
CV计算机视觉每日开源代码Paper with code速览-2023.12.1
点击@CV计算机视觉,关注更多CV干货论文已打包,点击进入—>下载界面点击加入—>CV计算机视觉交流群
点击@CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
1.【基础网络架构:Transformer】TransNeXt: Robust Foveal Visual Perception for Vision Transformers
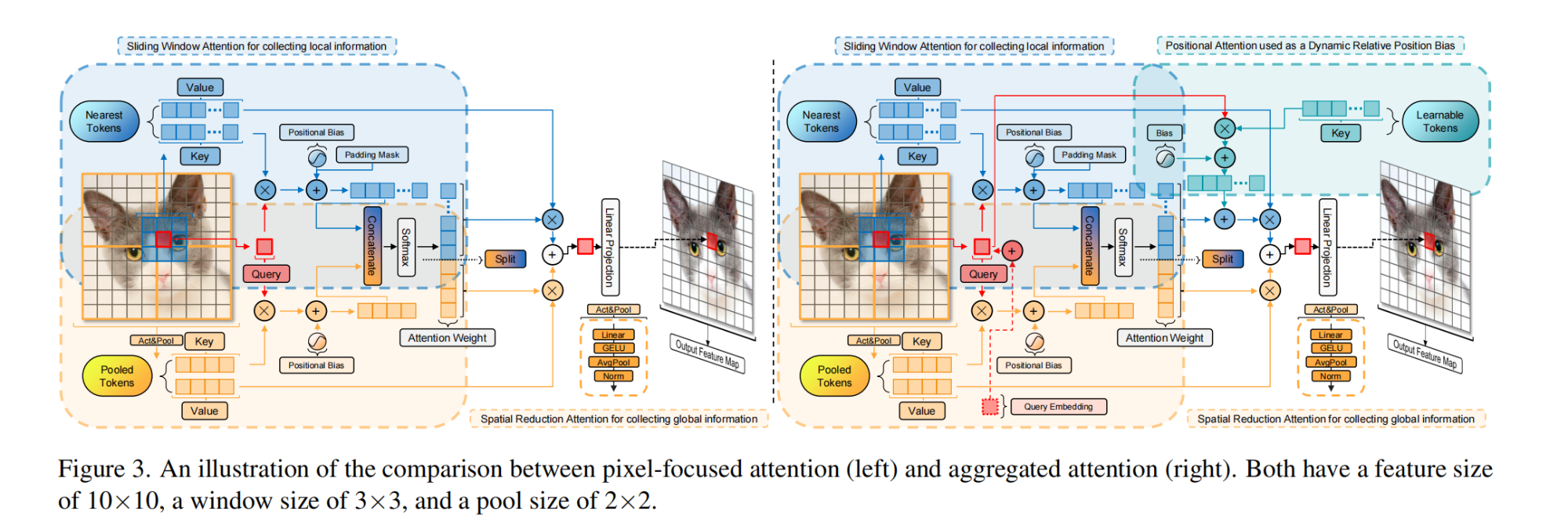
2.【目标检测】Language-conditioned Detection Transformer

3.【目标检测】DyRA: Dynamic Resolution Adjustment for Scale-robust Object Detection

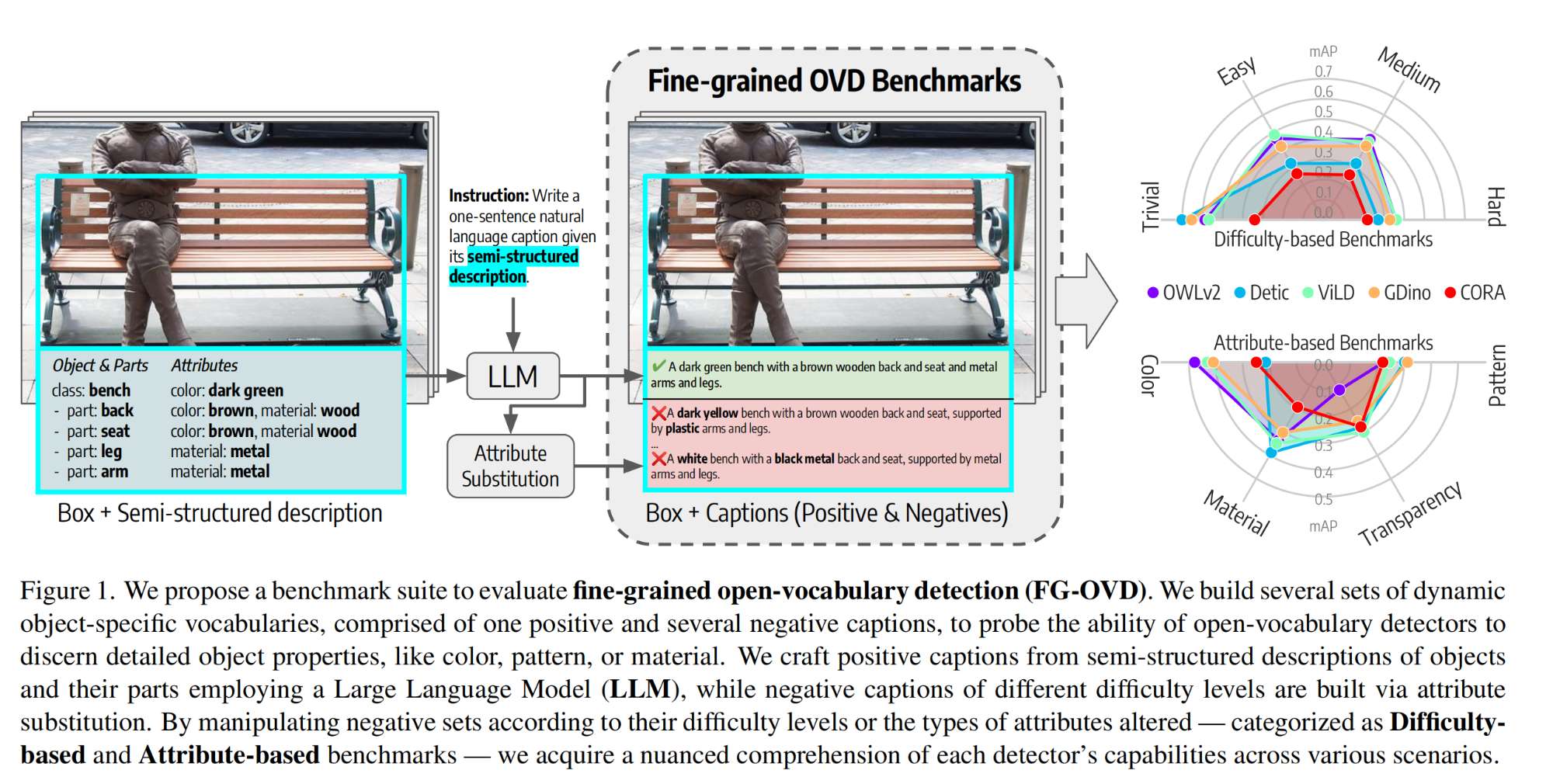
4.【Open-Vocabulary Object Detection】The devil is in the fine-grained details: Evaluating open-vocabulary object detectors for fine-grained understanding
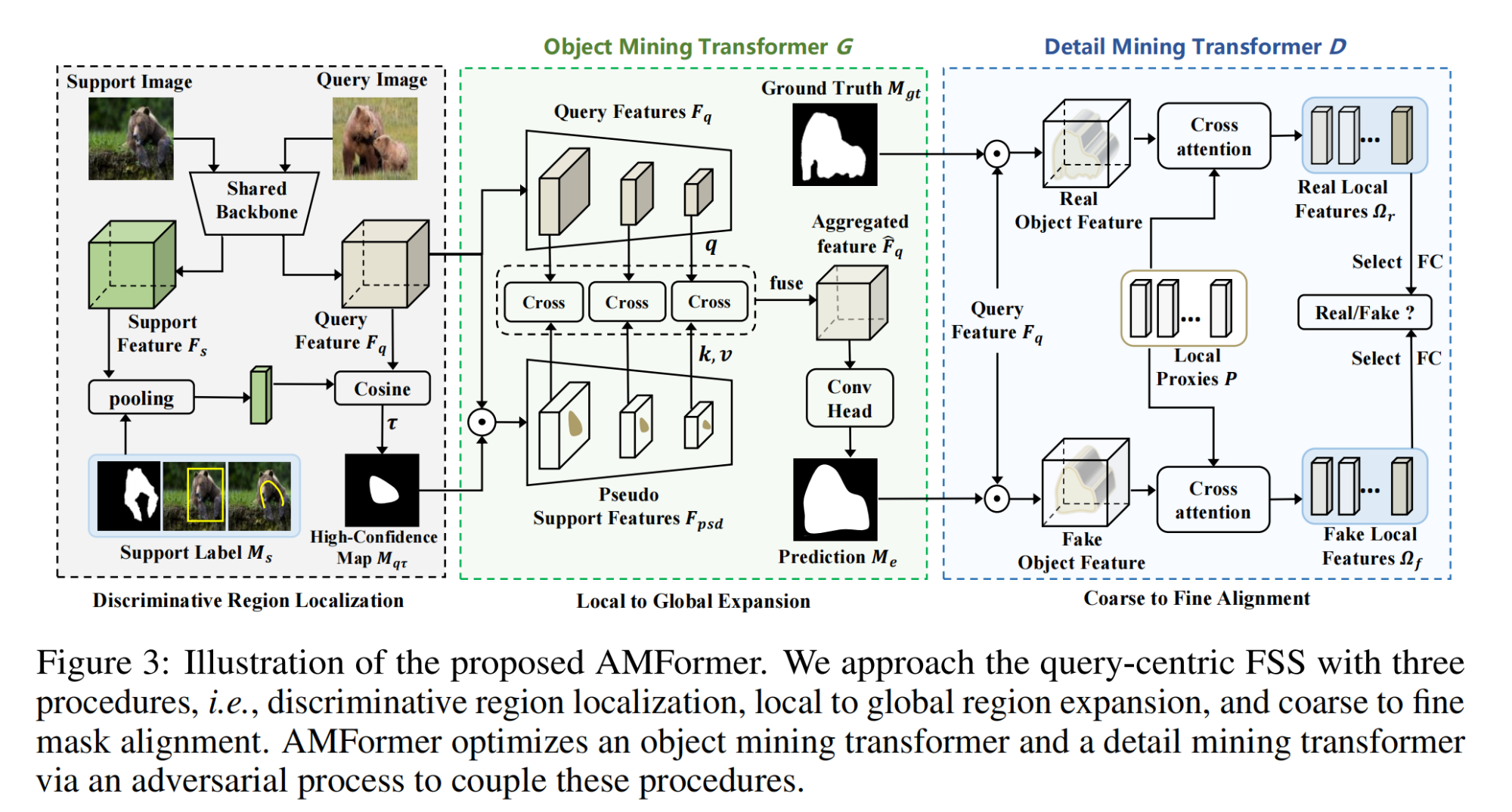
5.【图像分割】(NeurIPS2023)Focus on Query: Adversarial Mining Transformer for Few-Shot Segmentation
6.【语义分割】A Simple Recipe for Language-guided Domain Generalized Segmentation
-
开源代码(即将开源):https://github.com/astra-vision/FAMix

