
CUDA编程10 线程束基本函数与协作组
线程束(warp)一个线程块分成两个线程束,每个线程束都是连续的32个线程。从硬件上来看,一个GPU被分为若干个流多处理器(SM)。核函数中定义的线程块在执行时将被分配到还没有完全沾满的SM中。一个线程块不会被分配到不同的SM中,而总是在一个SM中,但一个SM可以有一个或多个线程块。不同的线程块之间可以并发或顺序地执行,一般来说不能同步(即使利用协作组,也只能在一些特殊的情况下进行线程块的同步)。
线程束(warp)一个线程块分成两个线程束,每个线程束都是连续的32个线程。
1.单指令-多线程执行模式(SIME,Single instruction - multi-threaded execution mode)
从硬件上来看,一个GPU被分为若干个流多处理器(SM)。
核函数中定义的线程块在执行时将被分配到还没有完全沾满的SM中。
一个线程块不会被分配到不同的SM中,而总是在一个SM中,但一个SM可以有一个或多个线程块。
不同的线程块之间可以并发或顺序地执行,一般来说不能同步(即使利用协作组,也只能在一些特殊的情况下进行线程块的同步)。
当某些线程块完成计算任务后。对应的SM会部分或完全地空闲,然后会有新的线程块被分配到空闲的SM。
从更细的粒度看,一个SM以32个线程为单位产生、管理、调度、执行线程。这样的32个线程称为一个线程束。一个SM可以处理一个或多个线程块。一个线程块由可分为若干个线程束。
例如,一个128线程的线程块将被分为4个线程束,其中每个线程束包 含32个具有连续线程号的线程。这样的划分对所有的GPU架构都是成立的。
在伏特架构之前,一个线程束中的线程拥有同一个程序计数器(programcounter),但 各自有不同的寄存器状态(registerstate),从而可以根据程序的逻辑判断选择不同的分支。 虽然可以选择分支,但是在执行时,各个分支是依次顺序执行的。在同一时刻,一个线程 束中的线程只能执行一个共同的指令或者闲置,这称为单指令-多线程(single instruction, multiple thread,SIMT)的执行模式。
当一个线程束中的线程顺序地执行判断语句的不同分支时,我们称发生了分支发散(branch divergence),例如,加入核函数中有如下判断语句:
if (condition) {
A;
}
else{
B;
}首先,满足condition的线程会执行语句A,其他的线程将闲置。然后,不满足condition的 线程会执行语句B,其他的线程将闲置。这样,当语句A和语句B的指令数差不多时,整个 线程束的执行效率就比没有分支的情形低一倍。值得强调的是,分支发散是针对同一个线 程束内部的线程的。如果不同的线程束执行条件语句的不同分支,则不属于分支发散。
看看如下代码,假设线程块大小是128;
int warp_id = threadIdx.x / 32;
switch (warp_id)
{
case 0 : S0; break;
case 1 : S1; break;
case 2 : S2; break;
case 3 : S3; break;
}其中,变量warp_id在不同的线程束中取不同的值,但在同一个线程束中取相同的值,所 以这里没有分支发散。
若将上述代码段改写成如下形式:
int lane_id = threadIdx.x % 32;
switch (lane_id)
{
case 0 : S0; break;
case 1 : S1; break;
...
case 31 : S31; break;
}则将导致严重的分支发散,因为变量lane_id在同一个线程束内部可以取32个不同的值。
一般来说,在编写核函数时要尽量避免分支发散。但是在很多情况下,根据算法的需 求,是无法完全避免分支发散的。
例如,在数组相加程序及很多其他的程序中,我们都会 在核函数中使用如下判断语句
if (n < N)
{
//do something
}该判断语句最多导致最后一个线程块中的某些线程束发生分支发散,故一般来说不会显著 影响程序的性能。然而,正如我们强调过的,如果漏掉了该判断,则可能会导致灾难性的内 存错误。有时能够通过合并判断语句减少分支发散,正如在第9章的neighbor2gpu.cu程序中所做的那样。
另外,如果一个判断语句的两个分支中有一个分支不包含指令,那么即 使发生了分支发散也不会显著地影响程序性能。总之,须把程序的正确性放在第一位,不 能因为担心发生分支发散而不敢写判断语句。
从伏特架构开始,引入了独立线程调度(independentthreadscheduling)机制。每个线程 有自己的程序计数器。这使得伏特架构有了一些以前的架构所没有的新的线程束内同步与 通信的模式,从而提高了编程的灵活性,降低了移植已有CPU代码的难度。要实现独立线程 调度机制,一个代价是增加了寄存器负担:单个线程的程序计数器一般需要使用两个寄存 器。也就是说,伏特架构的独立线程调度机制使得SM中每个线程可利用的寄存器少了两个。 另外,独立线程调度机制使得假设了线程束同步(warpsynchronous)的代码变得不再安全。
例如,在数组归约的例子中,当线程号小于32时,省去线程块同步函数__syncthreads在 伏特架构之前是允许的做法,但从伏特架构开始便是不再安全的做法了。在下一节,我们介 绍一个比线程块同步函数__syncthreads粒度更细的线程束内同步函数__syncwarp。如 果要在伏特或者更高架构的GPU中运行一个使用了线程束同步假设的程序,则可以在编译 时将虚拟架构指定为低于伏特架构的计算能力。
