
阿里开源中间件Canal入门学习笔记(一)
前言知道的越多,不知道的就越多对最近在学习的canal过程做个记录。学习一门技术,一定会从下面几个方面入手前言一、什么是Canal二、canal能做什么三、如何搭建canal3.1 首先有一个MySql服务四、 Java客户端如何操作带着这些问题,我自己做了下学习的笔记,分享大家仅供参考。一、什么是Canal首先看下canal官网的介绍canal [kə’næl],译意为水道/管道/沟渠,主要用途
前言
知道的越多,不知道的就越多
对最近在学习的canal过程做个记录。
带着这些问题,我自己做了下学习的笔记,分享大家仅供参考。
一、什么是Canal
首先看下canal官网的介绍
canal [kə’næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
其中有几个关键字眼:增量日志解析、增量数据订阅、增量数据消费。
好像我们自身的业务中,有时候,也会涉及到对增量数据的处理,这种处理,有时候是涉及到业务的处理,有时候只是对数据的单纯处理。
涉及到了数据,就不单单是涉及到了关系型数据库。有时候还需要同步到到Redis、ES中,这个时候,就希望数据之间,尽可能保持“实时同步”。
二、canal能做什么
官方给出的几种,基于日志增量订阅和消费的业务:
基于日志增量订阅和消费的业务包括
1、数据库镜像
2、数据库实时备份
3、索引构建和实时维护(拆分异构索引、倒排索引等)
4、业务 cache 刷新
5、带业务逻辑的增量数据处理
学习canal之前,需要了解下数据库的读写分离、主从同步的原理。因为canal的工作原理就是将自己伪装成一个数据库的从库,来读取binlog。
数据库的读写分离、主从复制不做展开介绍,canal官方也有对主备复制原理有介绍。
canal工作原理
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
三、如何搭建canal
3.1 首先有一个MySql服务
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
安装教程,网上很多。
安装好MySQL后,需要查看设置是否打开了binlog模式。可参考我的其他文章
1、Win10命令操作连接mysql
2、win10下mysql 开启BINLOG
完成上面2个步骤后,可以查看正在写入的Binlog文件信息

到这里,MySQL服务这边的配置这就搞定了,比较简单。
3.2 安装canal
canal.admin:canal提供web ui 进行Server管理、Instance管理。
canal.deployer:canal实例。后面演示效果时候,需要开启这个服务。

下载解压缩 canal.deployer-1.1.5.tar.gz
打开配置文件 {下载路径}/canal/conf/example/instance.properties 配置信息如下
#################################################
## mysql serverId , v1.0.26+ will autoGen
# canal.instance.mysql.slaveId=0
# enable gtid use true/false
canal.instance.gtidon=false
# position info
canal.instance.master.address=localhost:3306
canal.instance.master.journal.name=BZD-21631-bin.000006
canal.instance.master.position=156
canal.instance.master.timestamp=
canal.instance.master.gtid=
# rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId=
# table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=
# username/password
canal.instance.dbUsername=root
canal.instance.dbPassword=12345678
canal.instance.connectionCharset = UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==
# table regex
canal.instance.filter.regex=.*\\..*
# table black regex
canal.instance.filter.black.regex=mysql\\.slave_.*
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch
# mq config
canal.mq.topic=example
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..*
canal.mq.partition=0
# hash partition config
#canal.mq.partitionsNum=3
#canal.mq.partitionHash=test.table:id^name,.*\\..*
#canal.mq.dynamicTopicPartitionNum=test.*:4,mycanal:6
#################################################
canal.instance.master.journal.name=BZD-21631-bin.000006
canal.instance.master.position=156
这两个配置,跟上面通过show master status; 命令操作后的数据,保持一致。
我这里用的是win10,直接在bin目录下找到 startup.bat进行启动。
如果启动报错
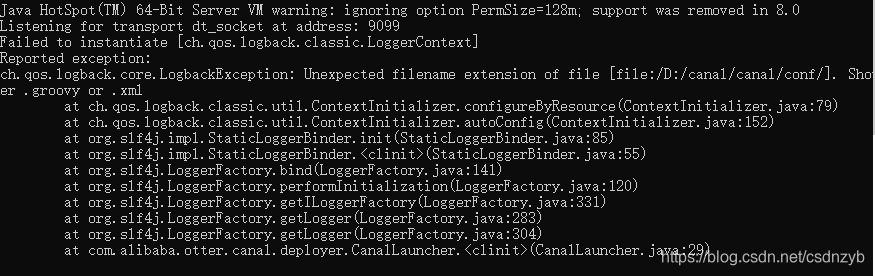
出现这个问题,编辑修改下 startup.bat。删除掉
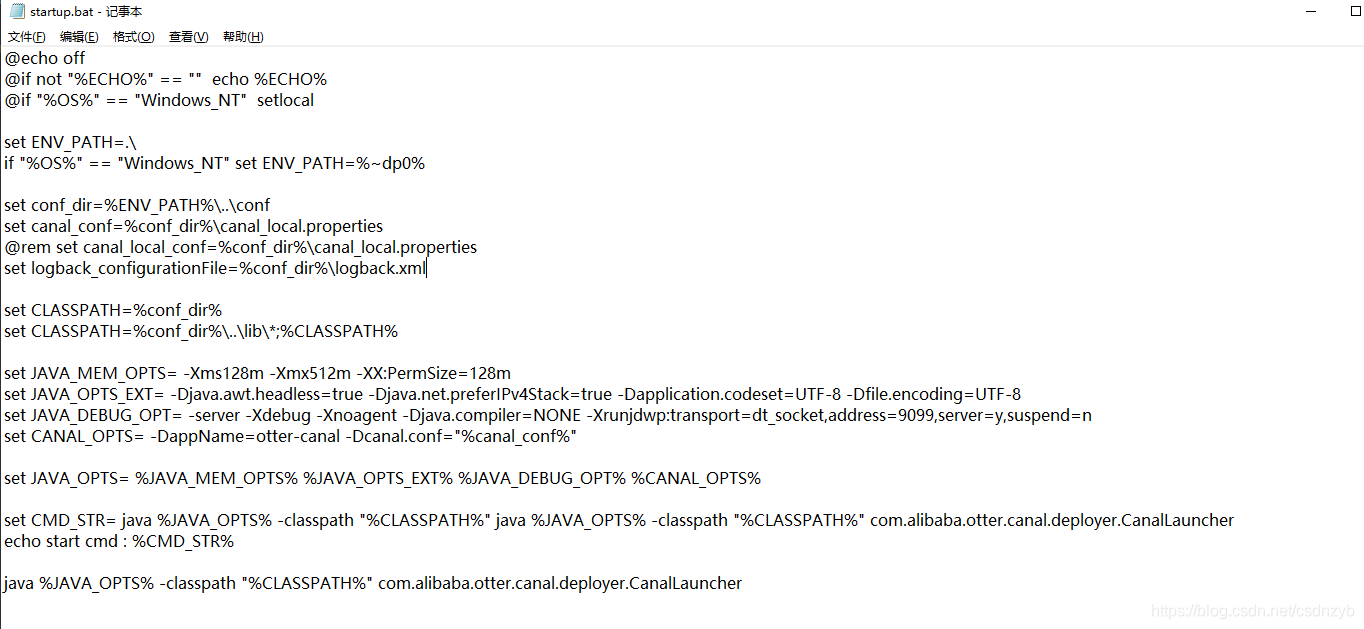
-Dlogback.configurationFile="%logback_configurationFile%
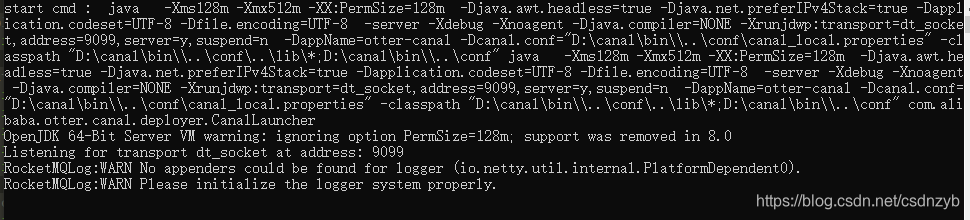