7.【视频分割】Betrayed by Attention: A Simple yet Effective Approach for Self-supervised Video Object Segmentation

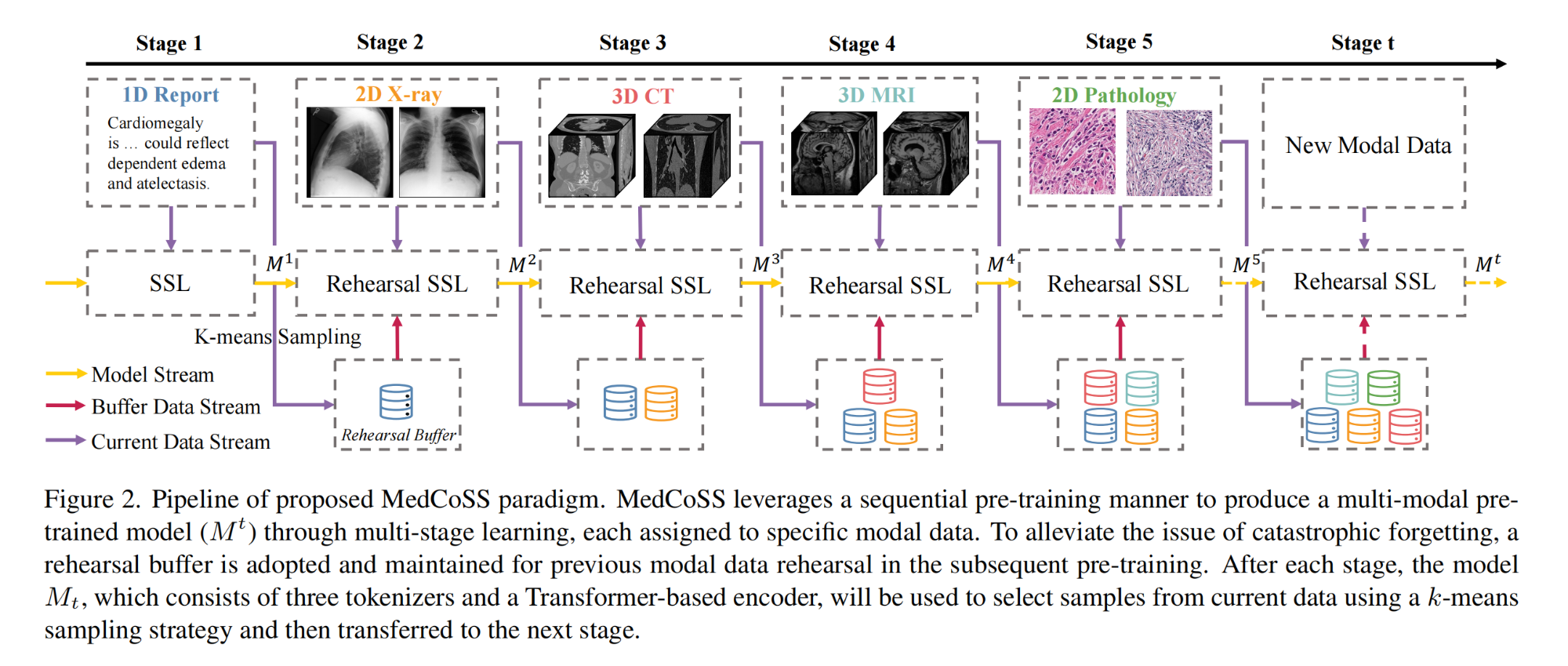
8.【医学图像处理】Continual Self-supervised Learning: Towards Universal Multi-modal Medical Data Representation Learning
-
开源代码(即将开源):https://github.com/yeerwen/MedCoSS
9.【医学图像分类】(WACV2024)PHG-Net: Persistent Homology Guided Medical Image Classification

10.【医学图像分割】Alternate Diverse Teaching for Semi-supervised Medical Image Segmentation
-
开源代码(即将开源):https://github.com/zhenzhao/AD-MT

11.【医学图像分割】U-Net v2: Rethinking the Skip Connections of U-Net for Medical Image Segmentation

12.【动作识别】AdaFocus: Towards End-to-end Weakly Supervised Learning for Long-Video Action Understanding
-
工程主页:AdaFocus: Towards End-to-end Weakly Supervised Learning for Long-Video Action Understanding
-
代码即将开源

13.【多模态】CG3D: Compositional Generation for Text-to-3D via Gaussian Splatting

14.【多模态】VIM: Probing Multimodal Large Language Models for Visual Embedded Instruction Following
-
工程主页:VIM: Probing Multimodal Large Language Models for Visual Embedded Instruction Following
-
开源代码(即将开源):https://github.com/VIM-Bench/VIM_TOOL