2.线程束内的线程同步函数
在归约问题中,当所涉及的线程都在一个线程束内时,可以将线程块同步函数__syncthreads()换成一个更加廉价的线程束同步函数__syncwarp()。我们将它简称为束内同步函数。
该函数的原型为:
void __syncwarp(unsigned mask = 0xffffffff);该函数有一个可选的参数。该参数是一个代表掩码的无符号整型数,默认值的全部32个二 进制位都为1,代表线程束中的所有线程都参与同步。如果要排除一些线程,可以用一个对 应的二进制位为0的掩码参数。例如,掩码0xfffffffe代表排除第0号线程。
现在利用上述函数来改写第九节的归约核函数。
void __global__ reduce_syncwarp(const real* d_x, real* d_y, const int N) {
const int tid = threadIdx.x;
const int bid = blockIdx.x;
const int n = bid * blockDim.x + tid;
extern __shared__ real s_y[];//动态共享内存
s_y[tid] = (n < N) ? d_x[n] : 0.0;
__syncthreads();
for (int offset = blockDim.x >> 1; offset >= 32; offset >>= 1) {
if (tid < offset) {
s_y[tid] += s_y[tid + offset];
}
__syncthreads();
}
//当 offset >= 32 时,我们在每一次折半求和后使用线程块同步函数 __syncthreads;
for (int offset = 16; offset > 0; offset >>= 1) {
if (tid < offset) {
s_y[tid] += s_y[tid + offset];
}
//不加if 会出现读-写竞争情形(racecondition)
__syncwarp();
}
//当 offset <= 16 时,我们在每一次折半求和后使用束内同步函数__syncwarp。
//束内同步函数__syncwarp确实比线程块同步函数__syncthreads高效。
if (tid == 0) {
atomicAdd(d_y, s_y[0]);
}
}上面的计算是分成两部分,当折半归约在几个线程块之间运行时,采用线程块同步,即offset >= 32时。当折半归约是在线程内时,采用线程束同步函数,即__syncwarp();
3.更多线程束内的基本函数
线程束表决函数(warp vote functions)、线程束匹配函数(warp match functions)、线程束洗牌函数(warp shuffle functions)及线程束矩阵函数(warp matrix functions)。
线程束表决函数的原型:
unsigned __ballot_sync(unsigned mask, int predicate);
int __all_sync(unsigned mask, int predicate);
int __any_sync(unsigned mask, int predicate);线程束洗牌函数的原型:
T __shfl_sync(unsigned mask, T v, int srcLane, int w = warpSize);
T __shfl_up_sync(unsigned mask, T v, unsigned d, int w = warpSize);
T __shfl_down_sync(unsigned mask, T v, unsigned d, int w = warpSize);
T __shfl_xor_sync(unsigned mask, T v, int laneMask, int w = warpSize);其中,类型T可以为整型(int)、长整型(long)、长长整型(long long)、无符号整型 (unsigned)、无符号长整型(unsigned long)、无符号长长整型(unsigned long long)、 单精度浮点型(float)及双精度浮点型(double)。
每个线程束洗牌函数的最后一个参数w都是可选的,有默认值warpSize,在当前所有架构的GPU中都是32。参数w只能取2、 4、8、16、32 这5个整数中的一个。当w小于32时,就相当于(逻辑上的)线程束大小 是w,而不是32,其他规则不变。对于一般的情况,可以定义一个“束内指标”(假设使用 一维线程块):
int lane_id = threadIdx.x % w;
赋值号右边的取模计算可以用更高效的按位与(bit-wiseand)表示:
int lane_id = threadIdx.x & (w- 1);但当w是常量时,编译器会自动优化该计算。假如线程块大小为16,w为8,则一个线程 块中各个线程的线程指标和束内指标有如下对应关系:

对于其他任何情况(任何线程块大小和任何w值),在使用线程束内的函数时都需要特别注 意线程指标和束内指标的对应关系。