重新执行 startup.bat进行启动,如下图所示
四、 Java客户端如何操作
我项目搭建使用的是Springboot + gradle 的形式,所以我引入的配置文件为:implementation group: 'com.alibaba.otter', name: 'canal.client', version: '1.1.4'。
创建CanalClient.class
package com.nacos.test.config;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.CanalEntry.RowChange;
import com.alibaba.otter.canal.protocol.CanalEntry.RowData;
import com.alibaba.otter.canal.protocol.Message;
import com.google.protobuf.InvalidProtocolBufferException;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.stereotype.Component;
import java.net.InetSocketAddress;
import java.util.List;
import java.util.Queue;
import java.util.concurrent.ConcurrentLinkedQueue;
/**
* @author Mr.SoftRock
* @Date 2021/7/6 15:28
**/
@Component
public class CanalClient implements InitializingBean {
//sql队列
private Queue<String> SQL_QUEUE = new ConcurrentLinkedQueue<>();
@Override
public void afterPropertiesSet() throws Exception {
//第一步:与canal进行连接
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("localhost",
11111), "example", "", "");
int batchSize = 1000;
try {
connector.connect();
//第二步:开启订阅 表达式为订阅数据库下全部的表
connector.subscribe(".*\\..*");
connector.rollback();
try {
//第三步:循环订阅
while (true) {
//尝试从master那边拉取数据
//每次读取1000条
Message message = connector.getWithoutAck(batchSize);
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
Thread.sleep(1000);
} else {
dataHandle(message.getEntries());
}
connector.ack(batchId);
// 当队列里面堆积的sql大于一定数值的时候就模拟执行
if (SQL_QUEUE.size() >= 1) {
executeQueueSql();
}
}
} catch (InterruptedException e) {
e.printStackTrace();
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
} finally {
connector.disconnect();
}
}
/**
* 模拟执行队列里面的sql语句
* 打印出执行的sql
*/
public void executeQueueSql() {
int size = SQL_QUEUE.size();
for (int i = 0; i < size; i++) {
String sql = SQL_QUEUE.poll();
System.out.println("[sql]----> " + sql);
}
}
/**
* 数据处理
*
* @param entrys
*/
private void dataHandle(List<CanalEntry.Entry> entrys) throws InvalidProtocolBufferException {
for (CanalEntry.Entry entry : entrys) {
// step1:拆解entry实体
CanalEntry.Header header = entry.getHeader();
CanalEntry.EntryType entryType = entry.getEntryType();
if (CanalEntry.EntryType.ROWDATA == entryType) {
CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(entry.getStoreValue());
CanalEntry.EventType eventType = rowChange.getEventType();
//如果是查询或者是DDL语句,则直接打印输出
if (eventType == CanalEntry.EventType.QUERY || rowChange.getIsDdl()) {
System.out.println("执行了查询语句:[{}]" + rowChange.getSql());
} else if (eventType == CanalEntry.EventType.DELETE) {
saveDeleteSql(entry);
} else if (eventType == CanalEntry.EventType.UPDATE) {
saveUpdateSql(entry);
} else if (eventType == CanalEntry.EventType.INSERT) {
saveInsertSql(entry);
}
}
}
}
/**
* 保存更新语句
*
* @param entry
*/
private void saveUpdateSql(CanalEntry.Entry entry) {
try {
RowChange rowChange = RowChange.parseFrom(entry.getStoreValue());
