
语音合成(TTS)论文优选:开源数据集AiShell 3:A Multi-speaker Mandarin TTS Corpus and the Baselines
声明:语音合成(TTS)论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。欢迎关注微信公众号:低调奋进AISHELL-3: A Multi-speaker Mandarin TTS Corpus and the Baselines本次介绍中文开源数据的文章,该文章由北京希尔贝壳公司于2020.10.22更新,主要开源了多说话人数据,
声明:语音合成(TTS)论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。
欢迎关注微信公众号:低调奋进
AISHELL-3: A Multi-speaker Mandarin TTS Corpus and the Baselines
本次介绍中文开源数据的文章,该文章由北京希尔贝壳公司于2020.10.22更新,主要开源了多说话人数据,用于训练multispeaker TTS,为TTS的研究做贡献,具体的文章链接https://arxiv.org/pdf/2010.11567.pdf
1 研究背景
语音合成的训练数据十分昂贵,尤其训练多人的TTS模型,需要大量的多人训练数据,这给很多个人或者研究机构造成很大阻碍。基于开源精神,北京希尔贝壳开源了218说话人85小时的高质量训练数据,给中文TTS研究提供很大的帮助,在此鼓掌,具体的网址AISHELL-3 Baseline Samples
2 数据情况和验证
接下来讲一下开源的数据,数据包含218人数据,数据为44.1khz,16bit。该数据集覆盖了性别,年龄,地域,多领域语料等多项因素,具体的数据分布如table 1

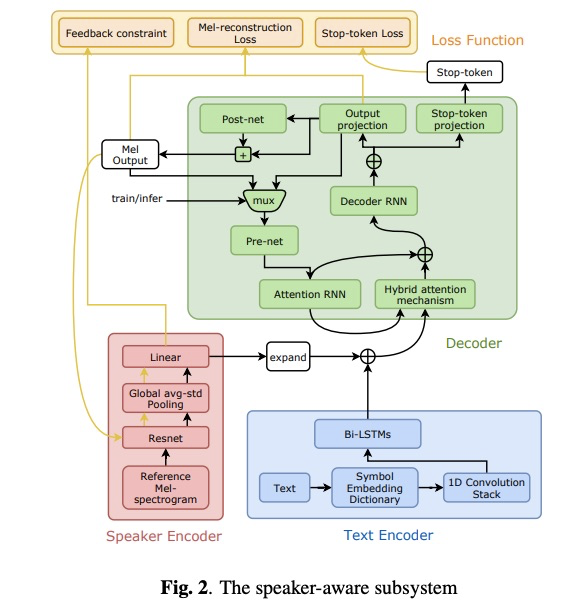
另外为了验证数据,本文提供了基于tacotron的多人TTS架构,如图2所示,具体每个模块不做介绍。
我们直接看结果如图3展示,验证集和测试集的speaker embedding很好的聚类。

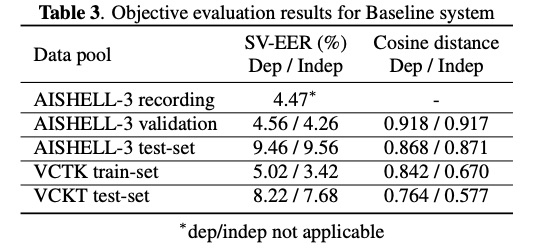
客观的评测SV-EER和Cosine distance也跟vctk结果一致,可以用来今后TTS架构评测标准。
3 总结
高质量的中文语音合成开源数据集相当稀少,本文无私的提供了这样一个多人数据集,为语音合成的研究发展添砖添瓦。

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)