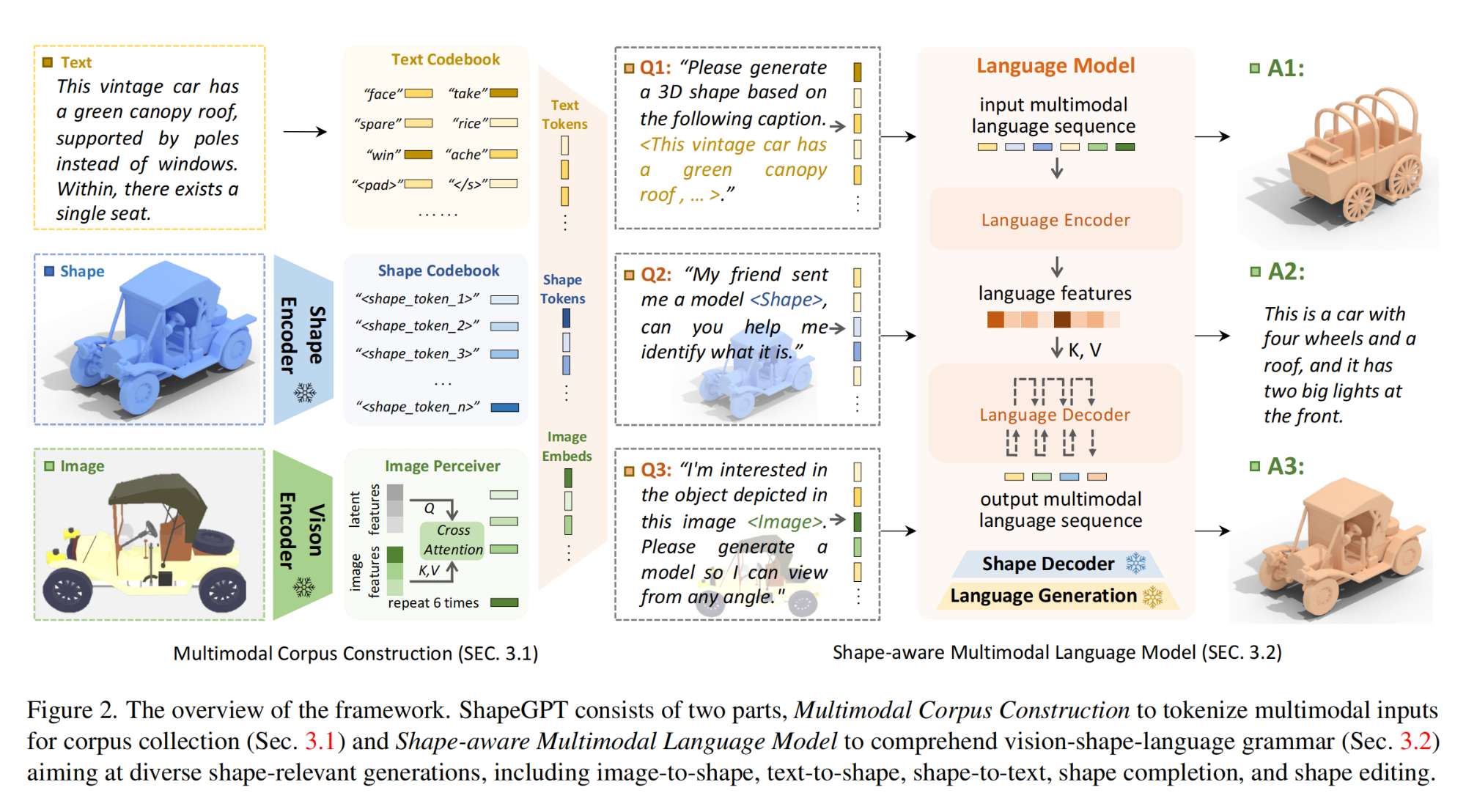
15.【多模态】ShapeGPT: 3D Shape Generation with A Unified Multi-modal Language Model
-
工程主页:ShapeGPT
-
开源代码(即将开源):https://github.com/OpenShapeLab/ShapeGPT
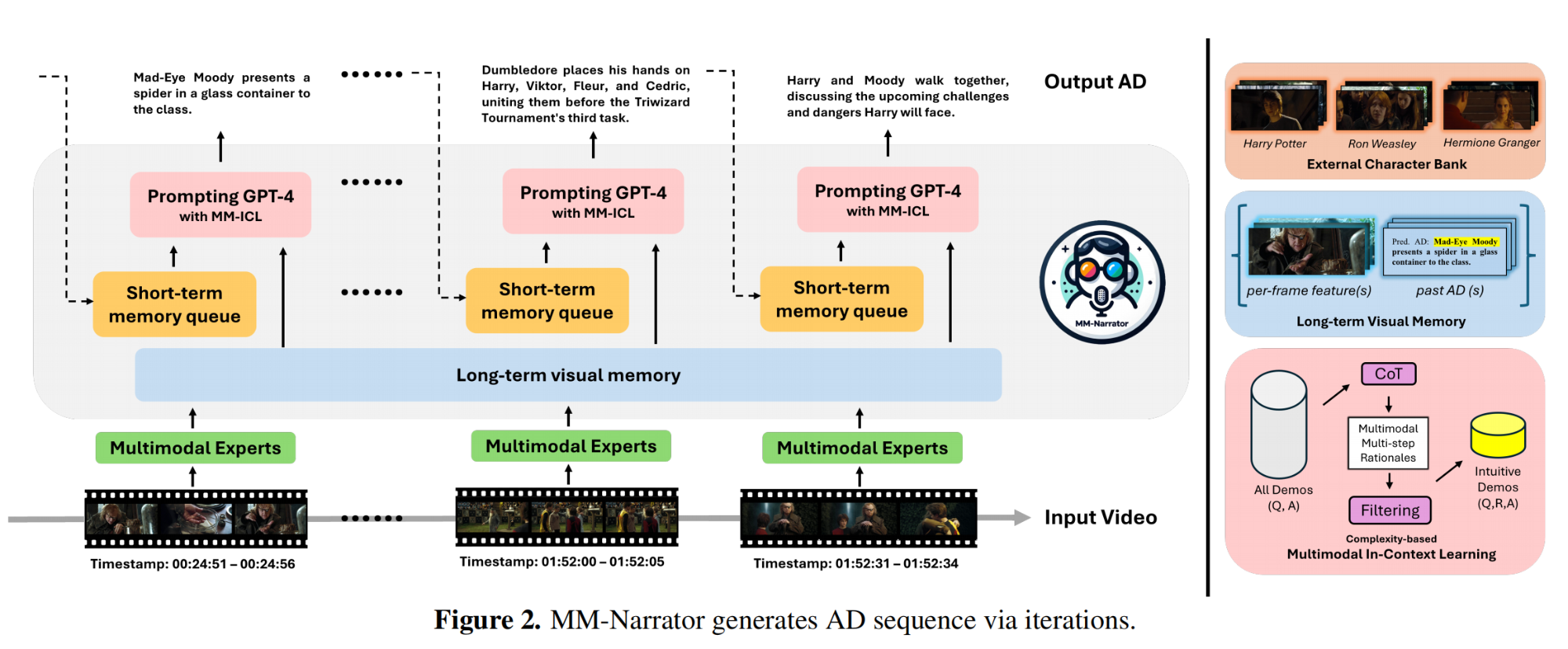
16.【多模态】MM-Narrator: Narrating Long-form Videos with Multimodal In-Context Learning
17.【多模态】VITATECS: A Diagnostic Dataset for Temporal Concept Understanding of Video-Language Models

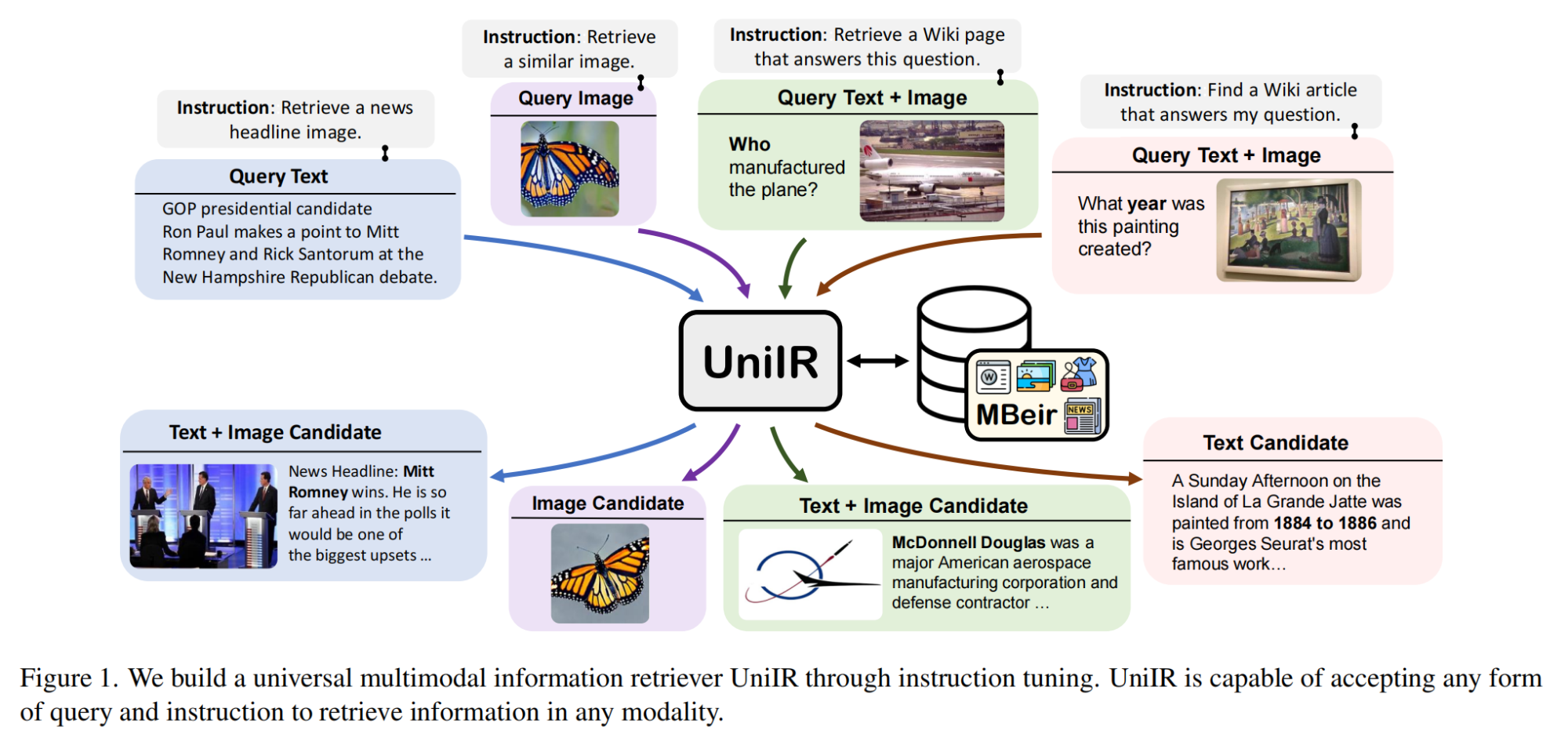
18.【多模态】UniIR: Training and Benchmarking Universal Multimodal Information Retrievers
19.【多模态】SEED-Bench-2: Benchmarking Multimodal Large Language Models

