

如何使用Label Studio实现多用户协作打标,对标记好的数据如何进行实体去重
Label Studio打标工具使用方法简介及知识图谱创建
首先进入Label Studio完成注册登录,Label Studio支持多用户协同标注,用户可通过专有链接进入Label Studio,同一链接下的所有用户均可同时对数据进行标注,标注结果全员共享。

点击右上角create按钮创建一个新的项目

进入项目后,我们可以就可以导入数据了,Label Studio支持两种导入方式,分别是本地上传和网络URL,并且支持文本、语音、图片等多种数据格式,本文采用文本格式进行打标演示。

在上传文本数据之后,软件会自动为我们分好段落,如下图所示:

在进行文本数据标注之前,我们需先定义“实体标签”与“关系标签”,点击右上角“setting”按钮,在左侧的菜单栏选择Labeling Interface进入实体标签、关系标签编辑界面,在标签编辑框里输入自定义标签内容,点击“Add”添加至标签库,目前笔者尚未发现关系标签编辑窗口,大家可在界面中上方找到“Code”按钮,点击此按钮可在源代码层面对关系标签进行编辑。

有了实体标签和关系标签之后,我们便可开始打标工作,具体地,点击需要进行标注的文本,进入标注页面,如下图所示,首先点击我们预定义好的“概念”、“知识点”等标签,用鼠标划选文本中要标注的实体,释放鼠标即标注成功。
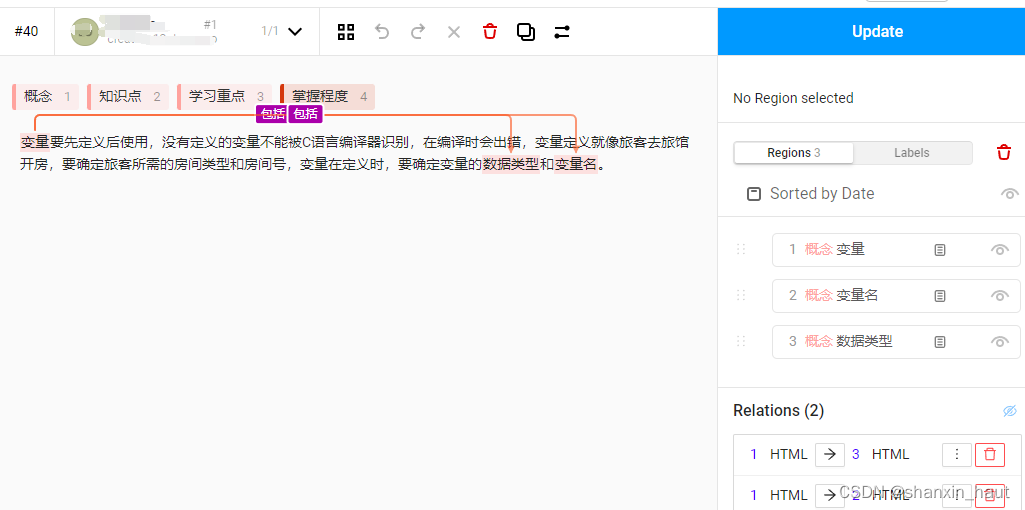
在标注完实体之后,在文本中点击实体,以下图为例,我们点击“变量”之后,点击界面右侧“锁链”形状按钮,接着点击“变量名”,即可创建一个从“变量”指向“变量名”的关系。

在右下角的Relation栏可以对我们创建的关系选择关系标签,此时我们就得到了一个完整的三元组。

接下来就是笔者认为label studio最具亮点的一个功能——“支持多人协同标注,标注结果全员共享”,以下图为例,我们可以清楚看到,有多个用户对我们已分好段的文本进行了标注,并且对于某一段文本,也支持多个用户进行标注,有了这个强大功能的加持,我们就可以做到在一个项目下并行协作进行人工标注,统一完成实体标注。

