
Spark命令笔录(4)-运行模式
Spark程序运行需要资源调度的框架,比较常见的有Yarn、Standalone、Mesos等,Yarn是基于Hadoop的资源管理器,Standalone是Spark自带的资源调度框架,Mesos是Apache下的开源分布式资源管理框架,使用较多的是Yarn和Standalone,本篇浅谈Spark在这两种框架下的运行方式。1 StandaloneStandalone分为两种任务提交方式:cli
·
Spark程序运行需要资源调度的框架,比较常见的有Yarn、Standalone、Mesos等,Yarn是基于Hadoop的资源管理器,Standalone是Spark自带的资源调度框架,Mesos是Apache下的开源分布式资源管理框架,使用较多的是Yarn和Standalone,本篇浅谈Spark在这两种框架下的运行方式。
1 Standalone
Standalone分为两种任务提交方式:client,cluster
Standalone-client
任务提交命令:【默认是standalone-client模式】
spark-submit --master spark://master:7077 --class org.apache.saprk.examples.SparkPi /xx/xx/examples/jar/spark-examples.jar
等价于
spark-submit --master spark://master:7077 --deploy-mode client --class org.apache.saprk.examples.SparkPi /xx/xx/examples/jar/spark-examples.jar
--master 指定Spark的主节点
--deploy-mode 指定运行方式【客户端模式/集群模式】
--class 指定运行主类,后面跟 空格+Jar包路径
任务提交流程:
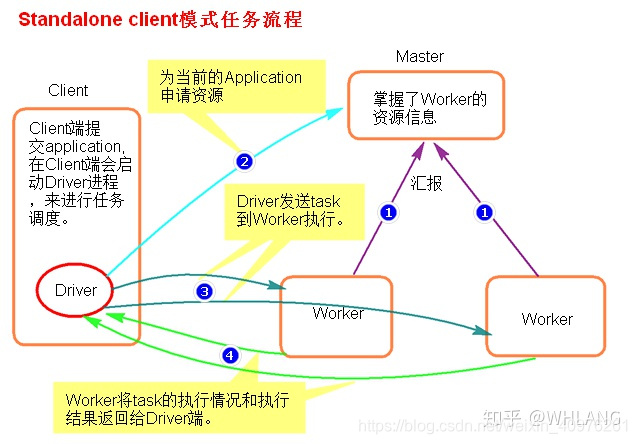
Spark集群,主从结构(必然存在单点故障问题,相对应的也有HA,主Master,从Worker)
Spark集群启动,Worker节点向Master节点汇报各节点资源情况由客户端提交任务(application),并在本节点启动driver进程由Driver进程向Master申请运行application所需要的资源,master返回一批符合资源要求的worker节点,由worker启动本节点上的executor进程,driver分发任务到executor进程进行处理worker节点将执行完毕后的结果数据,返回给Driver,至此任务运行结束
此模式弊端:client提交一个任务就会开启一个driver进程【sparksubmit】,任务是由driver分发的,当一个节点上提交大量的任务时,会对当前节点网卡流量的激增,影响任务的发送,及其他进程的运行。【因此一般适用在测试环境】
Standalone-cluster
任务提交命令:
spark-submit --master spark://master:7077 --deploy-mode cluster --class org.apache.saprk.examples.SparkPi /xx/xx/examples/jar/spark-examples.jar
任务提交流程:
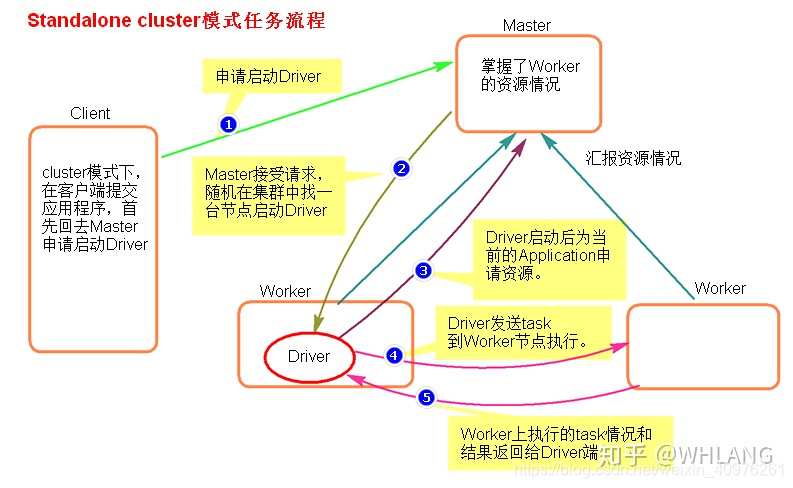
Spark集群启动,Worker节点向Master节点汇报各节点资源情况由客户端提交任务(application),并向Master申请启动driver进程master会根据集群worker节点资源情况,随机挑选一台节点启动driverdriver启动后为application申请资源master返回一批符合资源要求的worker节点,dirver远程启动节点上的executor进程,driver将任务分发到这批worker节点,由executor进程处理任务运行期间worker会将本节点上任务运行情况反馈给driver,任务运行结束后,会将任务处理结果返回给driver,至此任务运行结束