20.【多模态】Beyond Sole Strength: Customized Ensembles for Generalized Vision-Language Models

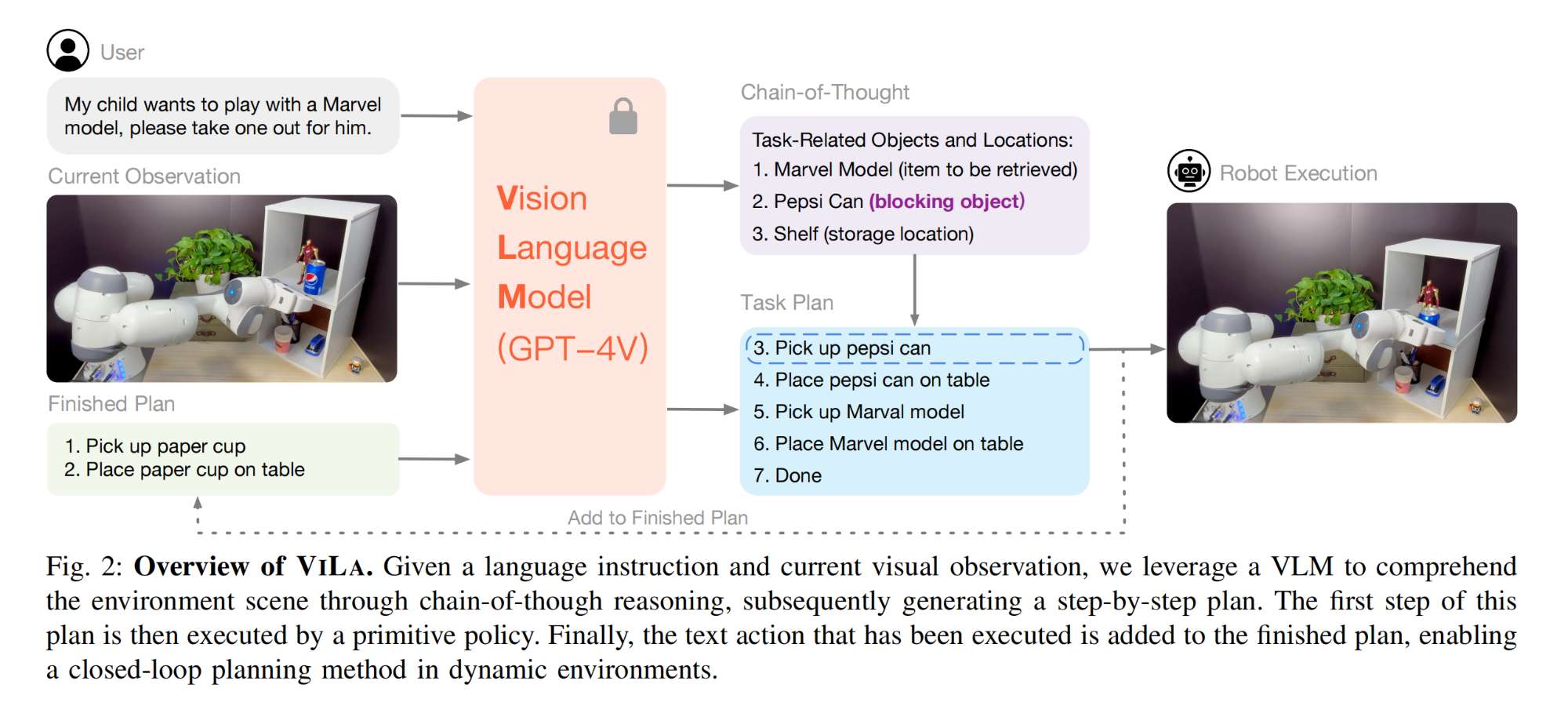
21.【多模态】Look Before You Leap: Unveiling the Power of GPT-4V in Robotic Vision-Language Planning
-
工程主页:ViLa
-
代码即将开源
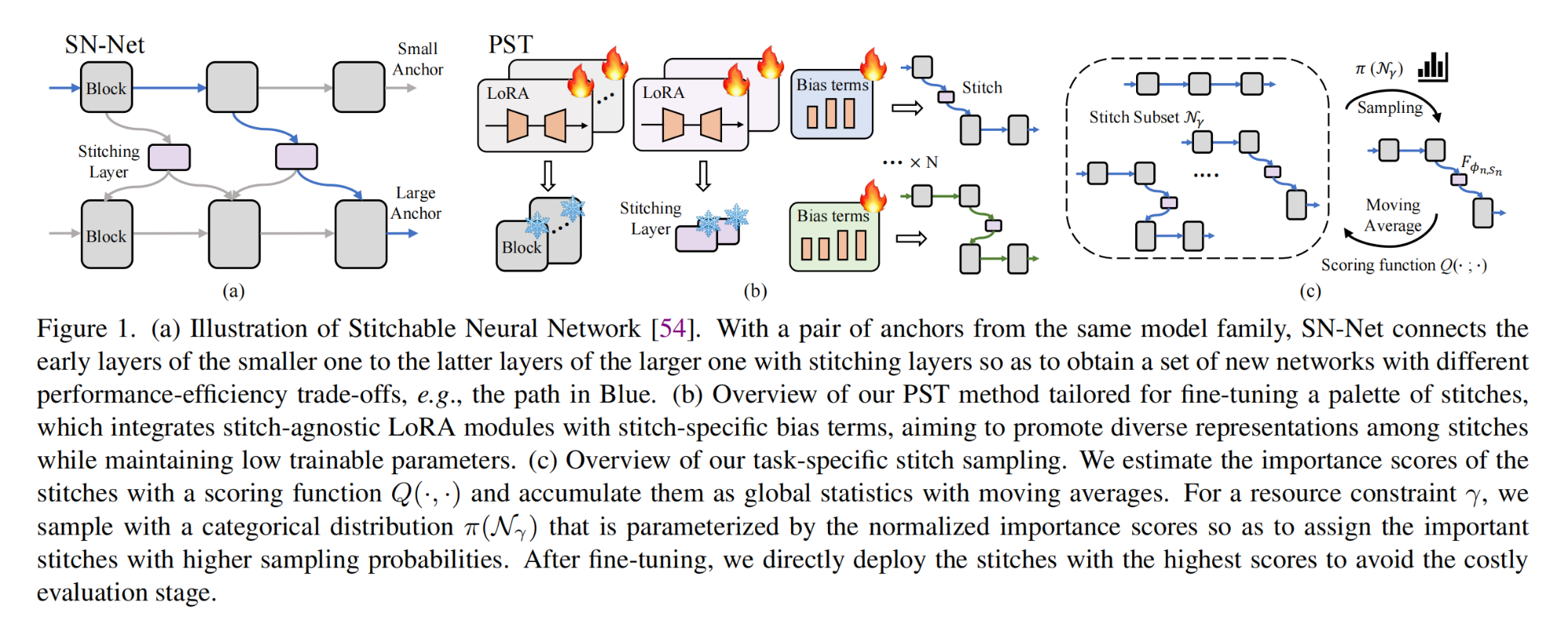
22.【多模态】Efficient Stitchable Task Adaptation
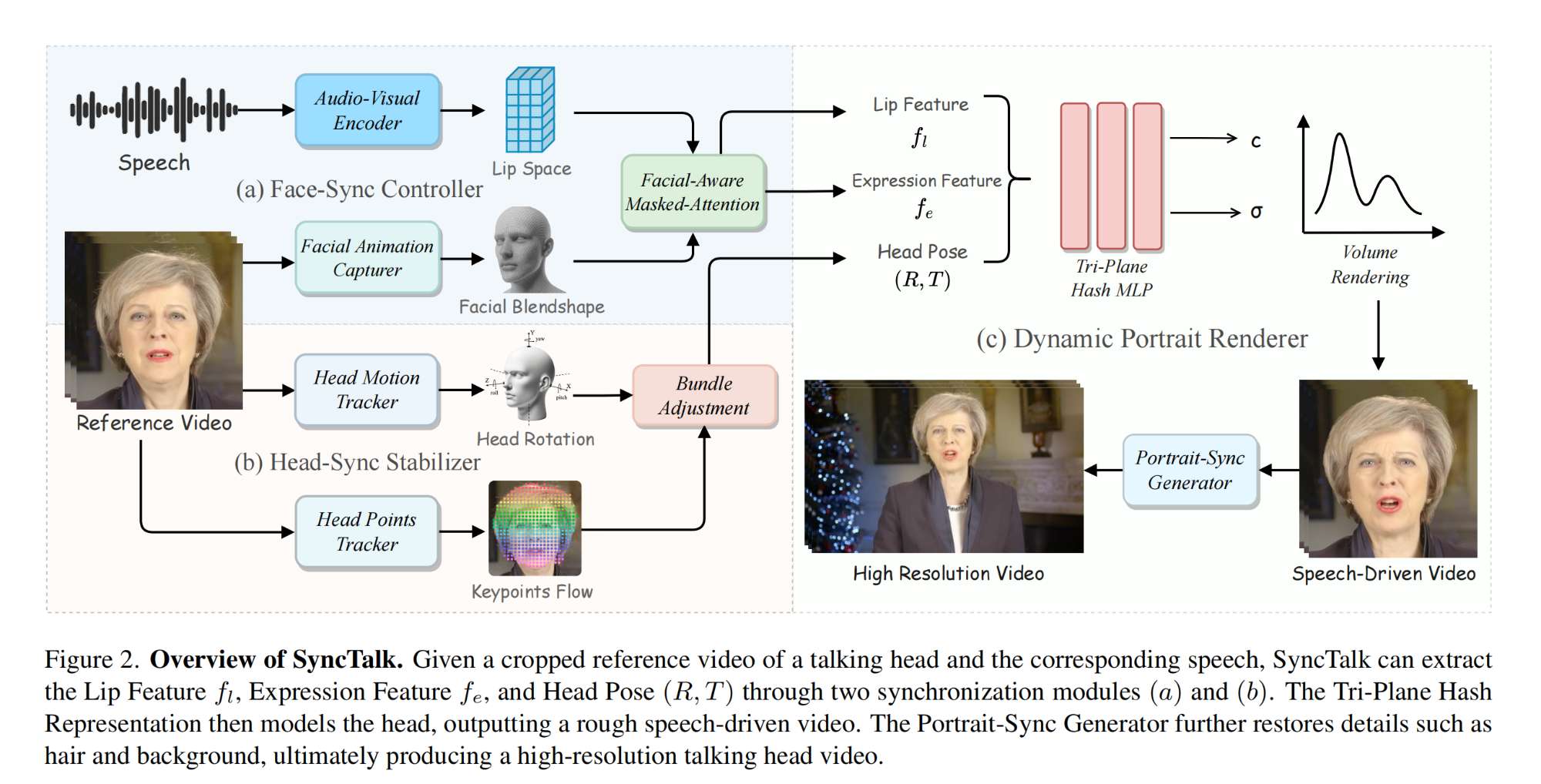
23.【数字人】SyncTalk: The Devil is in the Synchronization for Talking Head Synthesis
-
工程主页:SyncTalk
