
F-Cooper: 基于 3D 点云特征的自动驾驶车辆边缘计算系统的协作感知
提出了一种基于点云特征的协同感知框架(F-Cooper):1)利用特征级融合实现端到端的 3D 目标检测,特征级数据传输不会有网络拥塞的风险,可实现实时边缘计算和低通信延迟;2)除了能够提高检测精度外,特征融合所需的数据量仅为原始数据量的百分之一,在数据量和传输时间上都很好地处于 On-Edge 计算和通信的可接受范围内;3)两种融合方案:体素特征融合和空间特征融合。
自动驾驶汽车感知存在的挑战:
1)严重依赖传感器来完善对周围环境的感知,但是车辆使用的数据仅限于来自其自身传感器的数据;
2)车辆(和/或边缘服务器)之间的数据共享受到网络带宽和自动驾驶应用程序的实时约束。虽然融合来自两辆车的原始 LiDAR 数据可以提高汽车检测精度,但实时发送自动驾驶汽车生成的大量 LiDAR 数据具有挑战性。
3 F-COOPER:基于特征的3D协同感知
特征融合
特征级融合成为联网自动驾驶汽车在保持合理通信时间的同时提高检测精度的理想选择。
- 压缩和传输:
a) 原始数据经过特征提取网络处理后,所有无关数据都被过滤掉,特征图只存储被认为有用的数据;
b) 特征融合提供了增强的感知,允许在不丢失检测值的情况下压缩数据;
c) 融合特征图(而不是原始数据)不仅可以解决隐私问题,还可以大大降低网络带宽需求。 - 通用和固有属性:
a) 原始数据将在车载计算设备上,通过基于 CNN 的深度学习网络处理并最终做出驾驶决策。在此过程中,能够有效地获得原始数据的特征图,而无需额外的计算时间或来自板载计算设备的功率;
b) 迄今为止,几乎所有已知的自动驾驶车辆都在使用基于 CNN 的网络,因此特征提取是通用的,在融合之前不需要进一步处理。
F-Cooper
F-Cooper的输入为多个车辆(此处使用两个用于举例说明)的 LiDAR 数据,然后经过体素特征编码(VFE)层处理生成体素特征。(面临等距位置对齐的问题时,需要调整融合算法以适应这种情况,让每辆车发送其 GPS 和 IMU 数据,以对点云融合进行转换计算,即将发送车辆看到的视图转换为接收车辆看到的视图。)
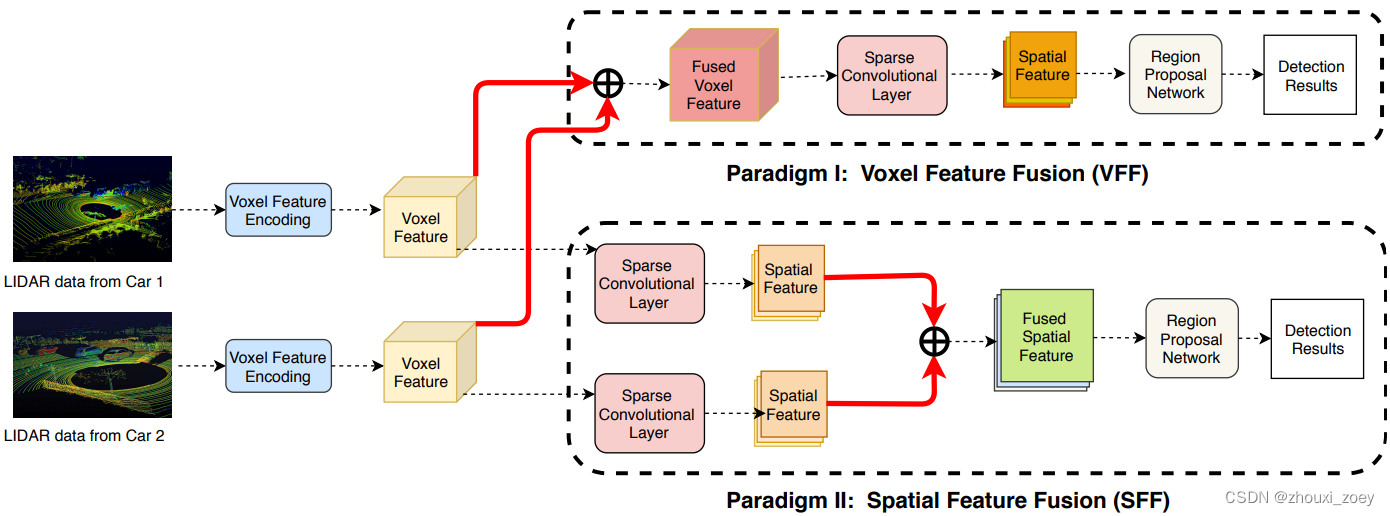
设计了两种特征融合方案以融合两个车辆的 3D 特征:
1)体素特征融合 (VFF):直接融合VFE层生成的特征图,然后通过稀疏卷积层生成空间特征图;