在完成此文本所有的实体、关系标注之后,点击“update”按钮进行保存,返回主界面导出JSON格式的标注数据。
之后的工作就是进行实体去重并录入数据库。
对于生成的标注数据,有一点需要格外注意,相同的实体会具有不同的id值,如果我们不对这些“同名”实体进行处理,那么在创建知识图谱时就会出现重复节点,在这里笔者分享一种去重思路。
首先从标注数据中将所有实体的名称(text),编号(no,由于在Neo4j数据库中,创建节点后也会自动生成一个id值,为了避免发生混淆,我们采用“no”来表示原来的“id”),标签(label)存入node.csv文件中,我们可以看到,的确存在部分名称相同、no不同的实体。

去重的总体思路是,维护一个存有实体信息的文件,当读取到标记数据中的实体时,首先检查此实体是否在name_lst中,如果不存在,则将其标记flag设置为True,创建节点;需要说明的是,不管此实体是否已经在name_lst中,我们都需要将其信息写入文件,因为我们在之后的关系创建时,需要利用id值来查找实体名称,一个实体可能会有多个id。
for row in csv.reader(fr):
name_lst.append(row[0]) #将实体名称存入name_lst
csv.writer(fr).writerow([text,labels,no]) #将实体信息写入文件
flag = False #设置一个标记,F代表实体已经在name_lst中
if text not in name_lst: #如果实体的名称不在name_lst中
name_lst.append(text) #添加此实体
flag = True
if flag: #创建节点
cypher_ = "CREATE (:" + labels + " {name:'" + text + "', no:'" + no + "'})"
graph.run(cypher_)通过以上操作,我们可以确保创建唯一的节点,接下来即可根据id值来找到头尾节点,创建关系。
附上完整代码:
from py2neo import Graph, Node, Relationship
import csv
import read_data
import pandas as pd
import json
path='1.json'
f = open(path,'r',encoding='utf-8')
# f1 = open("node.txt",'a')
f1= open("node.csv", mode="a", encoding="utf-8", newline="")
fr= open("node.csv", mode="r", encoding="utf-8")
m = json.load(f)
graph = Graph('http://localhost:7474',name="neo4j",password="123456")
name_lst = []
for row in csv.reader(fr):
name_lst.append(row[0])
fr.seek(0)
for result in m:
result = result['annotations'][0]['result']
for item in result:
flag = False
if "type': 'relation'" not in str(item):
text = item['value']['text']
labels = item['value']['labels'][0]
no = item['id']
csv.writer(f1).writerow([text,labels,no])
if text not in name_lst:
name_lst.append(text)
flag = True
print(name_lst)
if flag:
cypher_ = "CREATE (:" + labels + " {name:'" + text + "', no:'" + no + "'})"
graph.run(cypher_)
for result in m:
result = result['annotations'][0]['result']
for item in result:
flag = False
if "type': 'relation'" in str(item):
print("进入关系")
from_id = item['from_id']
to_id = item['to_id']
labels = item['labels'][0].replace(':','')
from_name,to_name ,from_label, to_label='','','',''
f_csv = csv.reader(fr)
for row in f_csv:
if from_id == row[2]:
print("进入")
from_name = row[0]
from_label = row[1]
print(from_name,from_id)
if to_id == row[2]:
to_name = row[0]
to_label = row[1]
print(to_name,to_id)
cypher_ = "MATCH (a:"+from_label +"),(b:"+to_label+") WHERE a.name = '"+from_name+"' AND b.name = '"+to_name+"' CREATE (a)-[r:"+labels+"]->(b)"
graph.run(cypher_)
总结:
1.Label Studio容易上手,并且还支持多人协作标注,这是一大亮点。
2.在使用生成的数据时,需要对数据进行实体去重处理,本文采用的处理方法是比较容易想到的一种,但谈不上高效,欢迎大家在评论区留下更多的去重方法。

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)