
和鲸社区的滴滴出行数据分析项目
【R】【数据分析】这是我做的第一个数据分析项目(课外),浅浅记录一下。
·
这是我做的第一个数据分析项目,浅浅记录一下。
和鲸上的做法是用Python以及pandas库,我用的是r语言(rstudio)。
先预览一下数据(前五行):
第一个表:test表,展示了AB测试的结果。
| date | group | requests | gmv | coupon per trip | trips | canceled requests |
| 1/1/2019 | control | 30 | 7486.62 | 1.07 | 24 | 1 |
| 1/2/2019 | control | 152 | 38301.58 | 1.04 | 121 | 8 |
| 1/3/2019 | control | 267 | 67768.43 | 1.03 | 215 | 14 |
| 1/4/2019 | control | 369 | 94992.9 | 1.03 | 298 | 19 |
| 1/5/2019 | control | 478 | 123236.88 | 1.01 | 390 | 24 |
第二个表:city表,展示了一个月内出租车运营情况。
| date | hour | requests | trips | supply hours | average minutes of trips | pETA | aETA | utiliz |
| 9/1/2013 | 11 | 79 | 55 | 42.63 | 20.43 | 5.51 | 7.19 | 48% |
| 9/1/2013 | 12 | 73 | 41 | 36.43 | 15.53 | 5.48 | 8.48 | 43% |
| 9/1/2013 | 13 | 54 | 50 | 23.02 | 17.76 | 5.07 | 8.94 | 77% |
| 9/2/2013 | 11 | 193 | 170 | 64.2 | 31.47 | 5.31 | 6.55 | 49% |
| 9/2/2013 | 12 | 258 | 210 | 80.28 | 38.68 | 4.94 | 6.08 | 48% |
下为代码,分析也写在注释部分了。
一、导入数据
#数据导入
test=read.csv("C:/Users/iamlgj/Desktop/test.csv",header=TRUE)
test
city=read.csv("C:/Users/iamlgj/Desktop/city.csv",header=TRUE)
city
test$group=factor(test$group)下面是数据分析的第一个部分:AB测试效果检验
二、AB测试效果检验(利用test表)
#1.AB测试效果分析
#1.1.检验订单请求数之间有无差异
group_a_requests=test$requests[test$group=='control']
group_a_requests
group_b_requests=test$requests[test$group=='experiment']
group_b_requests
shapiro.test(group_a_requests)#说明样本服从正态分布
shapiro.test(group_b_requests)#说明样本服从正态分布
bartlett.test(test$requests~test$group,data=test)#两总体方差相同,方差齐性检验通过
aov_requests=aov(test$requests~test$group,data=test)
summary(aov_requests)#方差分析结果显示,AB组两个总体均值无显著差异,说明改变的节点对请求订单数没有显著影响
#1.2.检验成交总额之间有无差异
group_a_gmv=test$gmv[test$group=='control']
group_a_gmv
group_b_gmv=test$gmv[test$group=='experiment']
group_b_gmv
shapiro.test(group_a_gmv)#说明样本服从正态分布
shapiro.test(group_b_gmv)#说明样本服从正态分布
bartlett.test(test$gmv~test$group,data=test)#两总体方差相同,方差齐性检验通过
aov_gmv=aov(test$gmv~test$group,data=test)
summary(aov_gmv)#方差分析结果显示,AB组两个总体均值无显著差异,说明改变的节点对成交总额没有显著影响
#1.3.检验ROI之间有无差异
roi=test$gmv/(test$coupon.per.trip*test$trips)
roi
test1=data.frame(test$date,test$group,test$requests,test$gmv,test$coupon.per.trip,test$trips,test$canceled.requests,roi)
test1
group_a_roi=test1$roi[test1$test.group=='control']
group_a_roi
group_b_roi=test1$roi[test1$test.group=='experiment']
group_b_roi
shapiro.test(group_a_roi)
shapiro.test(group_b_roi)#没有通过正态性检验,因此下面用Fligner-Killeen检验方差齐性
fligner.test(test1$roi,test1$test.group)#通过方差齐性检验
#由于正态性检验没有通过,但方差齐性检验通过,因此下面不能再使用方差分析,因此改用独立样本的t检验
t.test(test1$roi~test1$test.group,data=test1,var.equal=T)#独立样本t检验结果显示,改变的节点对ROI也没有影响