-
开源代码(即将开源):https://github.com/ziqiaopeng/SyncTalk
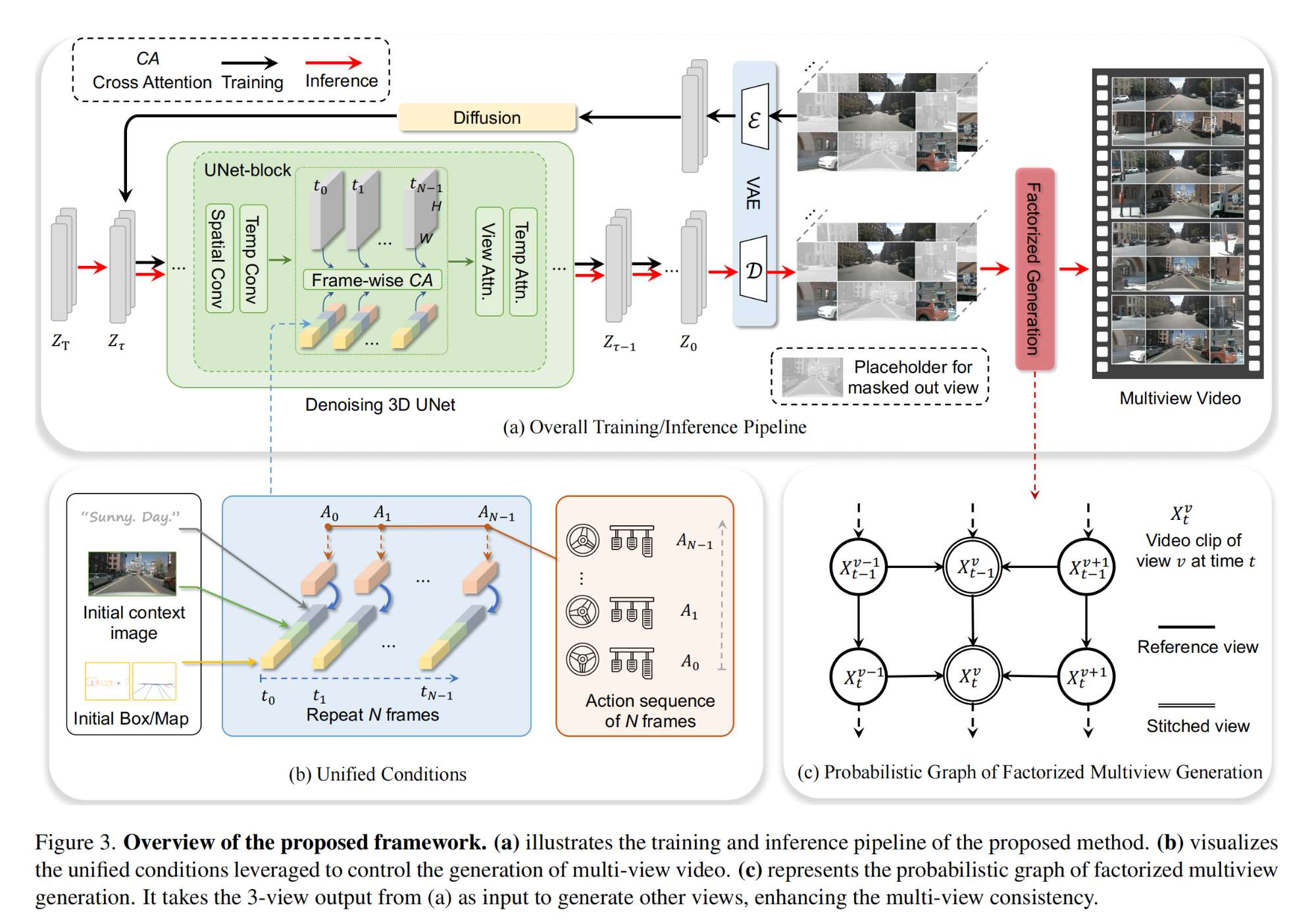
24.【自动驾驶】Driving into the Future: Multiview Visual Forecasting and Planning with World Model for Autonomous Driving
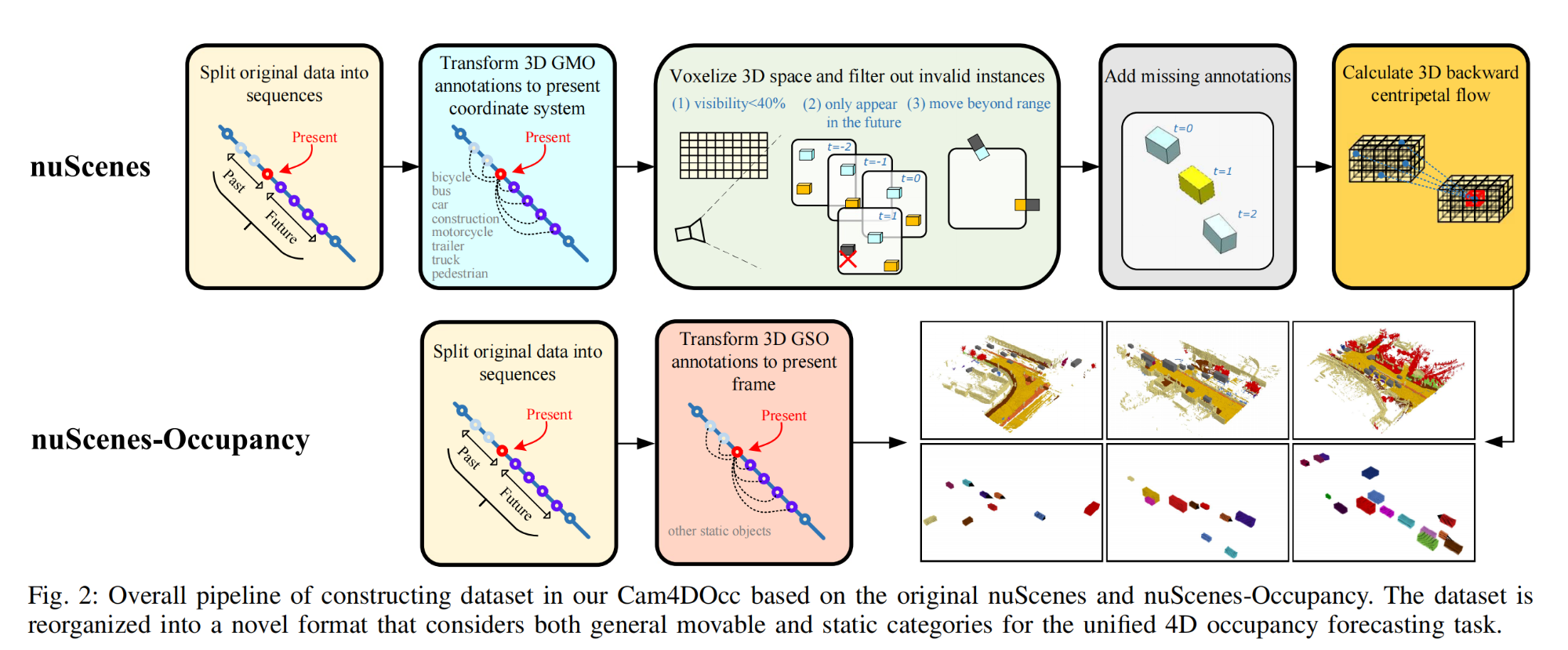
25.【自动驾驶:Occupancy Prediction】Cam4DOcc: Benchmark for Camera-Only 4D Occupancy Forecasting in Autonomous Driving Applications
26.【Diffusion】Do text-free diffusion models learn discriminative visual representations?

