
MapReduce编程实践(基于deepin 20.2社区版&Hadoop 3.1.3)
参考资料:MapReduce编程实践(Hadoop3.1.3) 厦大数据库实验室博客目录词频统计任务要求在Eclipse中创建项目编写Java应用程序编译打包程序运行程序词频统计任务要求首先,在Linux系统本地创建两个文件wordfile1.txt和wordfile2.txt。在实际应用中,这两个文件可能会非常大,会被分布存储到多个节点上。但是,为了简化任务,这里的两个文件只包含几行简单的内容。
词频统计任务要求
首先,在Linux系统本地创建两个文件wordfile1.txt和wordfile2.txt。在实际应用中,这两个文件可能会非常大,会被分布存储到多个节点上。但是,为了简化任务,这里的两个文件只包含几行简单的内容。
文件wordfile1.txt和wordfile2.txt的内容如下:
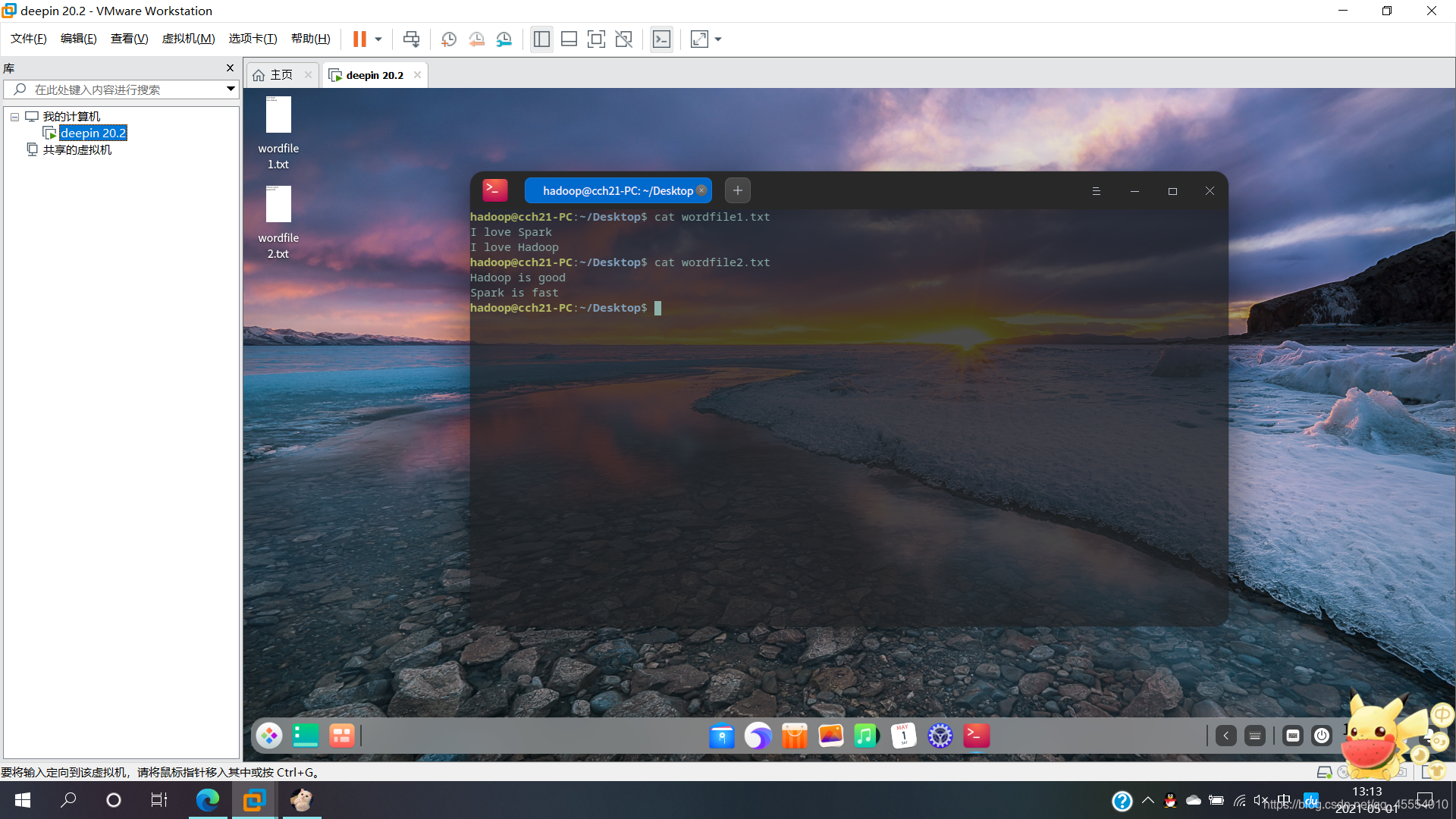
假设HDFS中有一个/user/hadoop/input/目录并且为空,请把文件wordfile1.txt和wordfile2.txt上传到HDFS中的/user/hadoop/input/目录下。现在需要设计一个词频统计程序,统计input文件夹下所有文件中每个单词的出现次数,也就是说,程序应该输出如下形式的结果:
fast 1
good 1
Hadoop 2
I 2
is 2
love 2
Spark 2
在Eclipse中创建项目
打开Eclipse,在/home/hadoop/workspace/中创建项目WordCount。
