
目标跟踪之LTMU:High-Performance Long-Term Tracking with Meta-Updater环境配置及代码运行
代码地址:https://github.com/Daikenan/LTMU论文地址:LTMU是CVPR2020的oral,全文重点分析了跟踪过程中经典的模型更新问题。作者一共在六个state-of-the-art的跟踪器上验证了meta-update的有效性,因此给出了六个trackers的代码,其中论文里面的结果应该是DiMP_LTMU跟踪器(PrDiMP+MU和Super_DiMP+MU的性能
代码地址:https://github.com/Daikenan/LTMU
论文地址:High-Performance Long-Term Tracking with Meta-Updater
LTMU是CVPR2020的oral,全文重点分析了跟踪过程中经典的模型更新问题。
作者一共在六个state-of-the-art的跟踪器上验证了meta-update的有效性,因此给出了六个trackers的代码,其中论文里面的结果应该是DiMP_LTMU跟踪器(PrDiMP+MU和Super_DiMP+MU的性能更优,但这两个跟踪器是在LTMU发表之后,所以作者也加了进去)。

一、创建虚拟环境
cd DiMP_LTMU
source create -n DiMP_LTMU python=3.7
source activate DiMP_LTMU
pip install -r requirements.txt
bash compile.sh
二、模型路径下载及路径放置
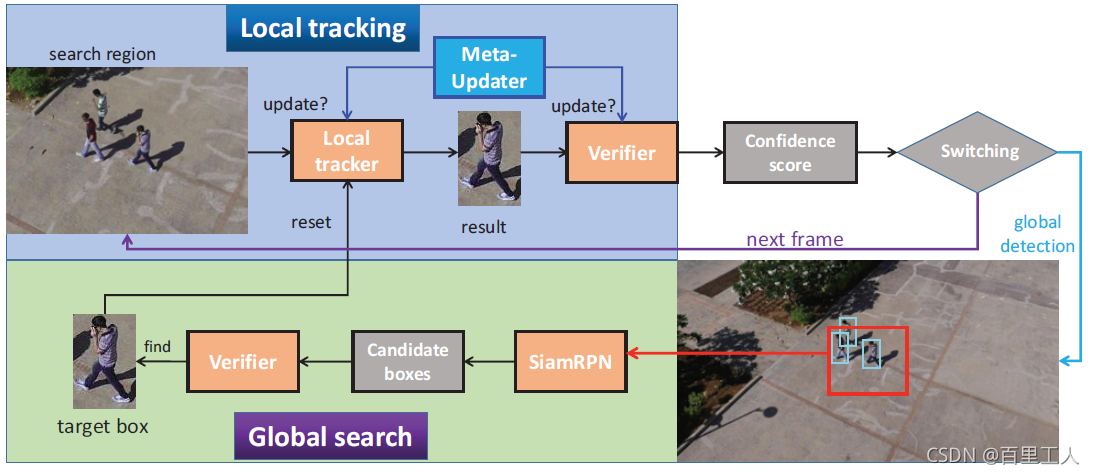
LTMU使用DiMP作为local tracker,但不同于DiMP的是,在尺寸回归分支,LTMU用的是SiamMask(分割使得尺寸回归更加精确),Verifier使用的是RT-MDNet来得到置信度得分,但置信度得分低于0时,开启重检测(使用GlobalTrack)。
所以一共用到五个网络模型:模型下载地址:https://pan.baidu.com/s/1-ZReq_Ls63IqsSQ28rdTXA[gzjm]
放置位置:
DiMP_LTMU/Global_Track/checkpoints/qg_rcnn_r50_fpn_coco_got10k_lasot.pth
DiMP_LTMU/pyMDNet/models/mdnet_imagenet_vid.pth
utils/metric_net/metric_model/metric_model.pt
DiMP_LTMU/SiamMask/experiments/siammask/SiamMask_VOT_LD.pth
DiMP_LTMU/pytracking/networks/dimp50.pth
三、代码运行
运行demo.py
四、如何进行meta-updater?
LTMU使用三阶段的级联LSTM来指导模型更新,充分挖掘视频的时序信息,包括geometric, discriminative and appearance cues三种信息,并输出一个二值决策,确定当前帧是否更新。
- Geometric cue指的是历史帧的boundingbox集合,这些boundingbox联合起来可以分析出了目标的运动信息、尺寸变化情况
- Discriminative cue指的是得到的响应图的峰值,峰值越高,说明当前模型的预测结果越可信
- Appearance cue指的是作者自己离线训练的网络
W
A
W^{A}
WA,可以免于更新带来的噪声污染,类似于孪生网络的感觉,反映每一帧跟踪结果与第一帧(完全精确的boundingbox)的一个相似度得分
s
t
A
s_{t}^A
stA,计算公式如下。
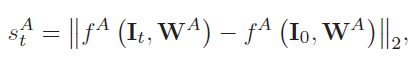
作者通过全面挖掘这些信息,得到了一个二值决策,判断是否需要更新,对于长时跟踪效果确实很佳。

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)