cluster模式,在任务提交后,会在集群上任意选取符合要求的节点启动driver,这样就会将client模式下,单个节点提交大量任务,导致网卡流量激增的问题分摊到整个集群,避免了单节点负载过重。
2 Yarn
Yarn也分为两种任务提交方式:client,cluster
Yarn-client
任务提交命令:【默认是yarn-client模式】
spark-submit --master yarn --class org.apache.saprk.examples.SparkPi /xx/xx/examples/jar/spark-examples.jar
提交命令基本一致,只是在指定运行模式时,将spark://master:7077改为yarn。
任务提交流程:
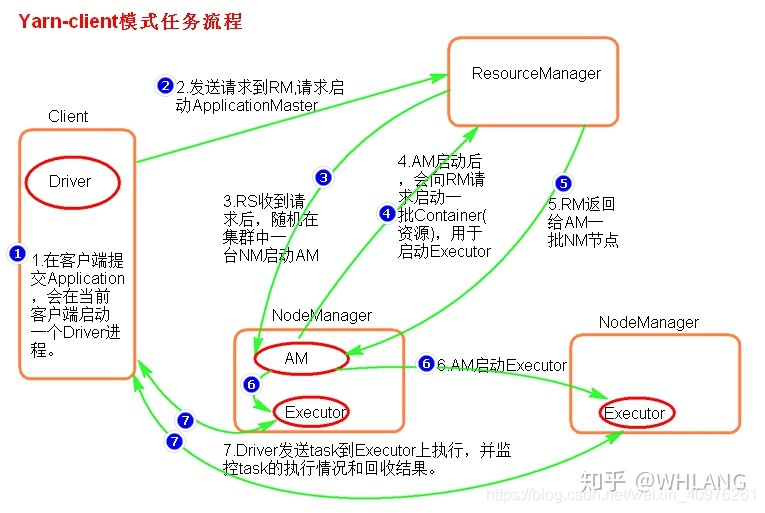
yarn启动,nodemanager节点向resourcemanager节点汇报本节点资源情况由客户端提交任务(application),并向resourcemanager请求启动ApplicationMasterresourcemanager接收请求,根据nodemanager节点资源情况,随机选择一台满足资源要求的节点启动ApplicationMasterApplicationMaster向Resourcemanager申请任务执行所需要的资源,Resourcemanager接收请求,并返回一批包含container的节点,由ApplicationMaster发送远程命令启动节点上的executor进程【ExecutorLaunch进程】executor启动,并反向注册给driverdriver将任务分发到这些executor节点上,并且回收任务执行完毕后的数据结果
*** 在此模式下,ApplicationMaster只做资源的申请,任务的分配及调度依然由driver执行
Yarn的client模式依然会存在,单节点提交大量任务,启动大量的driver进程,造成网卡流量激增问题,也会影响其他进程的运行。【适用测试环境】
Yarn-cluster
任务提交命令:
spark-submit --master yarn --deploy-mode cluster --class org.apache.saprk.examples.SparkPi /xx/xx/examples/jar/spark-examples.jar
提交命令基本一致,只是在指定运行模式时,添加deploy-mode参数,指定运行模式。
任务提交流程:
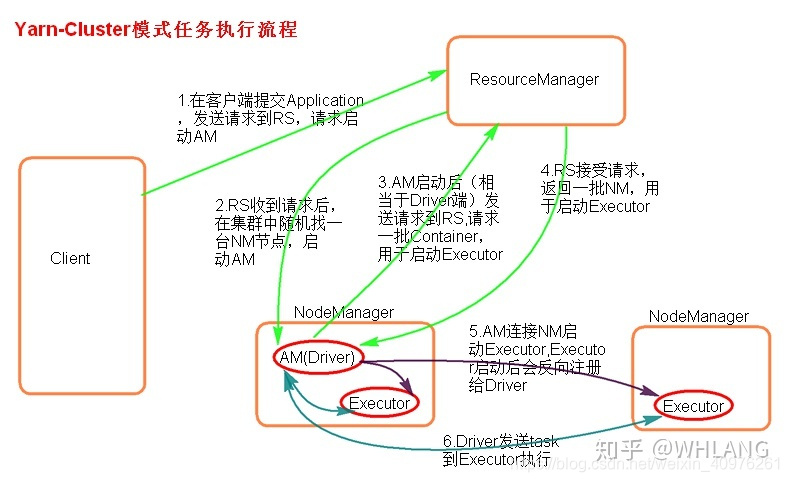
yarn启动,nodemanager节点向resourcemanager节点汇报本节点资源情况由客户端提交任务(application),并向resourcemanager请求启动ApplicationMasterresourcemanager接收请求,根据nodemanager节点资源情况,随机选择一台满足资源要求的节点启动ApplicationMasterApplicationMaster向Resourcemanager申请任务执行所需要的资源,Resourcemanager接收请求,并返回一批包含container的节点,由ApplicationMaster发送远程命令启动节点上的executor进程executor启动,并反向注册给ApplicationMasterApplicationMaster将任务分发到这些executor节点上
*** 与Yarn-Client模式相比,此模式中ApplicationMaster不仅需要向resourcemanager申请资源,也需要进行任务的分发调度,即将driver进程与ApplicationMaster进行的融合。

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)