#综合以上来看,这个节点的改变对ROI/GMV/REQUESTS的水平均没有影响,并不是一个比较理想的改进这里有一点问题,该项目原作者检验两个均值有无差异时用的是配对样本t检验,但是根据个人理解+查阅资料+该项目评论区的意见,我认为应该用独立样本t检验。我这里用的是单因素方差分析,水平数为2时应该是等价独立样本t检验的。之前做过方差分析用起来比较顺手,所以就用了这个方法。当然,方法这个部分也只是我个人理解,非常欢迎有不同意见的大佬交流(毕竟我只浅学了一点)。
三、城市运营数据探索
#2.数据探索
#2.1.什么时段的请求订单量最大
x=city[order(city$hour),]
x
hour_11=sum(x$requests[1:30])
hour_11
hour_12=sum(x$requests[31:60])
hour_12
hour_13=sum(x$requests[61:90])
hour_13
#可见,在中午十二点时是订单量最多的
#2.2.什么日期的请求订单量最多
requests_date=c()
for(i in 1:90){
if(i%%3==0){
requests_date=c(requests_date,city$requests[i-2]+city$requests[i-1]+city$requests[i])
}
}
requests_date
library(ggplot2)
unique_date=unique(city$date)
requests_date_ts=ts(requests_date,start = 1,end = 30)
plot(requests_date_ts)
#由图中发现,在单月内,订单数量呈现周期性变化,经调查,几个波峰基本均出现在周末,因此可以建议公司在周末加大派车数量。
#2.3.各时段订单完成率
x=city[order(city$hour),]
x
trips_11=sum(x$trips[1:30])
trips_11
trips_12=sum(x$trips[31:60])
trips_12
trips_13=sum(x$trips[61:90])
trips_13
rate=c(c(trips_11,trips_12,trips_13)/c(hour_11,hour_12,hour_13))
rate
#可见,13时的订单完成率最低,11时的订单完成率最高,公司应多关注13时的订单完成情况。
#2.4.单月每日订单完成率
trips_date=c()
for(i in 1:90){
if(i%%3==0){
trips_date=c(trips_date,city$trips[i-2]+city$trips[i-1]+city$trips[i])
}
}
trips_date
rate1=trips_date/requests_date
rate1
rate1_ts=ts(rate1,start=1,end=30)
plot(rate1_ts)
#虽然订单完成率的规律不够明显,但从图上可以看出,几个谷值几乎都出现在周末附近,结合前面的分析结果,周末订单请求数多,但订单完成率比较低,公司应该在周末时段加大出车力度以满足出行需求。
#2.5.顾客等待时间
x=city[order(city$hour),]
x
peta_11=mean(x$pETA[1:30])
peta_11
peta_12=mean(x$pETA[31:60])
peta_12
peta_13=mean(x$pETA[61:90])
peta_13
aeta_11=mean(x$aETA[1:30])
aeta_11
aeta_12=mean(x$aETA[31:60])
aeta_12
aeta_13=mean(x$aETA[61:90])
aeta_13
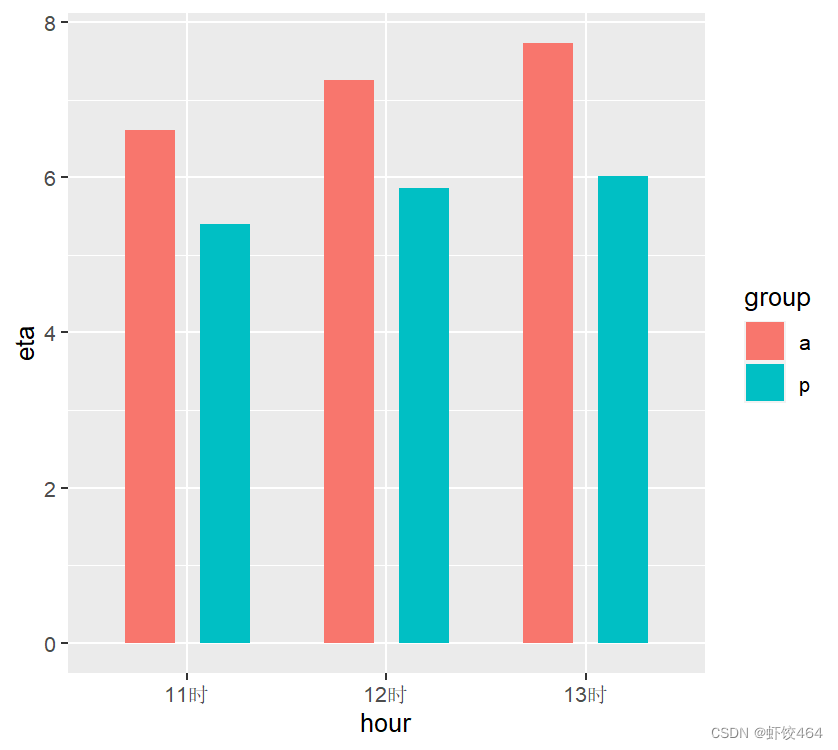
dataframe=data.frame(eta=c(peta_11,peta_12,peta_13,aeta_11,aeta_12,aeta_13),hour=rep(c('11时','12时','13时'),2),group=c('p','p','p','a','a','a'))
#绘制复合条形图
ggplot(dataframe,aes(x=hour,y=eta,fill=group))+
geom_bar(stat='identity',position=position_dodge(0.75),width=0.5)
#从图上可以看出,顾客预计等待时间都比实际等待时间要长,这提示我们平台需要增加预计等待时间计算的准确率,否则有可能引起乘客的不满,并且也需要优化配车方案,减少顾客等待时间。
#2.6.司机在忙率
x=city[order(city$hour),]
x
utiliz_num=as.numeric(sub("%","",x$utiliz))/100 #由于原utiliz列是字符串格式,因此需要先将它转换为数值类型
utiliz_11=mean(utiliz_num[1:30])
utiliz_11
utiliz_12=mean(utiliz_num[31:60])
utiliz_12
utiliz_13=mean(utiliz_num[61:90])
utiliz_13
#从结果1可以看出,12时的司机在忙率最高。这也与前面的结果相吻合。因此中午12时是一个很重要的时间点,需要平台多加关注。
#2.7.订单时长
x=city[order(city$hour),]
x
avgtime_11=mean(x$average.minutes.of.trips[1:30])
avgtime_11
avgtime_12=mean(x$average.minutes.of.trips[31:60])
avgtime_12
avgtime_13=mean(x$average.minutes.of.trips[61:90])
avgtime_13
#从结果来看,仍是中午十二点的订单平均时长最长,因此12点的用车需求大,需要的数量也多。
##综合以上分析结果,建议平台加强周末以及中午12点时段的出车量,提高订单响应率,优化预计等待时间算法以提高其准确度,同时优化派车方式减少乘客等待时间下面放两个做出来的图。

结束了!就酱。

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)