
neo4j 4.4.20 社区版 windows 单机部署 测试
neo4j windows 安装及测试
一,安装Neo4j4.4.20
在安装neo4j之前,需要安装Java JRE,并配置Java开发环境,然后安装neo4j服务。
1,安装Java JRE
Neo4j是基于Java运行环境的图形数据库,因此,必须向系统中安装JAVA SE(Standard Editon)的JRE。从Oracle官方网站下载 Java SE JRE,版本是JRE 11。

配置Java的环境变量,Windows系统有系统环境变量和用户环境变量,都配置,配置环境变量分两步进行:
第一步,新建JAVA_HOME变量,变量值填写jdk的安装目录,默认的安装目录是:C:\Program Files\Java\jdk-11
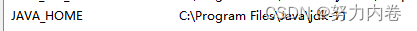
第二步,编辑Path变量,在Path变量输入:%JAVA_HOME%\bin;%JAVA_HOME%\jre\bin;
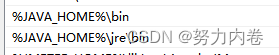
2,下载Neo4j安装文件
从Neo4j官网下载最新版本neo4j-4.4.20社区(Community)版本 “neo4j-community-4.4.20-windows.zip”,解压到主目录,“C:\Program Files\neo4j-community-4.4.20”。
Neo4j应用程序有如下主要的目录结构:
- bin目录:用于存储Neo4j的可执行程序;
- conf目录:用于控制Neo4j启动的配置文件;
- data目录:用于存储核心数据库文件;
- plugins目录:用于存储Neo4j的插件;
3,创建ne04j的环境变量
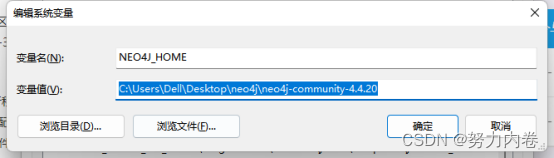
创建主目录环境变量NEO4J_HOME,并把主目录设置为变量值。
二,Neo4j的配置
配置文档存储在conf目录下,Neo4j通过配置文件neo4j.conf控制服务器的工作。默认情况下,不需要进行任何配置,就可以启动和运行服务器。
1,核心数据文件的位置
例如,核心数据文件存储的位置,默认是在data/graph.db目录中,要改变默认的存储目录,可以更新配置选项: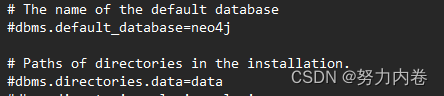
2,安全验证,默认是启用的

3,配置JAVA 堆内存的大小,默认是动态计算

三,网络连接配置
neo4j支持三种网络协议,默认情况下,不需要配置就可以在本地直接运行。
1,Neo4j支持三种网络协议(Protocol)
Neo4j支持三种网络协议(Protocol),分别是Bolt,HTTP和HTTPS,默认的连接器配置有三种,为了使用这三个端口,需要在Windows防火墙中创建Inbound Rules,允许通过端口7687,7474和7473访问本机。
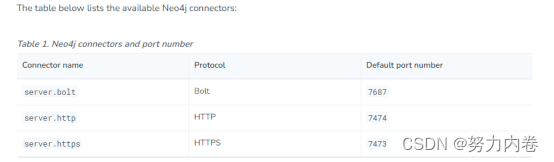
2,连接协议的可选属性
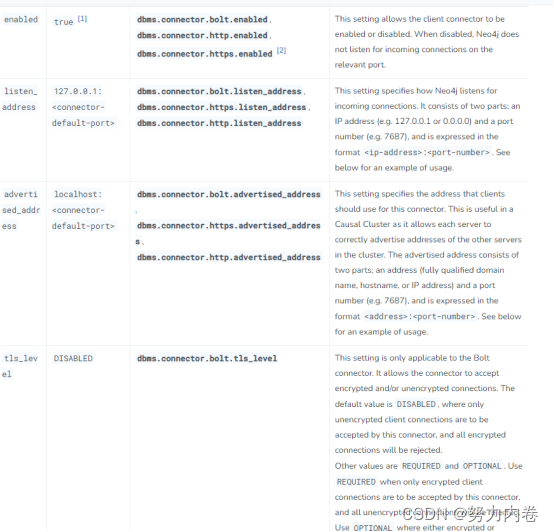
listen_address:设置Neo4j监听的链接,由两部分组成:IP地址和端口号(Port)组成,格式是:ip-address:port-number
3,设置默认的监听地址
设置默认的网络监听的IP地址,该默认地址用于设置三个网络协议(Bolt,HTTP和HTTPs)的监听地址,即设置网络协议的属性:listen_address地址。在默认情况下,Neo4j只允许本地主机(localhost)访问,要想通过网络远程访问Neo4j数据库,需要修改监听地址为 0.0.0.0,这样设置之后,就能允许远程主机的访问。