以上函数中的参数mask称为掩码,是一个无符号整数,具有32位。这32个二进制位 从右边数起刚好对应线程束内的32个线程。该整数的32个二进制位要么是0,要么是1。 比如,常量掩码
const unsigned FULL_MASK = 0xffffffff;是32个二进制位都取1的无符号整数的十六进制表示。当然,该常量也可以用宏来定义:
#define FULL_MASK = 0xffffffff掩码用于指定将要参与计算的线程:当掩码中的一个二进制位为1时,代表对应的线程参 与计算;当掩码中的一个二进制位为0时,代表忽略对应的线程。特别地,各种函数返回 的结果对被掩码排除的线程来说是没有定义的。所以,不要尝试在这些被排除的线程中使 用函数的返回值。
这些函数的功能如下:
• __ballot_sync(mask, predicate):该函数返回一个无符号整数。如果线程束内 第个线程参与计算且predicate 值非零,则将所返回无符号整数的第个二进 制位取为1,否则取为0。这里,参与的线程对应于mask中取1的比特位。该函数的 功能相当于从一个旧的掩码出发,产生一个新的掩码。
• __all_sync(mask, predicate):线程束内所有参与线程的 predicate 值都不为零 才返回1,否则返回0。这里,参与的线程对应于mask中取1的比特位。该函数实现 了一个“规约-广播”(reduction-and-broadcast)式计算。该函数类似于这样一种选举 操作:当所有参选人都同意时才通过。
• __any_sync(mask, predicate,):线程束内所有参与线程的predicate值有一个不为零就返回1,否则返回0。这里,参与的线程对应于mask中取1的比特位。该函数 也实现了一个“规约-广播”式计算。该函数类似于这样一种选举操作:只要有一个参选人同意就通过。
• __shfl_sync(mask, v, srcLane, w):参与线程返回标号为srcLane的线程中变量v的值。这是一种广播式数据交换:将一个线程中的数据广播到所有(包括自己) 线程。
• __shfl_up_sync(mask,v,d,w):标号为t的参与线程返回标号为t-d的线程中 变量v的值。标号满足t-d<0的线程返回原来的v。例如:当w=8,d=2时, 该函数将第0-5号线程中变量v的值传送到第2-7号线程,而第0-1号线程返回它们原来的v。形象地说,这是一种将数据向上平移的操作。
• __shfl_down_sync(mask,v,d,w):标号为t的参与线程返回标号为t+d的线程 中变量v的值。标号满足t+d>=w的线程返回原来的v。例如:当w=8,d=2时, 该函数将第2-7号线程中变量v的值传送到第0-5号线程,而第6-7号线程返回它们 原来的v。形象地说,这是一种将数据向下平移的操作。
• __shfl_xor_sync(mask, v, laneMask, w):标号为t的参与线程返回标号 为t ^ laneMask的线程中变量v的值。这里,t ^ laneMask表示两个整数按位 异或运算的结果。例如,当w = 8,laneMask = 2时,第0-7号线程的按位异或运 算t ^laneMask分别如下:
该函数让线程束内的线 程两两交换数据。

该函数让线程束内的线 程两两交换数据。
0,2
1,3
4,6
5,7 序号两两交换。
来看看使用线程束函数的代码与对应输出。
#include "error.cuh"
#include <stdio.h>
#include <stdlib.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
const unsigned WIDTH = 8;
const unsigned BLOCK_SIZE = 16;
const unsigned FULL_MASK = 0xffffffff;
void __global__ test_warp_primitives(void);
int main(int argc, char** argv)
{
test_warp_primitives << <1, BLOCK_SIZE >> > ();
CHECK(cudaDeviceSynchronize());
return 0;
}
void __global__ test_warp_primitives(void)
{
int tid = threadIdx.x;
int lane_id = tid % WIDTH;
if (tid == 0) printf("threadIdx.x: ");
printf("%2d ", tid);
if (tid == 0) printf("\n");
if (tid == 0) printf("lane_id: ");
printf("%2d ", lane_id);
if (tid == 0) printf("\n");
unsigned mask1 = __ballot_sync(FULL_MASK, tid > 0);
unsigned mask2 = __ballot_sync(FULL_MASK, tid == 0);
if (tid == 0) printf("FULL_MASK = %x\n", FULL_MASK);
if (tid == 1) printf("mask1 = %x\n", mask1);
if (tid == 0) printf("mask2 = %x\n", mask2);
