prometheus监控linux主机性能配置alertmanager钉钉报警
下载地址:https://github.com/timonwong/prometheus-webhook-dingtalk/releases/下载地址:https://github.com/prometheus/alertmanager/releases。参考文档:https://blog.51cto.com/u_14304225/6401604。重启prometheus、alertmanger、
一、 prometheus和node_exporter安装忽略,如下为配置文件详细
cat prometheus.yml
#Alertmanager configuration
alerting:
alertmanagers:
#- scheme: http
- static_configs:
- targets:
- '192.168.0.148:9093'
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
- "/data/prometheus/rule/node_exporter.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
- job_name: "test_wjadmin"
metrics_path: /actuator/prometheus
scrape_interval: 5s
basic_auth: # Spring Security basic auth
username: 'actuator'
password: 'actuator'
static_configs:
- targets: ["192.168.1.107:18088"]
- job_name: 'test-process'
static_configs:
- targets: ["192.168.0.123:9256"]
二、安装alertmanager
下载地址:https://github.com/prometheus/alertmanager/releases
下载后解压到指定目录,我这边的安装目录是/data
tar -zxvf alertmanager-0.17.0.linux-amd64.tar.gz
解压完成后配置systemd管理
cat /etc/systemd/system/alertmanager.service
[Unit]
Description=alertmanager
Documentation=https://prometheus.io/download/#alertmanager
After=network.target
[Service]
Type=simple
ExecStart=/data/alertmanager/alertmanager --config.file=/data/alertmanager/alertmanager.yml
Restart=on-failure
[Install]
WantedBy=multi-user.target
设置启动&开机自启
systemctl enable alertmanager --now
systemctl start alertmanager
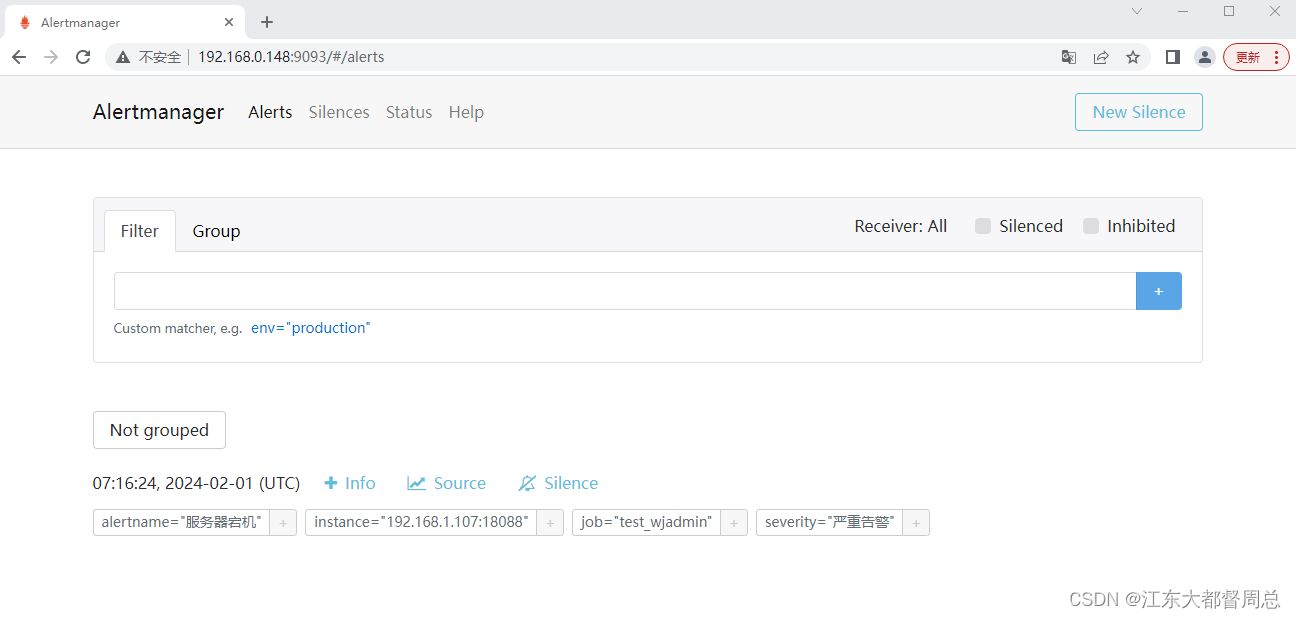
访问9093端口出现如下界面代表安装成功