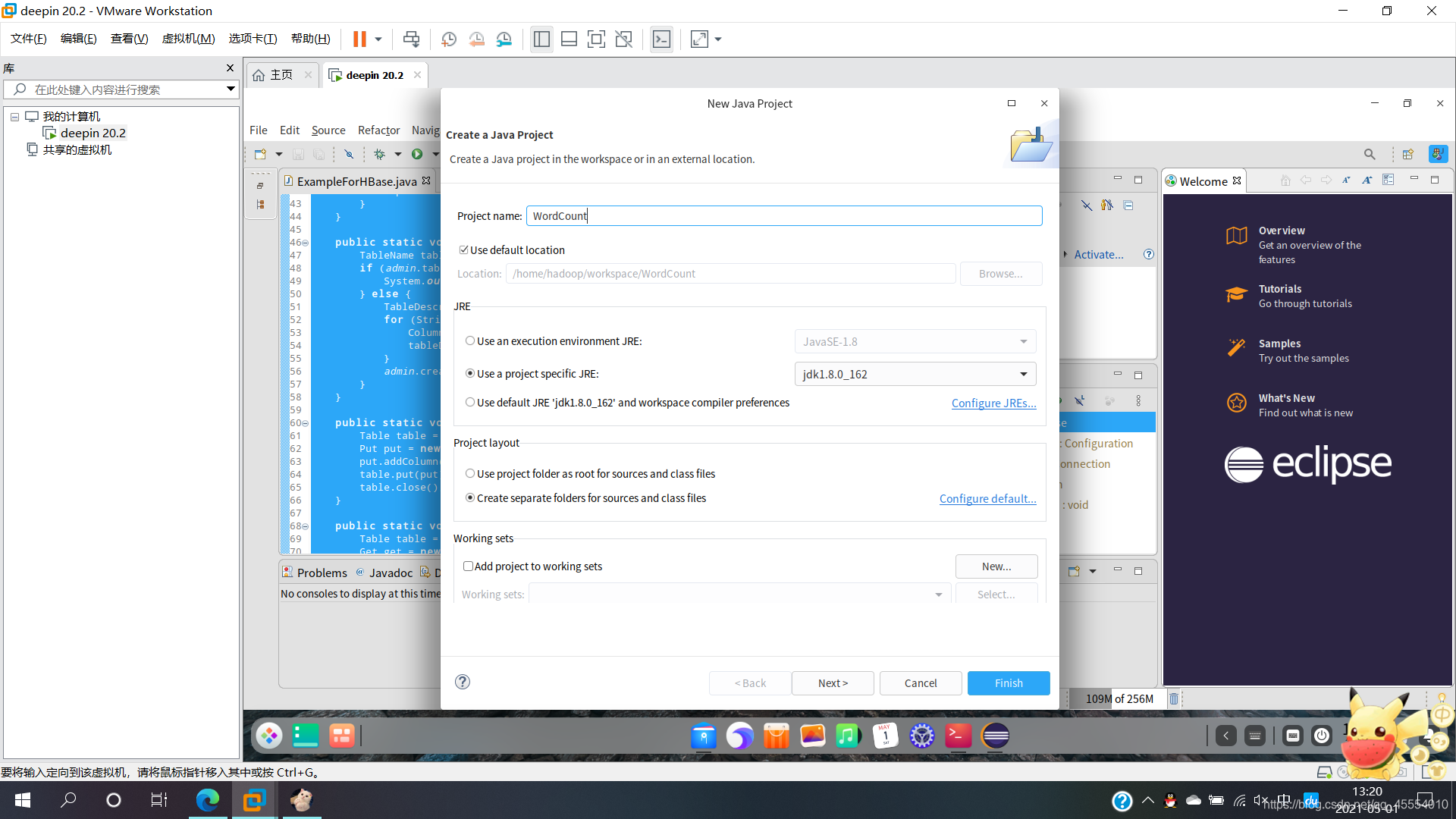
点击“Next”,进入下一步设置之后,点击“Libraries”选项卡,然后点击右侧的“Add External JARs…”向Java工程中加入以下JAR包:
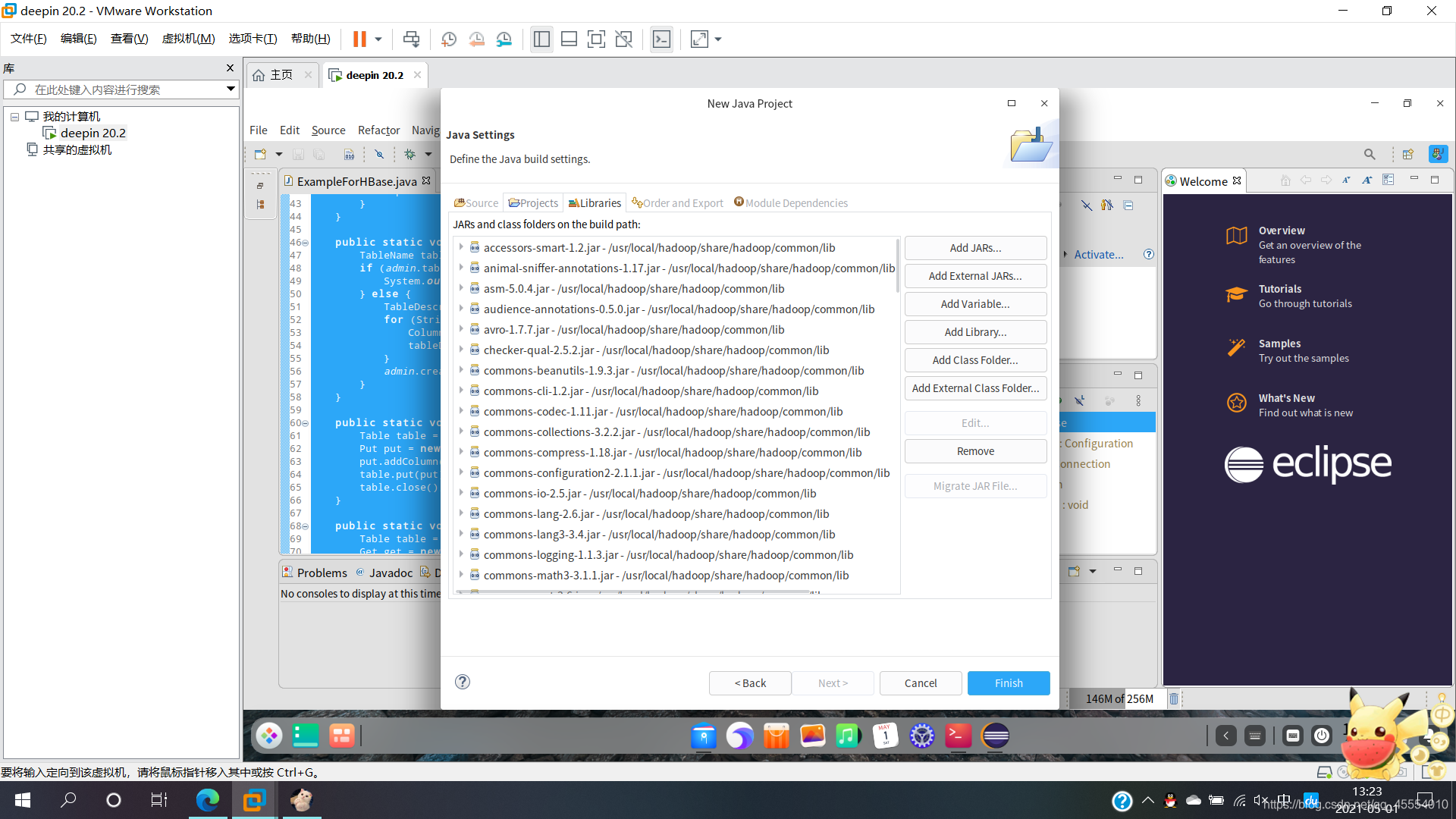
/usr/local/hadoop/share/hadoop/common/目录下的hadoop-common-3.1.3.jar和hadoop-nfs-3.1.3.jar。/usr/local/hadoop/share/hadoop/common/lib/目录下的所有JAR包。/usr/local/hadoop/share/hadoop/mapreduce/目录下的所有JAR包(注意:不包括jdiff、lib、lib-examples和sources目录)。