List<RowData> rowDatasList = rowChange.getRowDatasList();
for (RowData rowData : rowDatasList) {
List<CanalEntry.Column> newColumnList = rowData.getAfterColumnsList();
StringBuffer sql = new StringBuffer("update " + entry.getHeader().getTableName() + " set ");
for (int i = 0; i < newColumnList.size(); i++) {
sql.append(" " + newColumnList.get(i).getName()
+ " = '" + newColumnList.get(i).getValue() + "'");
if (i != newColumnList.size() - 1) {
sql.append(",");
}
}
sql.append(" where ");
List<CanalEntry.Column> oldColumnList = rowData.getBeforeColumnsList();
for (CanalEntry.Column column : oldColumnList) {
if (column.getIsKey()) {
//暂时只支持单一主键
sql.append(column.getName() + "=" + column.getValue());
break;
}
}
SQL_QUEUE.add(sql.toString());
}
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
}
/**
* 保存删除语句
*
* @param entry
*/
private void saveDeleteSql(CanalEntry.Entry entry) {
try {
RowChange rowChange = RowChange.parseFrom(entry.getStoreValue());
List<RowData> rowDatasList = rowChange.getRowDatasList();
for (RowData rowData : rowDatasList) {
List<CanalEntry.Column> columnList = rowData.getBeforeColumnsList();
StringBuffer sql = new StringBuffer("delete from " + entry.getHeader().getTableName() + " where ");
for (CanalEntry.Column column : columnList) {
if (column.getIsKey()) {
//暂时只支持单一主键
sql.append(column.getName() + "=" + column.getValue());
break;
}
}
SQL_QUEUE.add(sql.toString());
}
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
}
/**
* 保存插入语句
*
* @param entry
*/
private void saveInsertSql(CanalEntry.Entry entry) {
try {
CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(entry.getStoreValue());
List<RowData> rowDatasList = rowChange.getRowDatasList();
for (RowData rowData : rowDatasList) {
List<CanalEntry.Column> columnList = rowData.getAfterColumnsList();
StringBuffer sql = new StringBuffer("insert into " + entry.getHeader().getTableName() + " (");
for (int i = 0; i < columnList.size(); i++) {
sql.append(columnList.get(i).getName());
if (i != columnList.size() - 1) {
sql.append(",");
}
}
sql.append(") VALUES (");
for (int i = 0; i < columnList.size(); i++) {
sql.append("'" + columnList.get(i).getValue() + "'");
if (i != columnList.size() - 1) {
sql.append(",");
}
}
sql.append(")");
SQL_QUEUE.add(sql.toString());
}
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
}
}
然后启动MySQL,canal server,还有刚创建的springboot项目。
此时我们对一个已经存在的表,执行 insert、update、delete操作。在springboot项目的控制台上就会监听到,并打印输出我们的sql语句。
总结
通过初步的体验,可以感受到,canal对代码的侵入性几乎没有,因为是监听binlog日志去进行数据的同步。
实际项目中,一般不会这样操作,一般的会结合RocketMQ\Kafka 、ES、Redis去做。
Canal Kafka RocketMQ QuickStart
实际上canal可以通过配置,在监听到binlog日志数据时,向mq发送消息。
canal的部署是支持集群部署的,是需要配合ZK去进行一个集群的管理。
canal也有一个web管理页面,进行集群管理和配置。
初步体验canal的笔记就记录到这里。
好记性不如烂笔头。
下一篇会写canal的web管理页面搭建,配置RocketMq, 同步数据到Redis小demo。
参考文章传送门:
超详细的Canal入门,看这篇就够了!
阿里开源MySQL中间件Canal快速入门

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)