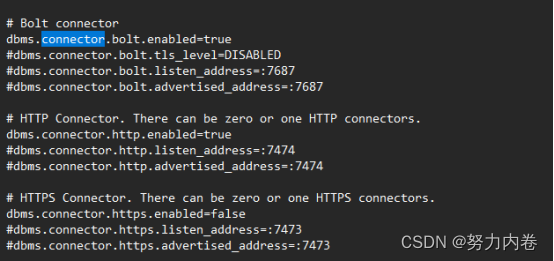
4,分别设置各个网络协议的监听地址和端口
HTTP链接器默认的端口号是7474,Bolt链接器默认的端口号是7687,必须在Windows 防火墙中允许远程主机访问这些端口号。
四,启动Neo4j程序
点击组合键:Windows+R,输入cmd,启动DOS命令行窗口,切换到主目录,以管理员身份运行命令
1,通过控制台启动Neo4j程序
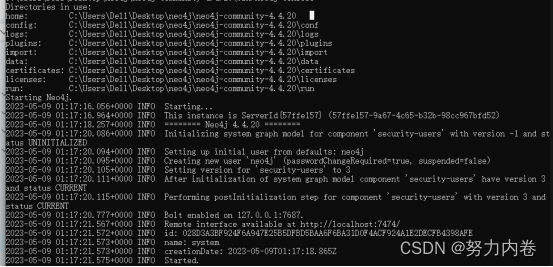
以管理员权限启用DOS命令行窗口,输入以下命令,通过控制台启用neo4j程序

如果看到以下消息,说明neo4j已经开始运行:
2,把Neo4j安装为服务(Windows Services)
安装和卸载服务

启动服务,停止服务,重启服务和查询服务的状态:

五,Neo4j集成的浏览器客户端
Neo4j服务器具有一个集成的浏览器,在启动neo4j服务之后,可以使用neo4j集成的浏览器管理图数据库。
在一个运行neo4j服务器主机上访问 “http://localhost:7474/”,显示以下的界面:
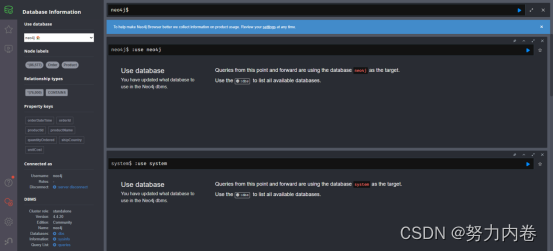
默认的host是bolt://localhost:7687,默认的用户是neo4j,默认的密码是:neo4j,第一次成功connect到Neo4j服务器之后,需要重置密码。

访问Graph Database需要输入身份验证,Host是Bolt协议标识的主机。
六,在Neo4j浏览器中导入数据创建节点和关系
导入csv数据的方法主要分三种:
LOAD CSV Cypher命令:该命令是一个很好的处理中小型数据集(最多1000万条记录)。适用于任何方式,包括AuraDB。结论:导入大量数据时,如(600万数据)效率十分慢,并且会导致导入失败。
Neo4j-admin批量导入工具:用于直接加载大型数据集的命令行工具。适用于Neo4j桌面,Neo4j Docker镜像和本地安装。结论:导入大量数据十分快,600万点边数据不到10秒。
Kettle导入工具:对于非常大的数据集支持,适用于任何方式,包括AuraDB。(暂无测试,开源软件,有兴趣可以自己去测试,目前neo4j-admin满足作者需求)
1,生成neo4j要导入的csv数据
在此次生成数据中抽象了两种节点和一种关系分别是商品、订单和商品与订单之间的关系。
商品数据是固定的77种,订单生成一亿条(暂未达到),商品订单关系生成一亿条(暂未达到)。
2,LOAD CSV导入数据
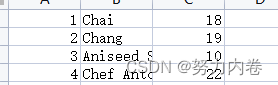
商品数据格式:主要有id、名称、价格
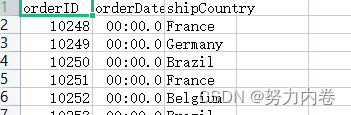
订单数据格式:主要有id、时间、国家
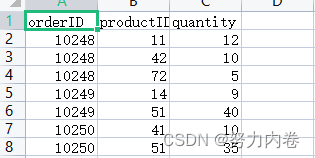
商品订单关系数据格式:主要有商品id、订单id、数量
LOAD CSV可以处理本地和远程文件,两种方式语法不同。
本地文件可以使用文件名前的file:///前缀加载。本地文件方法不适用于AuraDB。Neo4j安全性有一个默认设置,即只能从Neo4j导入目录读取本地文件,所以需要先将要读取的数据放入import文件夹。
web托管的文件可以直接引用它们的URL,如https://host/path/data.csv。
然后执行
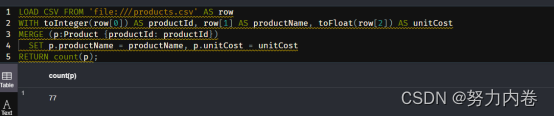