三、webhook-dingtalk安装
下载地址:https://github.com/timonwong/prometheus-webhook-dingtalk/releases/
下载文件后解压到指定目录
初始化下配置文件:cp config.example.yml config.yml
然后配置systemd管理
cat /usr/lib/systemd/system/webhook.service
[Unit]
Description=Prometheus-Server
After=network.target
[Service]
ExecStart=/data/webhook-dingtalk/prometheus-webhook-dingtalk --config.file=/usr/local/prometheus/webhook-dingtalk/config.yml
User=root
[Install]
WantedBy=multi-user.target
配置钉钉报警
cat /data/prometheus-webhook-dingtalk/config.yml
## Request timeout
timeout: 5s
## Uncomment following line in order to write template from scratch (be careful!)
#no_builtin_template: true
## Customizable templates path
templates: #配置实际的告警模板
- /data/prometheus-webhook-dingtalk/contrib/templates/dingding.tmpl
## You can also override default template using `default_message`
## The following example to use the 'legacy' template from v0.3.0
#default_message:
# title: '{{ template "legacy.title" . }}'
# text: '{{ template "legacy.content" . }}'
## Targets, previously was known as "profiles"
targets:
webhook1: #此处定义的名字需和alertmanage和promemtheus保持一直
url: https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx #钉钉机器人URL
# secret for signature
secret: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx # 加签密钥
webhook2:
url: https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxxxx
webhook_legacy:
url: https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxxxx
# Customize template content
message:
# Use legacy template
title: '{{ template "legacy.title" . }}'
text: '{{ template "legacy.content" . }}'
webhook_mention_all:
url: https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxxxx
mention:
all: true
webhook_mention_users:
url: https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxxxx
mention:
mobiles: ['156xxxx8827', '189xxxx8325']
模板文件
cat /data/prometheus-webhook-dingtalk/contrib/templates/dingding.tmpl
{{ define "__subject" }}
[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}]
{{ end }}
{{ define "__alert_list" }}{{ range . }}
---
{{ if .Labels.owner }}@{{ .Labels.owner }}{{ end }}
**告警名称**: {{ index .Annotations "title" }}
**告警级别**: {{ .Labels.severity }}
**告警主机**: {{ .Labels.instance }}
**告警信息**: {{ index .Annotations "description" }}
**告警时间**: {{ dateInZone "2006.01.02 15:04:05" (.StartsAt) "Asia/Shanghai" }}
{{ end }}{{ end }}
{{ define "__resolved_list" }}{{ range . }}
---
{{ if .Labels.owner }}@{{ .Labels.owner }}{{ end }}
**告警名称**: {{ index .Annotations "title" }}
**告警级别**: {{ .Labels.severity }}
**告警主机**: {{ .Labels.instance }}
**告警信息**: {{ index .Annotations "description" }}
**告警时间**: {{ dateInZone "2006.01.02 15:04:05" (.StartsAt) "Asia/Shanghai" }}
**恢复时间**: {{ dateInZone "2006.01.02 15:04:05" (.EndsAt) "Asia/Shanghai" }}
{{ end }}{{ end }}
{{ define "default.title" }}
{{ template "__subject" . }}
{{ end }}
{{ define "default.content" }}
{{ if gt (len .Alerts.Firing) 0 }}
**====侦测到{{ .Alerts.Firing | len }}个故障====**
{{ template "__alert_list" .Alerts.Firing }}
---
{{ end }}
{{ if gt (len .Alerts.Resolved) 0 }}
**====恢复{{ .Alerts.Resolved | len }}个故障====**
{{ template "__resolved_list" .Alerts.Resolved }}
{{ end }}
{{ end }}
{{ define "ding.link.title" }}{{ template "default.title" . }}{{ end }}
{{ define "ding.link.content" }}{{ template "default.content" . }}{{ end }}
{{ template "default.title" . }}
{{ template "default.content" . }}
以上钉钉webhook配置接受,重启
四、 alertmanager配置
cat /data/alertmanager/alertmanager.yml
global:
resolve_timeout: 5m
route:
group_by: ['dingding']
group_wait: 10s #10秒是个时间窗口,这个窗口内,同一个分组的所有消息会被合并为同一个通知
group_interval: 10s #同一个分组发送一次合并消息之后,每隔10s检查一次告警,判断是否要继续对此告警做操作
repeat_interval: 1h #按照group_interval的配置,每隔10秒钟检查一次,等到第六次时,大于repeat_interval的1h,此时就会在再次发送告警
receiver: dingding.webhook1
routes:
- receiver: 'dingding.webhook1'
match_re:
alertname: ".*" #表示所有的告警走钉钉,也可以自定义正则
receivers:
- name: 'dingding.webhook1'
webhook_configs:
- url: 'http://192.168.0.148:8060/dingtalk/webhook1/send' #webhook-dingtalk组件地址+端口 webhook1是在webhok-dingtalk定义的
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
至此alertmanage配置文件修改完成
五、prometheus集成alertmanager及告警规则
prometheus配置文件添加如下配置:
#Alertmanager configuration
alerting:
alertmanagers:
#- scheme: http
- static_configs:
- targets:
- '192.168.0.148:9093' #alertmanage的服务地址
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
- "/data/prometheus/rule/node_exporter.yml" #告警规则文件地址
#prometheus监控配置内容
- job_name: "linux-host"
static_configs:
- targets: ["192.168.0.1:9100","192.168.0.2:9100"]
报警规则内容:
cat /data/prometheus/rule/node_exporter.yml
mkdir /usr/local/prometheus/prometheus/rule
vim /usr/local/prometheus/prometheus/rule/node_exporter.yml
groups:
- name: 服务器资源监控
rules:
- alert: 内存使用率过高
expr: 100 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes) * 100 > 80 #这里的监控参数根据自己实际监控的指标去修改,其他维度的同理
for: 3m
labels:
severity: 严重告警
annotations:
summary: "{{ $labels.instance }} 内存使用率过高, 请尽快处理!"
description: "{{ $labels.instance }}内存使用率超过80%,当前使用率{{ $value }}%."
- alert: 服务器宕机
expr: up == 0
for: 1s
labels:
severity: 严重告警
annotations:
summary: "{{$labels.instance}} 服务器宕机, 请尽快处理!"
description: "{{$labels.instance}} 服务器延时超过3分钟,当前状态{{ $value }}. "
- alert: CPU高负荷
expr: 100 - (avg by (instance,job)(irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 90
for: 5m
labels:
severity: 严重告警
annotations:
summary: "{{$labels.instance}} CPU使用率过高,请尽快处理!"
description: "{{$labels.instance}} CPU使用大于90%,当前使用率{{ $value }}%. "
- alert: 磁盘IO性能
expr: avg(irate(node_disk_io_time_seconds_total[1m])) by(instance,job)* 100 > 90
for: 5m
labels:
severity: 严重告警
annotations:
summary: "{{$labels.instance}} 流入磁盘IO使用率过高,请尽快处理!"
description: "{{$labels.instance}} 流入磁盘IO大于90%,当前使用率{{ $value }}%."
- alert: 网络流入
expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance,job)) / 100) > 102400
for: 5m
labels:
severity: 严重告警
annotations:
summary: "{{$labels.instance}} 流入网络带宽过高,请尽快处理!"
description: "{{$labels.instance}} 流入网络带宽持续5分钟高于100M. RX带宽使用量{{$value}}."
- alert: 网络流出
expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance,job)) / 100) > 102400
for: 5m
labels:
severity: 严重告警
annotations:
summary: "{{$labels.instance}} 流出网络带宽过高,请尽快处理!"
description: "{{$labels.instance}} 流出网络带宽持续5分钟高于100M. RX带宽使用量{$value}}."
- alert: TCP连接数
expr: node_netstat_Tcp_CurrEstab > 10000
for: 2m
labels:
severity: 严重告警
annotations:
summary: " TCP_ESTABLISHED过高!"
description: "{{$labels.instance}} TCP_ESTABLISHED大于100%,当前使用率{{ $value }}%."
- alert: 磁盘容量
expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 90
for: 1m
labels:
severity: 严重告警
annotations:
summary: "{{$labels.mountpoint}} 磁盘分区使用率过高,请尽快处理!"
description: "{{$labels.instance}} 磁盘分区使用大于90%,当前使用率{{ $value }}%."
六、钉钉机器人配置
在群配置点击机器人管理,添加机器人




点击完成即可完成机器人创建
七、验证
重启prometheus、alertmanger、webhook-dingtalk
登录prometheus,点击alerts查看

手动修改报警阈值触发报警查看钉钉是否收到报警信息

以上即可完成prometheus 钉钉报警功能。
参考文档:https://blog.51cto.com/u_14304225/6401604
https://blog.csdn.net/shaochenshuo/article/details/126700256

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)