2)空间特征融合 (SFF):首先在单个车辆上获得体素特征通过稀疏卷积层生成空间特征图,然后融合在一起生成最终的特征图。
SFF 可以看作是 VFE 的增强版本,即 SFF 在将单个车辆上可用的体素特征传输到网络之前,提取局部空间特征。
RPN 用于对最终特征图进行对象检测。
3.1 体素特征融合
原始的 LiDAR 检测区域被划分为体素网格,非空体素经过一系列全连接层(VoxelNet 的 VFE 层)变换,转化为固定大小的向量以生成体素特征图。为了内存/计算效率,将非空体素的特征保存到hash表中,其中体素坐标用作hash key,通过搜索hash表实现体素融合。
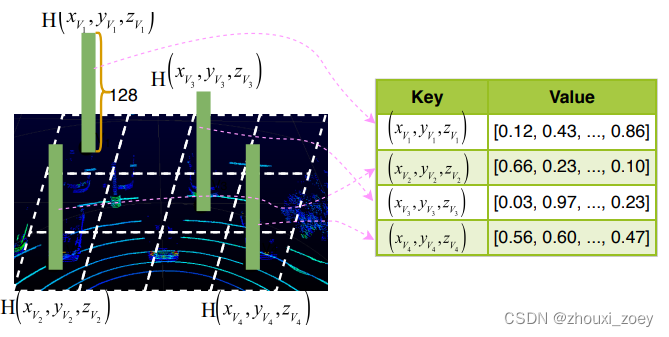
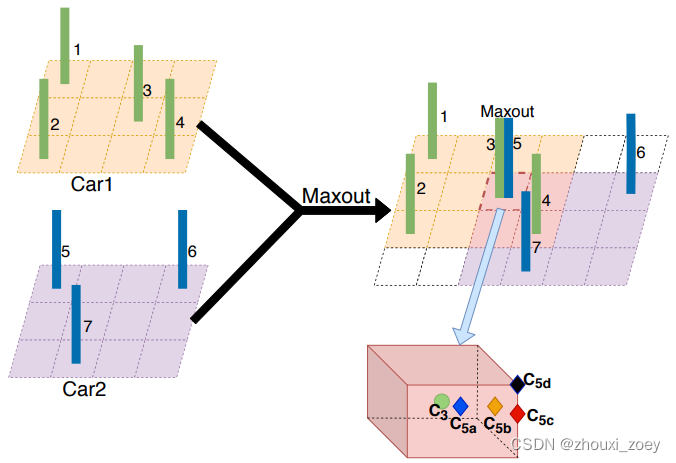
为了融合不同车辆的点云共享相同位置的体素,采用 maxout 方案来突出重要的特征并过滤琐碎的特征,实现更小的数据量。
例如,融合来自两个车辆输入的体素特征:
两辆车位于不同的位置,但它们共享相同的校准 3D 空间,不同的偏移量表示每辆车在3D 校准空间中的相对物理位置。来自 Car 1 的 Voxel 3 和来自 Car 2 的 Voxel 5 共享相同的校准位置,使用 maxout 来比较哪个车辆的体素特征最突出。
对于现实世界的应用来说,实现两辆车的体素完美匹配是不切实际的,即使体素之间的微小偏差也会导致明显不匹配。绿点 C3 表示来自 Car 1的Voxel 3的中心,菱形 C5a、C5b、C5c、C5d表示来自 Car 2 的Voxel 5 的可能中心。
四种不同的不匹配情况:
(a)Voxel 5 的中心C5a,落在Voxel 3 内;
(b)Voxel 5 的中心C5b 落在Voxel 3 的一侧,即Voxel 5 与来自Car 1 的两个体素相连;
(c)C5c 落在Voxel 3 的边缘,这意味着Voxel 5 与来Car 1 的四个体素相交;
(d)C5d 落在Voxel 3 的角点上,Voxel 5 与Car 1 的八个体素连接。
对于情况(a),直接使用 maxout 融合Voxel 3 和Voxel 5;对于情况 (b,c,d),将Voxel 5 与来自Car 1的所有连接体素融合,并将融合结果提供给连接体素。