/usr/local/hadoop/share/hadoop/mapreduce/lib/目录下的所有JAR包。
点击“Finish”完成项目的创建。
编写Java应用程序
在左侧的“Package Explorer”中找到刚刚创建好的WordCount工程,右键选择“New→Class”新建Java类文件。
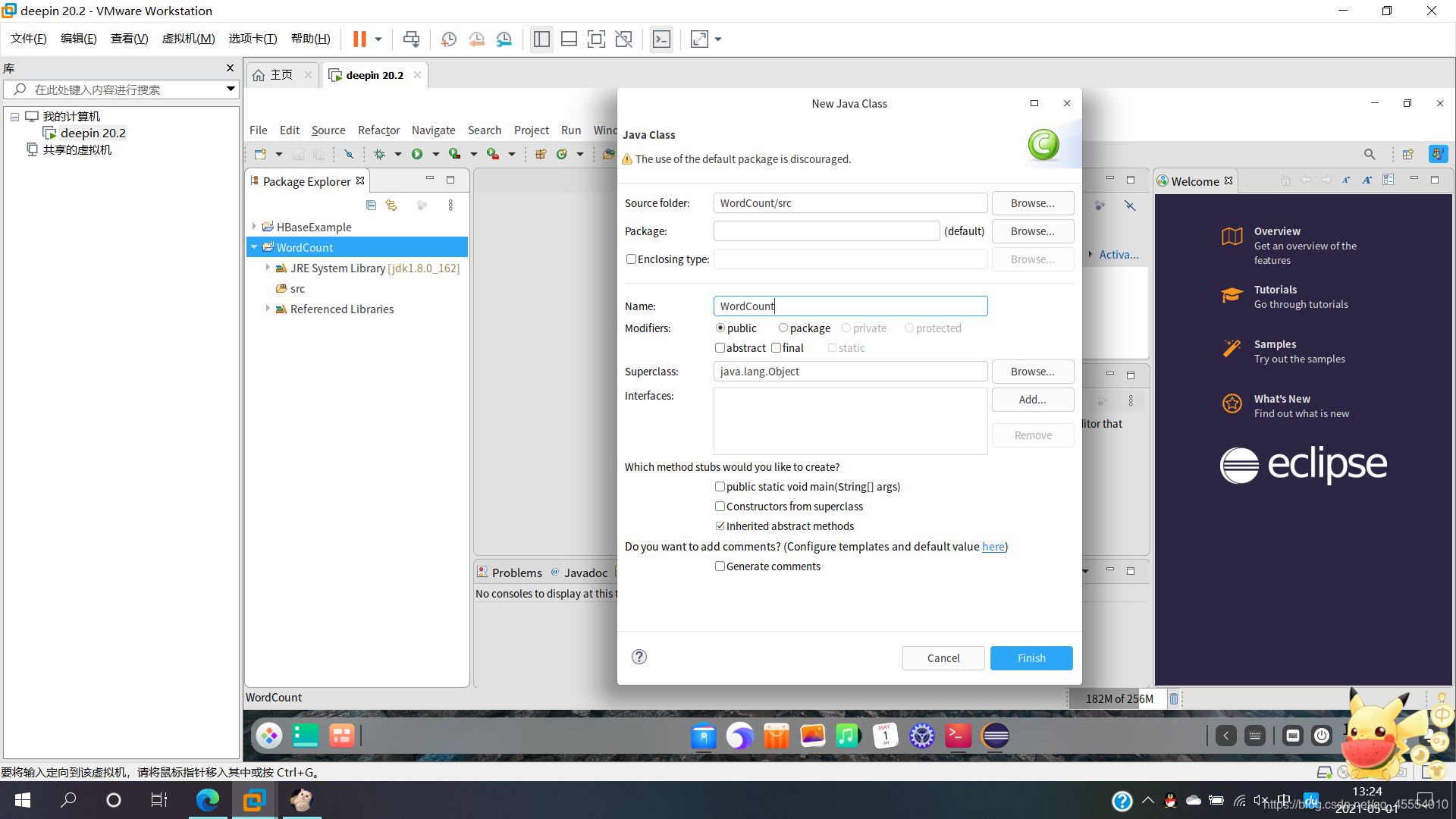
WordCount.java代码如下:
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public WordCount() {