27.【Diffusion】SPiC-E : Structural Priors in 3D Diffusion Models using Cross Entity Attention
-
工程主页:SPiC·E: Structural Priors in 3D Diffusion Models using Cross-Entity Attention
-
开源代码(即将开源):https://github.com/TAU-VAILab/spic-e
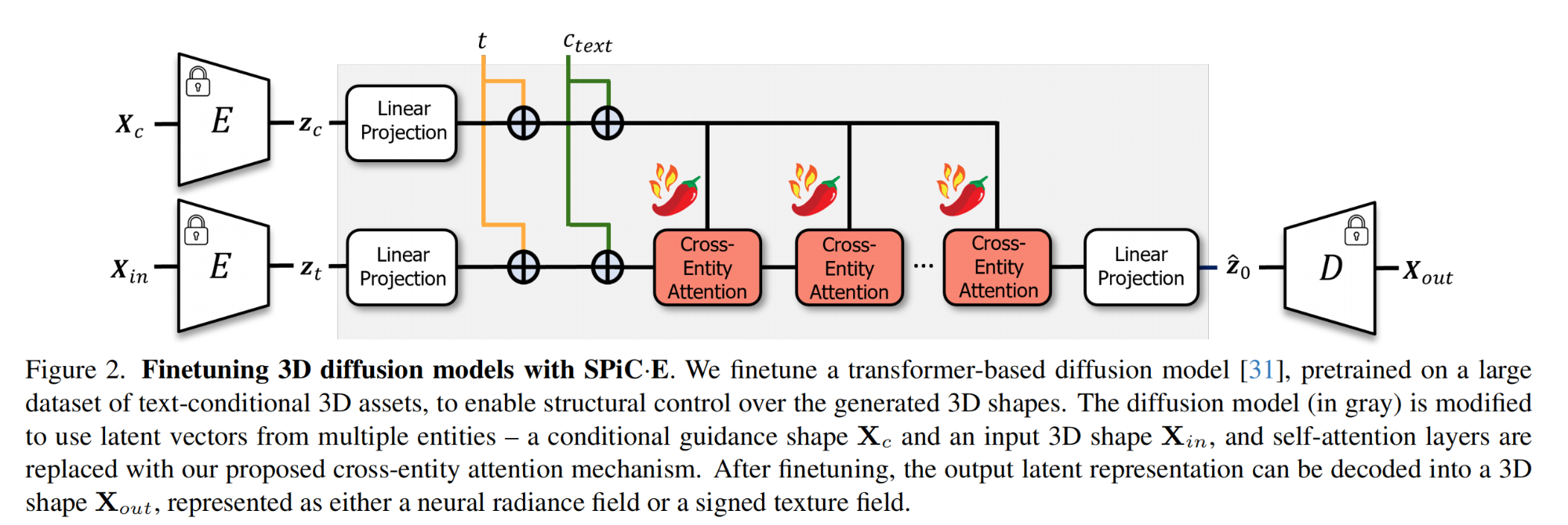
28.【Diffusion】Smooth Video Synthesis with Noise Constraints on Diffusion Models for One-shot Video Tuning