3.2 空间特征融合
与体素特征相比,空间特征图更稀疏,更容易压缩以进行通信传输。
空间特征图示例:
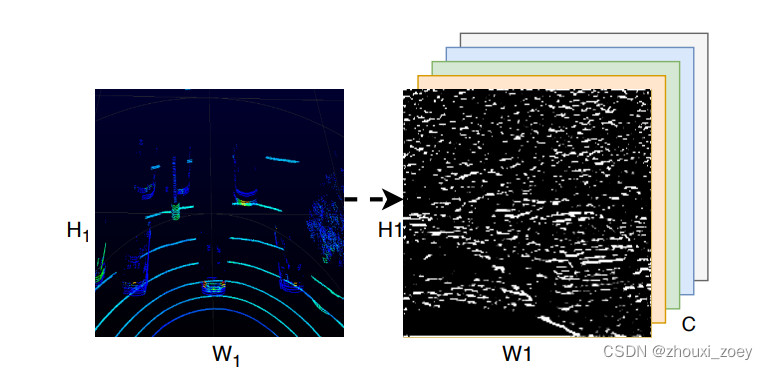
H1和W1表示每辆车检测范围的LiDAR鸟瞰图大小,C(=128)表示通道数。以通道方式融合空间特征,其中通道表示 CNN 中使用的相应内核数。
1)LiDAR 点云帧通过特征学习网络(Voxelnet)生成体素特征图,即一个稀疏张量(大小为 128×10×400×352);
2)为了整合所有体素特征,采用三个 3D 卷积层,依次得到更小、语义更丰富的特征图信息(大小为 64 × 2 × 400 × 352);
3)将其重塑为大小为 (128 × 400 × 352) 的 3D 特征图以适用传统RPN所需的形状。
空间特征融合(SFF)将生成更大的检测范围(大小为 W × H,其中 W > W1,H > H1)的特征图。
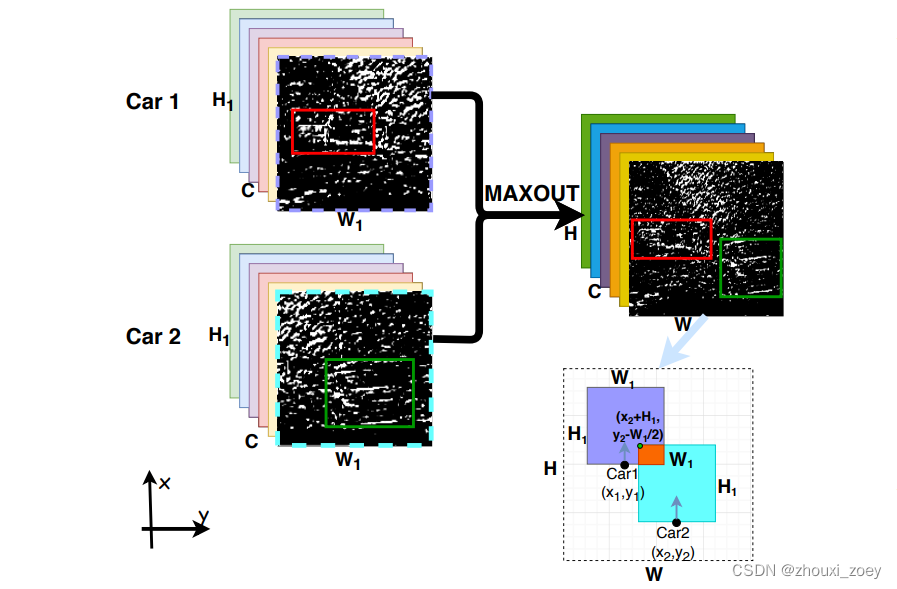
假设 GPS 将 Car 1 的真实位置记录为 (x1,y1),Car 2 记录为 (x2,y2)。那么Car 2生成的特征图左上角可以表示为 (x2 + H1, y2 - W1/ 2) 。假设该角点落在 Car 1生成的的特征图区域内,那么跟VFF一样也使用 maxout 来融合重叠的空间特征,同时保留非重叠区域中的原始特征。融合后的特征图包含两者的关键特征(用红色和绿色框标记)特征图。然后,采用RPN在融合的特征图上提出潜在区域,进行目标检测。
不同的通道共享不同的权重,即特征图中的某些通道对分类/检测的贡献更大,而其他通道则是冗余或不需要的。因此,从所有 128个通道中选择部分通道进行传输,传输部分通道可以进一步减少传输的时间消耗。
3.3 使用融合特征进行目标检测
将融合的特征图输入到区域提议网络 (RPN) 以进行目标提议和检测车辆。接下来,将损失函数应用于网络训练。
3.3.1 区域提案网络(RPN)
一旦得到空间特征图,无论采用体素融合还是空间融合,都会将其发送到RPN。通过 RPN 网络后,将获得损失函数的两个生成输出(第 3.3.2 节):
(1)提议的感兴趣区域的概率分数 p ∈ [0, 1];
