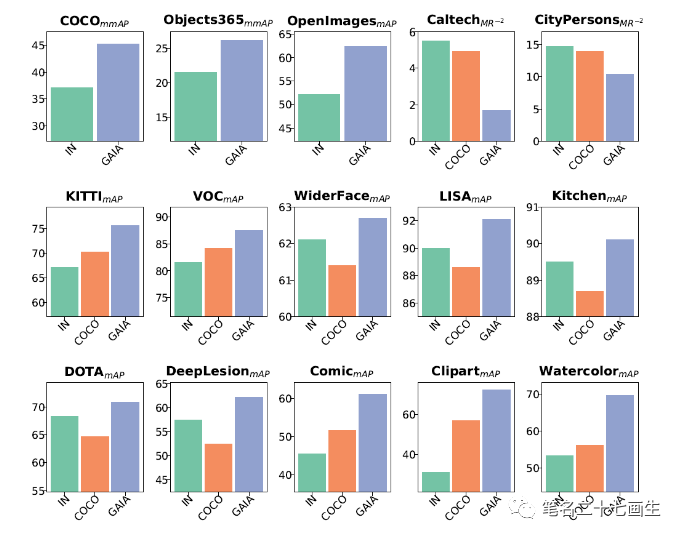
GAIA在目标检测常用数据集的性能对比
GAIA前程似锦
视觉目标检测大模型GAIA是面向行业的视觉物体检测一站式解决方案,随着应用场景的日益丰富和理论技术的突破,不断更新的上游数据集会定期汇聚到GAIA,新的训练模型和网络架构都会通过测试验证后迭代至GAIA,确保GAIA一直为终端用户提供最优质的行业解决方案。现阶段,GAIA-det已在Github上开源,GAIA-seg、GAIA-ssl接近完成,即将推出,致力于解决更多领域的问题。。GAIA是我们大家共同的GAIA,GAIA需要大家的宝贵意见和建议,期望更多的学者和用户共同维护GAIA的迭代,参与到GAIA生态建设中,一起让GAIA成长得更快更好(这种社区开放真的非常不错!!!)。
参考文献:
【1】Xingyuan Bu*, Junran Peng*, Junjie Yan, Tieniu Tan, Zhaoxiang Zhang†, GAIA: A Transfer Learning System of Object Detection that Fits Your Needs, IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Online (Nashville, United States), June 19-25, 2021
【2】http://www.nlpr.ia.ac.cn/cn/news/1642.html

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)