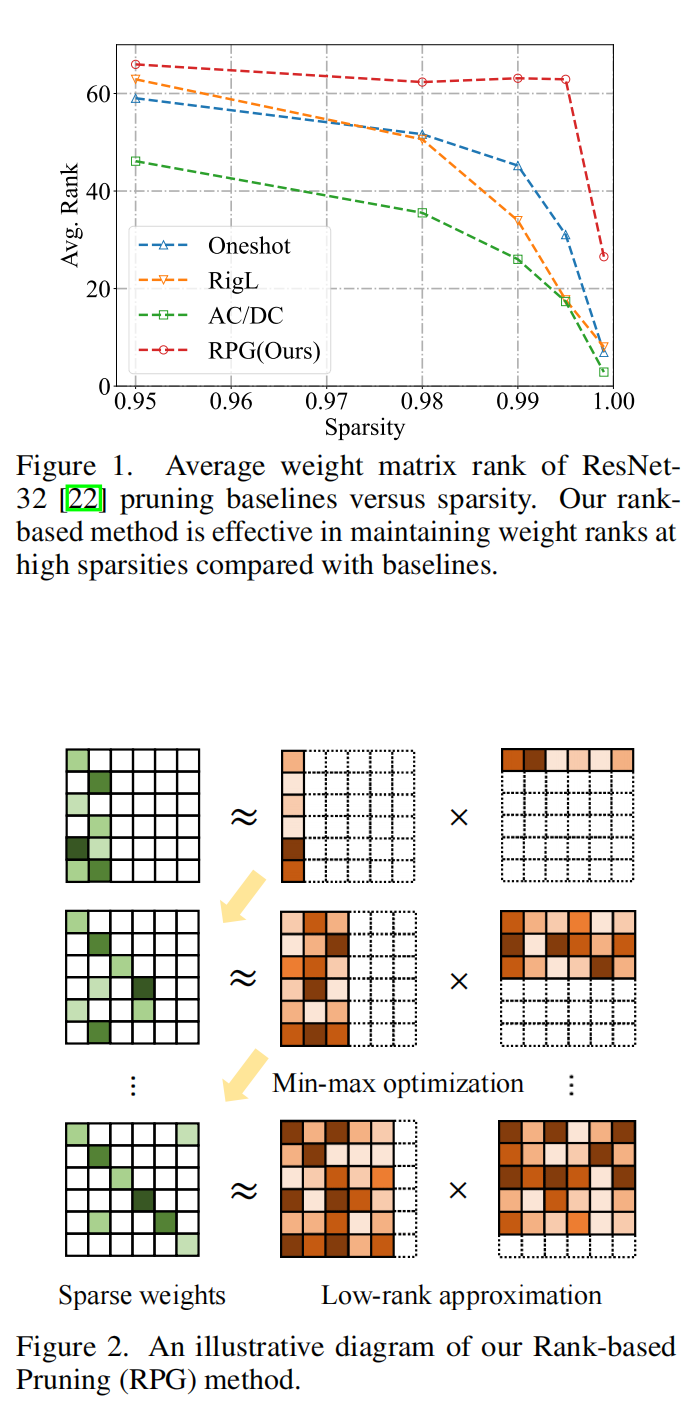
29.【网络剪枝】Towards Higher Ranks via Adversarial Weight Pruning
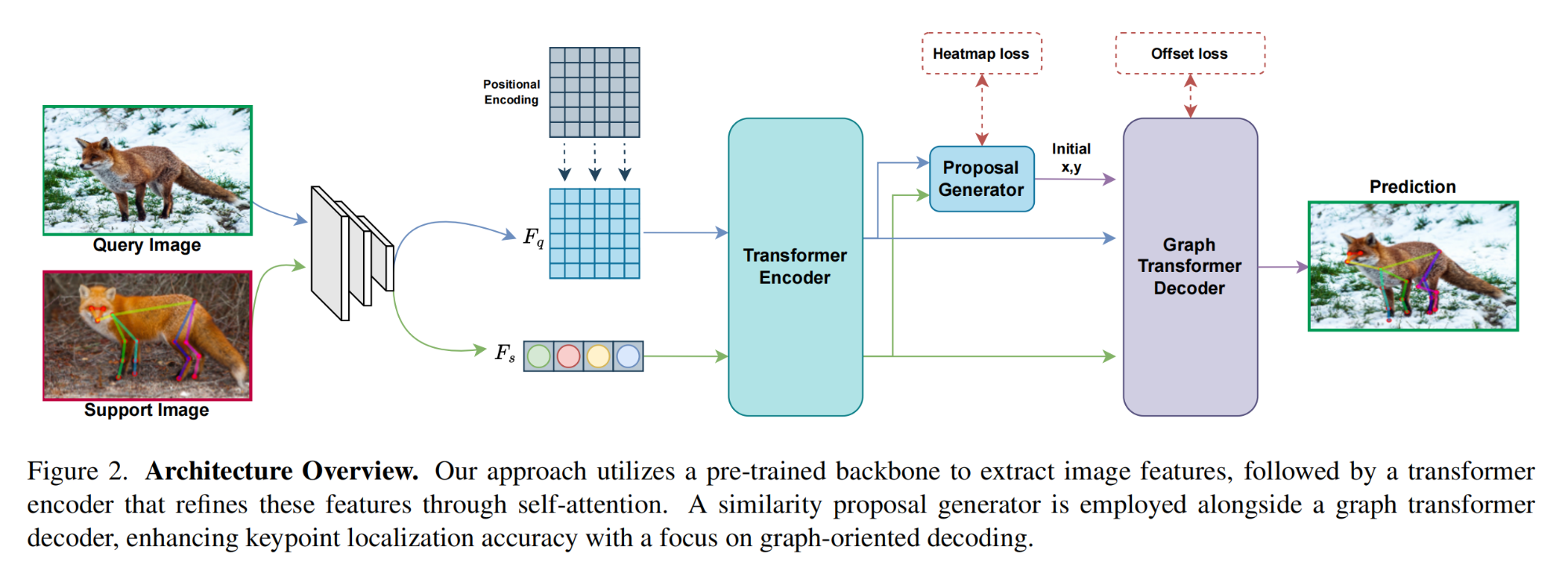
30.【姿态估计】Pose Anything: A Graph-Based Approach for Category-Agnostic Pose Estimation
-
工程主页:Pose Anything: A Graph-Based Approach for Category-Agnostic Pose Estimation
-
开源代码(即将开源):https://github.com/orhir/PoseAnything
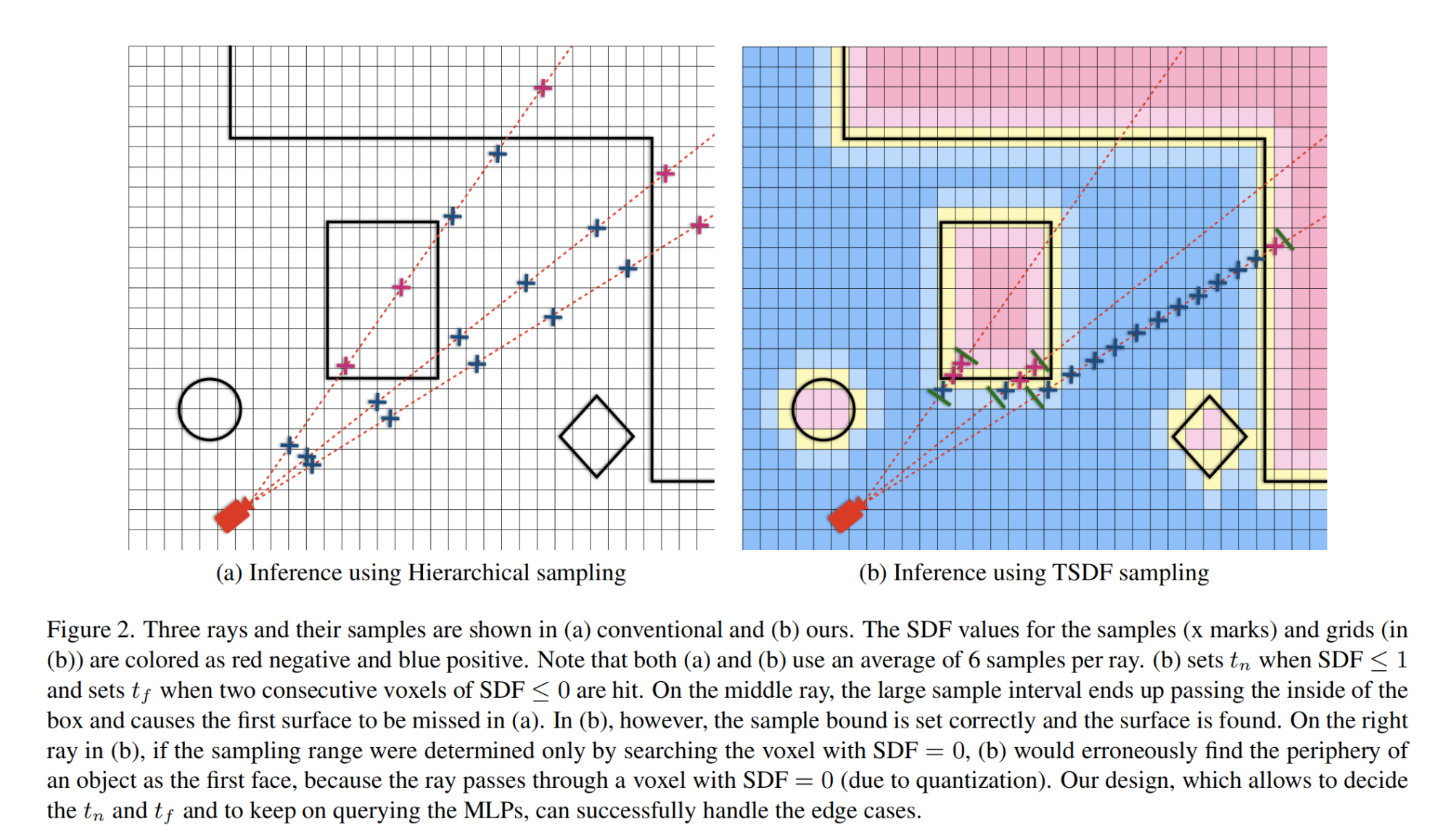
31.【NeRF】TSDF-Sampling: Efficient Sampling for Neural Surface Field using Truncated Signed Distance Field
-
工程主页:TSDF-Sampling: Efficient Sampling for Neural Surface Field using Truncated Signed Distance Field
-
代码即将开源
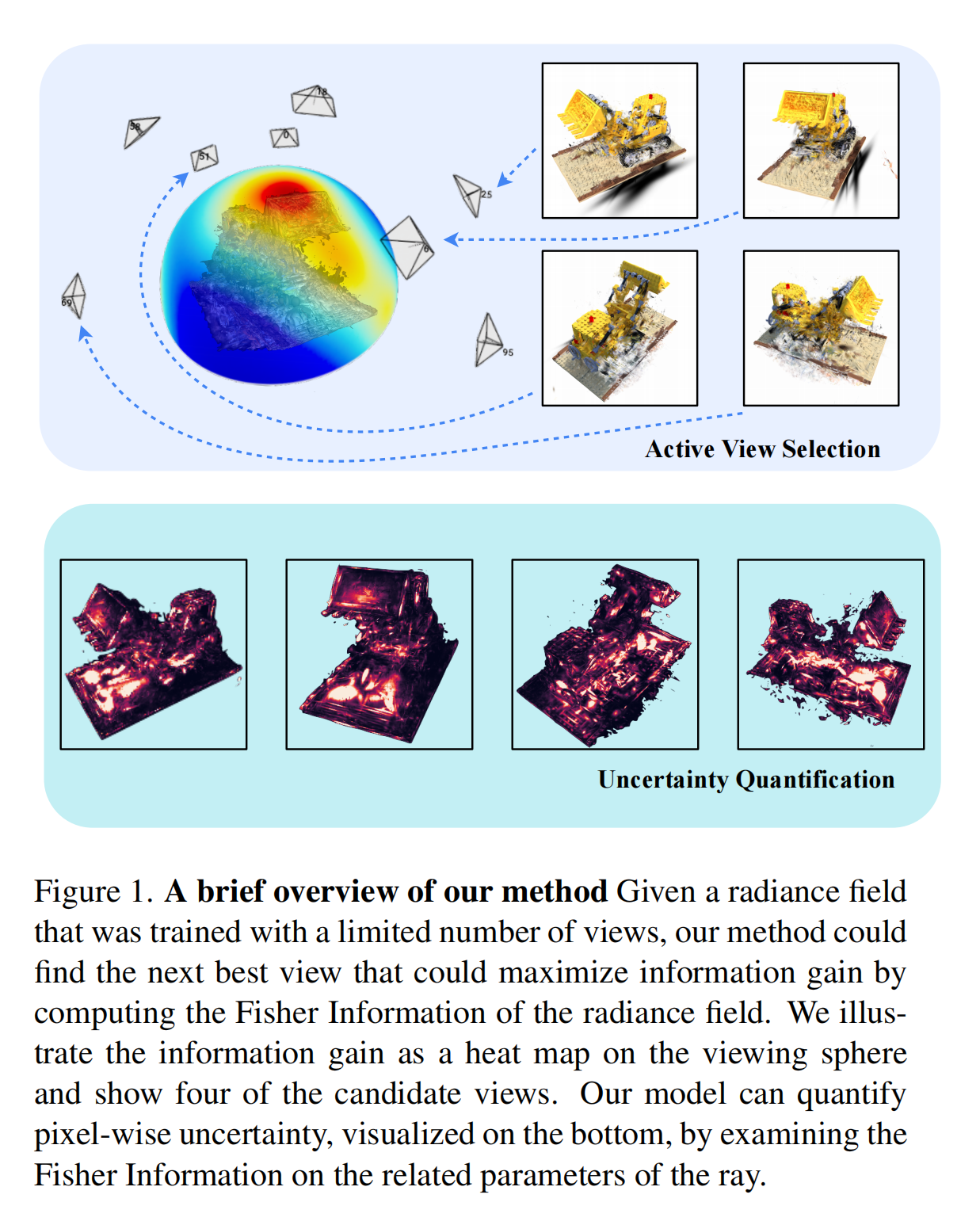
32.【NeRF】FisherRF: Active View Selection and Uncertainty Quantification for Radiance Fields using Fisher Information
-
开源代码(即将开源):https://github.com/JiangWenPL/FisherRF
33.【图像合成】When StyleGAN Meets Stable Diffusion: a Adapter for Personalized Image Generation