3,neo4j-admin导入数据
商品数据格式:主要有id、名称、价格
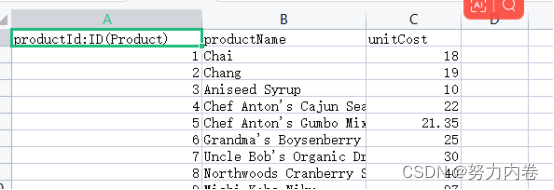
订单数据格式:主要有id、时间、国家
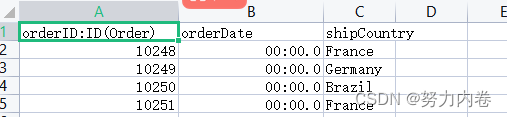
商品订单关系数据格式:主要有商品id、订单id、数量
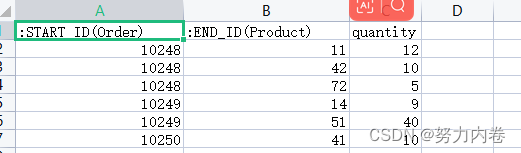
需要保证是向未创建的数据库导入数据,neo4j社区版默认创建neo4j和system 数据库,如果往neo4j数据库中导入数据,会失败需要先停止服务,删除rm -rf databases/neo4j和rm -rf transactions/neo4j然后导入数据到neo4j数据库,再启动服务。
导入数据命令:neo4j-admin import --database=neo4j --nodes=Product=C:\Users\Dell\Desktop\neo4j\neo4j-community-4.4.20\import\products.csv --nodes=Order=C:\Users\Dell\Desktop\neo4j\neo4j-community-4.4.20\import\orders.csv --relationships=CONTAINS=C:\Users\Dell\Desktop\neo4j\neo4j-community-4.4.20\import\order-details.csv --trim-strings=true
注意:不要换行,这里是为了方便理解换行。
七,数据量测试
1,千万数据量
测试语句:
bash match(n:Order) where n.shipCountry="USA" return n limit 10 match l=(n:Order)-[r:CONTAINS]->(p:Product) where n.shipCountry="USA" and r.quantity="10" and p.unitCost="49.3" return l limit 10 match (n:Order),(p:Product) where id(n)=3246236 and id(p)=6031308 return n,p match (n:Order),(p:Product) where id(n)=3246236 and id(p)=6031308 create (n)-[r:TEST]->(p) return r
match (n)-[r:TEST]->(p) delete r match(n:Order) where n.shipCountry="USA" detach delete n match(p:Product) where id(p)=6031308 set p.unitCost = 100 match(n:Order) where n.shipCountry="USA" set n.shipCountry="French"
插入千万数据量后进行增删改查:万级数据以下基本毫秒级响应,操作数据量超过过大会使响应时间变长。
2,过亿数据量
(暂无数据)
八,结论
综上,导入数据neo4j-admin支持大批量数据导入,并且社区版目前来看千万级别的数据量是没有问题的。在实际使用中参考官网linux配置,容器化部署使用社区版唯一不好的地方是容灾不好做。如果考虑集群模式部署的话社区版目前还不支持。

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)