(2)位置提议区域的 P = (Px , Pw , Pz , Pl , Pw , Ph, Pθ),其中 (Px , Py, Pz) 表示提议区域的中心,(Pl , Pw , Ph, Pθ) 表示长度、宽度,高度和旋转角度。
3.3.2 损失函数
损失函数由两部分组成:分类损失 Lcls 和回归损失Lreg
假设一个真实 3D 边界框可以表示为 G =(Gx, Gy, Gz, Gl, Gw, Gh, Gθ),其中(Gx, Gy, Gz)表示框的中心点,(Gl, Gw, Gh, Gθ)分别表示长度、宽度、高度和偏航旋转角。
在F-Cooper中,得到空间特征图通过 RPN 网络后,将生成一个向量 P 来表示预测的 3D 边界框。通过最小化预测和ground truth之间的差值(Δx,Δy,Δz,Δl,Δw,Δθ)来得到最优的预测框:
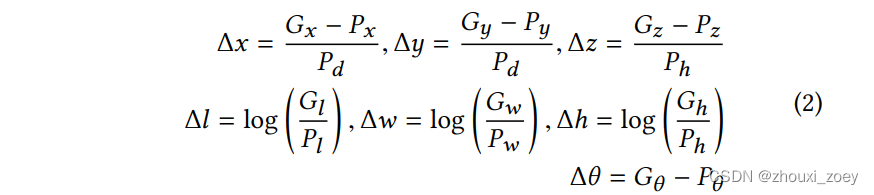
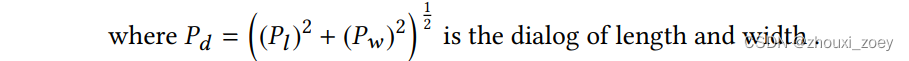
假设提出了 Npos 个正anchors 和 Nneg 个负anchors,损失函数定义为:
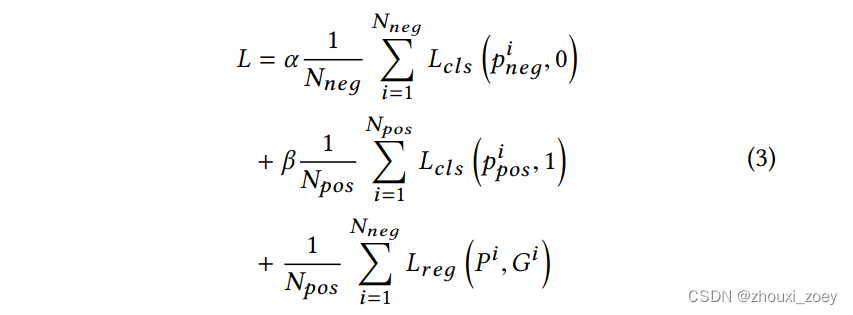
其中 pineg 和 pipos 分别是正anchors和负anchors的概率,Gi 表示第 i 个 ground truth,Pi 表示相应的预测边界框。使用 α 和 β 来平衡这三个损失,对于分类损失和 Smooth-L1 损失,采用二元交叉熵损失函数 。
总结
提出了一种基于点云特征的协同感知框架(F-Cooper):
1)利用特征级融合实现端到端的 3D 目标检测,特征级数据传输不会有网络拥塞的风险,可实现实时边缘计算和低通信延迟;
2)除了能够提高检测精度外,特征融合所需的数据量仅为原始数据量的百分之一,在数据量和传输时间上都很好地处于 On-Edge 计算和通信的可接受范围内;
3)两种融合方案:体素特征融合和空间特征融合。体素特征融合可实现与原始数据级融合方案几乎相同的检测精度,空间特征融合可动态调整特征图的大小更适合压缩和数据传输,更适合带宽有限的网络;
4)F-Cooper 可以在车载和路边系统上部署和执行。

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐
 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)