34.【视频生成】Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation
-
工程主页:Animate Anyone
-
开源代码(即将开源):https://github.com/HumanAIGC/AnimateAnyone

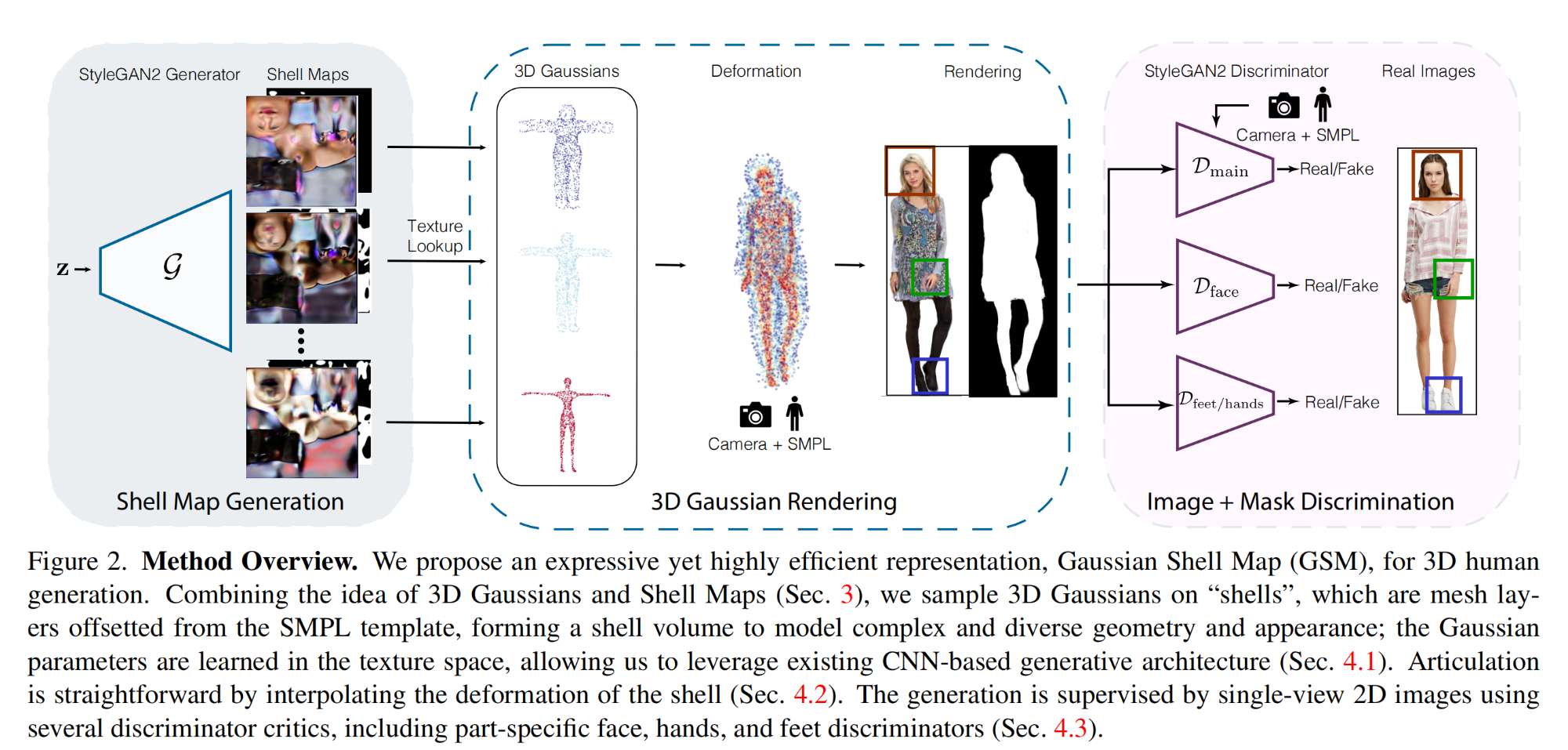
35.【人体重建】Gaussian Shell Maps for Efficient 3D Human Generation
-
开源代码(即将开源):https://github.com/computational-imaging/GSM
论文已打包,下载链接
CV计算机视觉交流群
群内包含目标检测、图像分割、目标跟踪、Transformer、多模态、NeRF、GAN、缺陷检测、显著目标检测、关键点检测、超分辨率重建、SLAM、人脸、OCR、生物医学图像、三维重建、姿态估计、自动驾驶感知、深度估计、视频理解、行为识别、图像去雾、图像去雨、图像修复、图像检索、车道线检测、点云目标检测、点云分割、图像压缩、运动预测、神经网络量化、网络部署等多个领域的大佬,不定期分享技术知识、面试技巧和内推招聘信息。
想进群的同学请添加微信号联系管理员:PingShanHai666。添加好友时请备注:学校/公司+研究方向+昵称。
推荐阅读:
CV计算机视觉每日开源代码Paper with code速览-2023.11.30
CV计算机视觉每日开源代码Paper with code速览-2023.11.29
CV计算机视觉每日开源代码Paper with code速览-2023.11.28

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐
 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)