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for (Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable)i$.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
}
编译打包程序
点击上方“Run”选项卡,选择“Run As”,点击“Java Application”,运行程序:

下面可以把Java应用程序打包生成JAR包,部署到Hadoop平台上运行。JAR包放在/usr/local/hadoop/myapp/目录下,在此前的实验中已经创建过该目录,如果该目录不存在,可以使用如下命令创建:
$ mkdir /usr/local/hadoop/myapp
在Eclipse工作界面左侧的“Package Explorer”中找到工程WordCount,点击鼠标右键,选择“Export…”,在弹出的界面中选择“Runnable JAR file”。
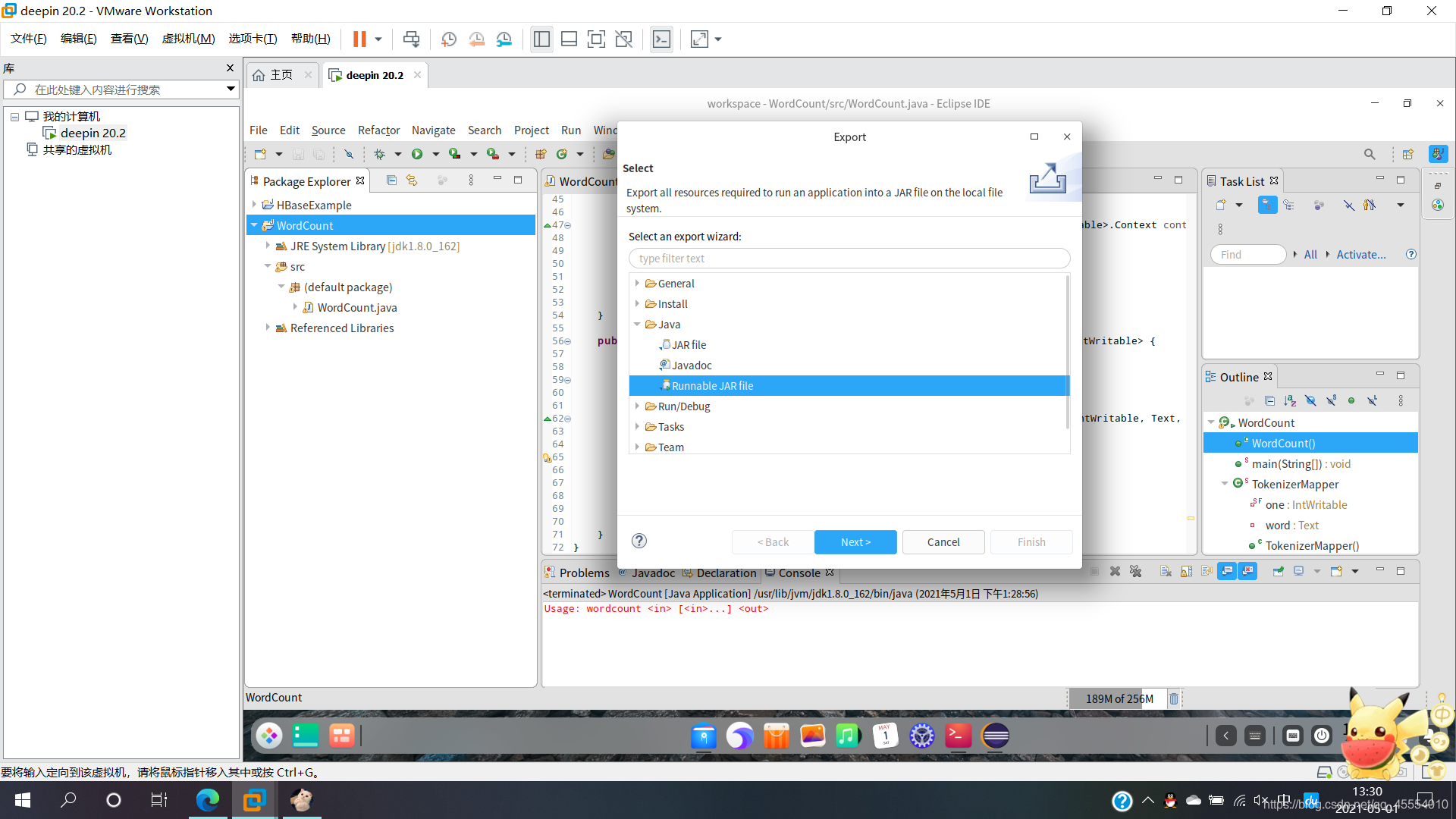
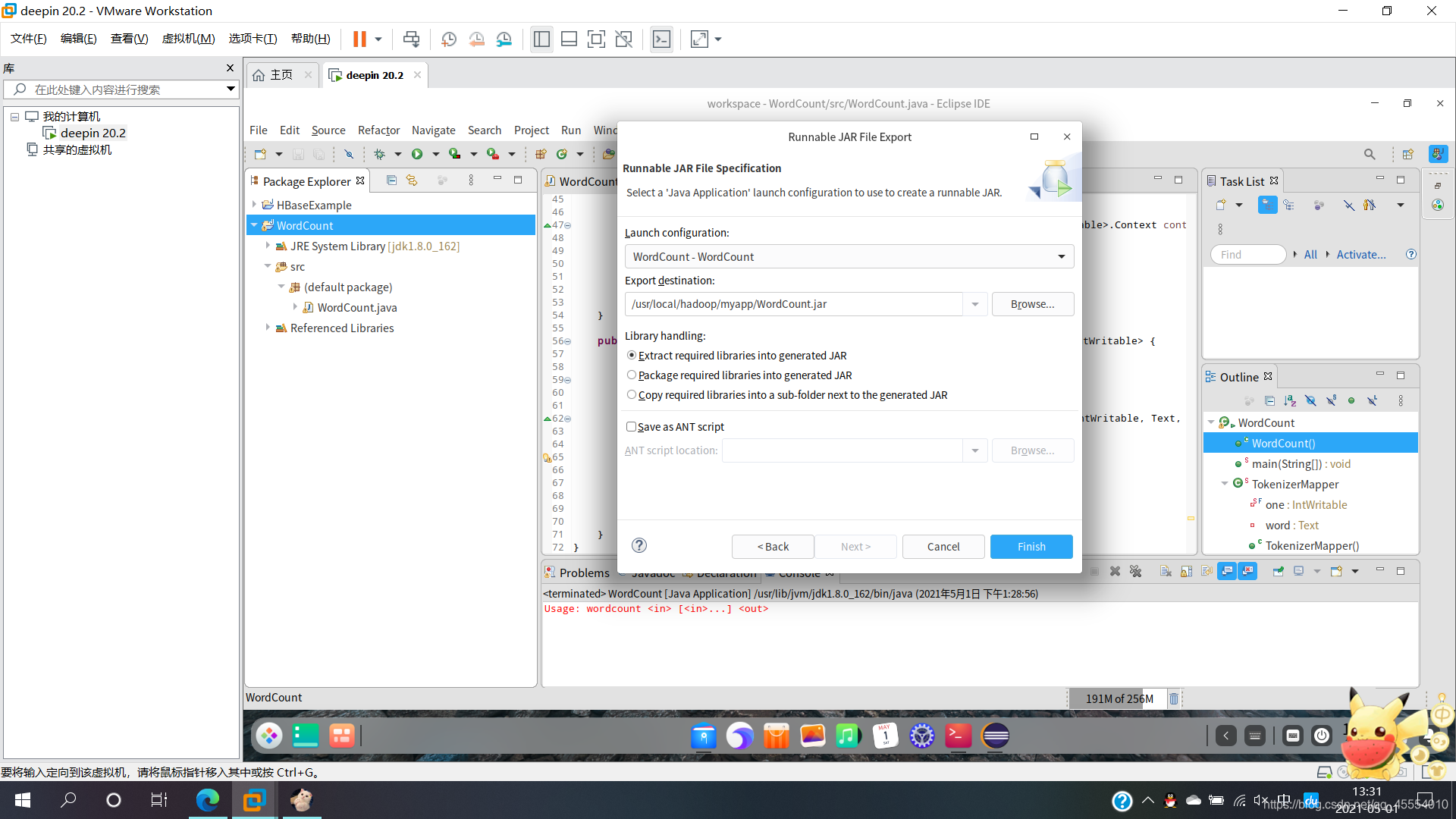
此时,/usr/local/hadoop/myapp/目录下已经打包好了一个名为WordCount.jar的文件。
运行程序
首先启动Hadoop:
$ cd /usr/local/hadoop
$ ./sbin/start-dfs.sh
$ jps
删除HDFS中与当前用户hadoop对应的input和output目录(即HDFS中的/user/hadoop/input/和/user/hadoop/output/目录),这样确保后面程序运行不会出现问题:
$ ./bin/hdfs dfs -rm -r input
$ ./bin/hdfs dfs -rm -r output
在HDFS中新建与当前用户hadoop对应的input目录,即/user/hadoop/input/目录:
$ ./bin/hdfs dfs -mkdir input
把之前在Linux本地文件系统中新建的两个文件wordfile1.txt和wordfile2.txt上传到HDFS中的/user/hadoop/input目录下:
$ ./bin/hdfs dfs -put ~/Desktop/wordfile1.txt input
$ ./bin/hdfs dfs -put ~/Desktop/wordfile2.txt input
查看HDFS中的/user/hadoop/input目录:
$ ./bin/hdfs dfs -ls input
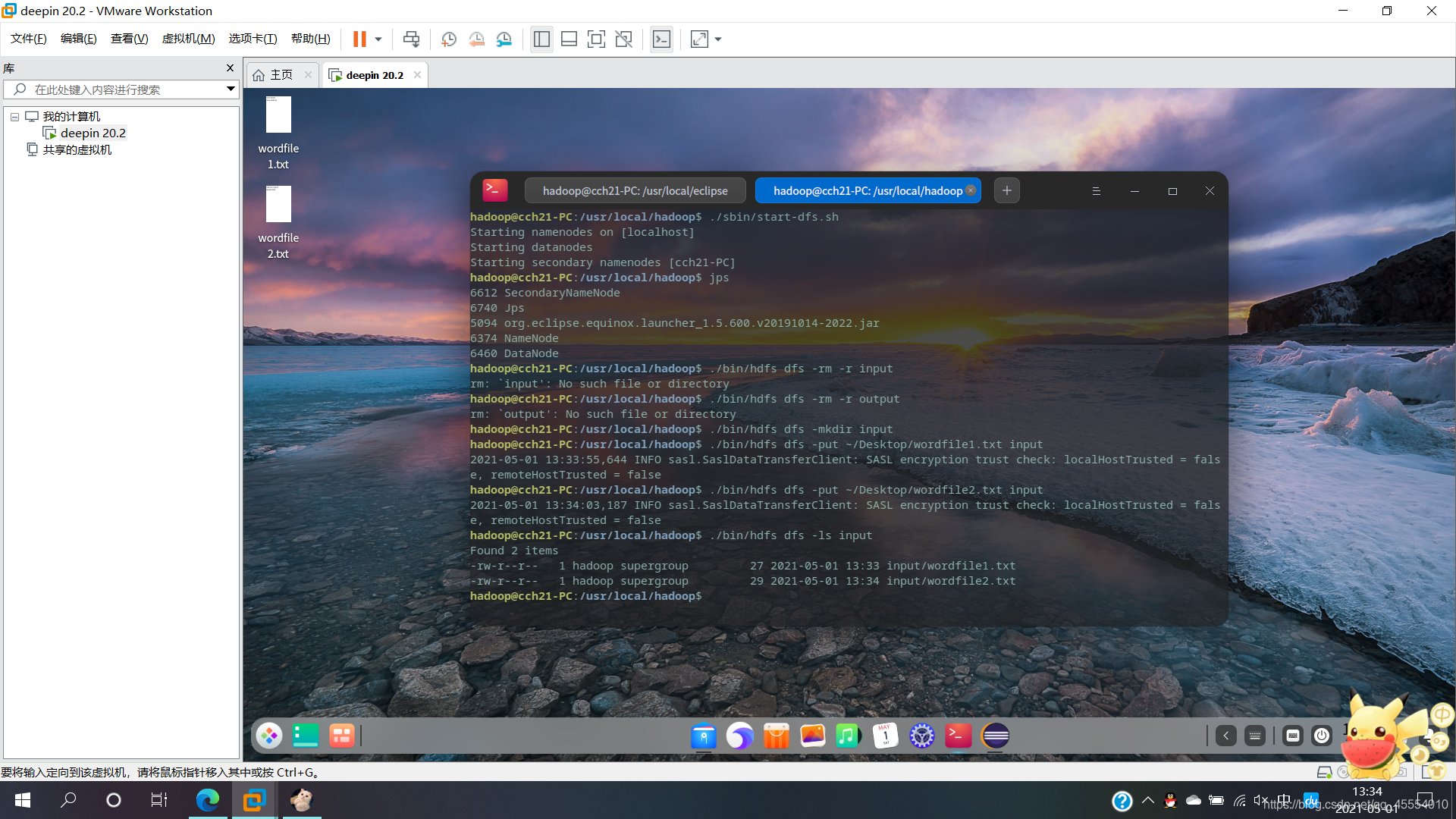
运行程序,词频统计结果被写入到HDFS的/user/hadoop/output/目录中,运行结束后查看词频统计结果:
$ ./bin/hadoop jar ./myapp/WordCount.jar input output
$ ./bin/hdfs dfs -cat output/*
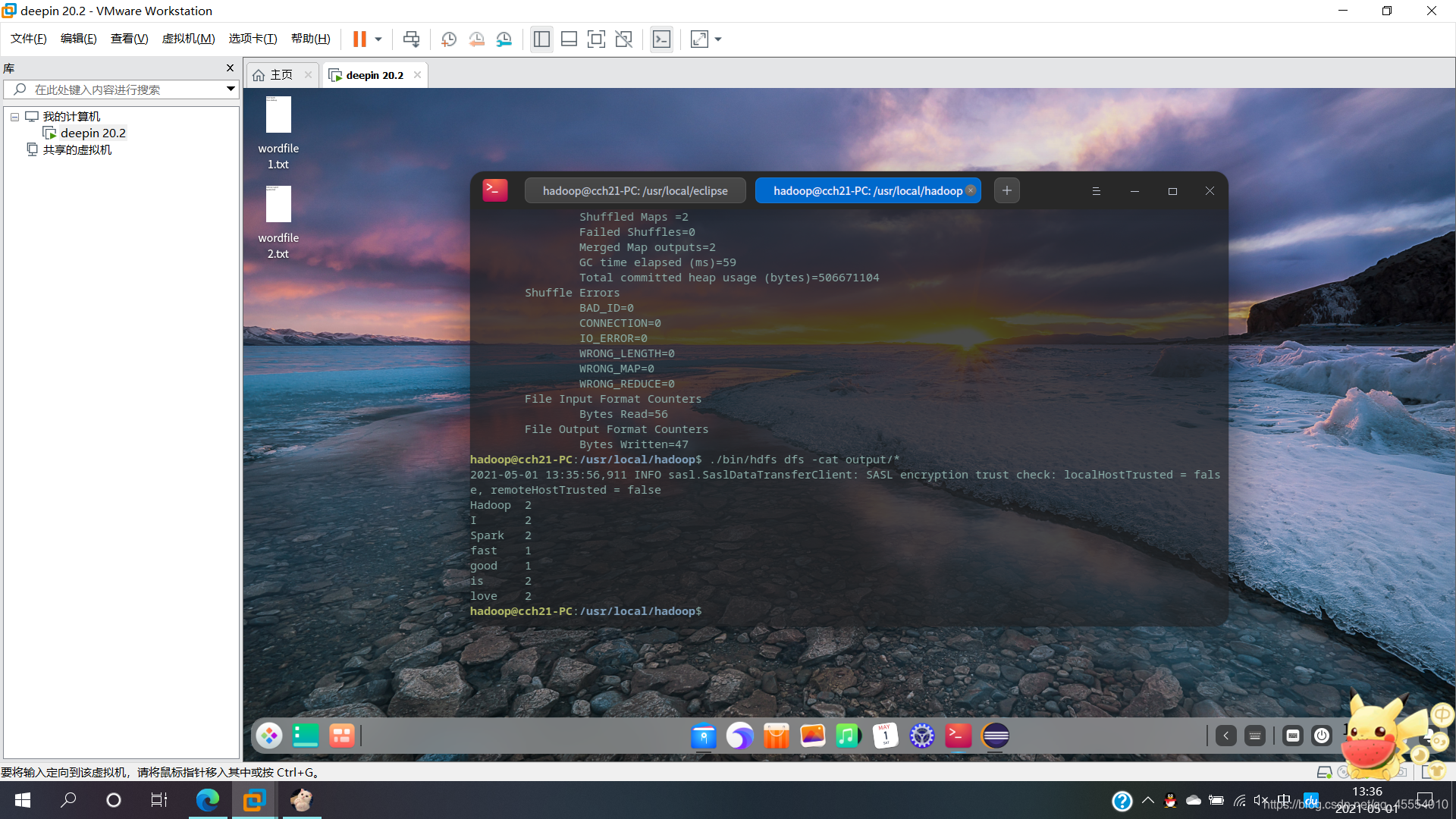
关闭Hadoop:
$ ./sbin/stop-dfs.sh

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)