int result = __all_sync(FULL_MASK, tid);
if (tid == 0) printf("all_sync (FULL_MASK): %d\n", result);
result = __all_sync(mask1, tid);
if (tid == 1) printf("all_sync (mask1): %d\n", result);
result = __any_sync(FULL_MASK, tid);
if (tid == 0) printf("any_sync (FULL_MASK): %d\n", result);
result = __any_sync(mask2, tid);
if (tid == 0) printf("any_sync (mask2): %d\n", result);
int value = __shfl_sync(FULL_MASK, tid, 2, WIDTH);
if (tid == 0) printf("shfl: ");
printf("%2d ", value);
if (tid == 0) printf("\n");
value = __shfl_up_sync(FULL_MASK, tid, 1, WIDTH);
if (tid == 0) printf("shfl_up: ");
printf("%2d ", value);
if (tid == 0) printf("\n");
value = __shfl_down_sync(FULL_MASK, tid, 1, WIDTH);
if (tid == 0) printf("shfl_down: ");
printf("%2d ", value);
if (tid == 0) printf("\n");
value = __shfl_xor_sync(FULL_MASK, tid, 1, WIDTH);
if (tid == 0) printf("shfl_xor: ");
printf("%2d ", value);
if (tid == 0) printf("\n");
}
在vs中运行时,线程束函数会报错,但问题不大,可以运行。
当然还有之前一直用的error.cuh文件。
#pragma once
#include <stdio.h>
#include <stdlib.h> //exit()函数在这个库
#define CHECK(call) \
do \
{ \
const cudaError_t error_code = call; \
if (error_code != cudaSuccess) \
{ \
printf("CUDA Error:\n"); \
printf(" File: %s\n", __FILE__); \
printf(" Line: %d\n", __LINE__); \
printf(" Error code: %d\n", error_code); \
printf(" Error text: %s\n", \
cudaGetErrorString(error_code)); \
exit(1); \
} \
} while (0)
这里我看了貌似在cuh文件中不加#include "cuda_runtime.h"也没事。系统会自动运行好。
如果报错,gpt说要看gpu架构,cuda架构适不适合啥的,以及把项目之前的生成文件删了。我的建议是直接删项目,重新建项目,然后加文件,加代码。先不要调试,看看又没有少库啥的,主要看红色保存部分。
这里我总结一下,在vs中跑cuda,出现红字的可能地方:
运行核函数的kernel<<<grid_size,block_size>>>();
以及使用线程块中线程同步函数,__syncthreads();
以及线程块中线程束中线程同步函数,__syncwarp();
还有就是上面的线程束的基本函数。
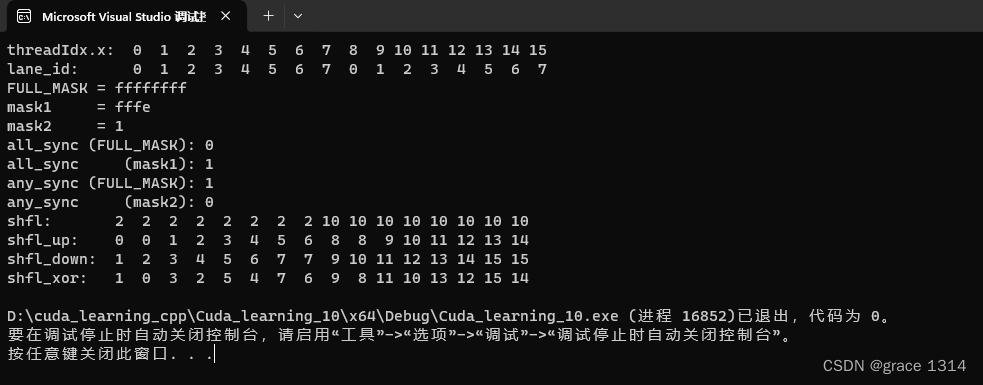
现在来看看运行结果
来跟着代码看看输出结果。
const unsigned WIDTH = 8; //线程束宽度
const unsigned BLOCK_SIZE = 16; //线程块大小这里选取了一个宽度为8的(逻辑上的)“线程束”和一个 大小为16的线程块
int tid = threadIdx.x;
int lane_id = tid % WIDTH; //定义束内线程号行定义了束内线程号lane_id。
if (tid == 0) printf("threadIdx.x: ");
printf("%2d ", tid);
if (tid == 0) printf("\n");打印线程号tid,对应程序输出的第1行:从0到15的16个数字。
其中,%2d ,2个字符的int数字,d表示10进制。
if (tid == 0) printf("lane_id: ");
printf("%2d ", lane_id);
if (tid == 0) printf("\n");![]()
屏幕打印束内线程号lane_id,对应程序输出的第2行:前8个数是从0到7, 后8个数也是从0到7。这就是说,我们将一个16线程的线程块分成了两部分,每部 分在逻辑上表现为一个迷你版的“线程束”。
unsigned mask1 = __ballot_sync(FULL_MASK, tid > 0);
unsigned mask2 = __ballot_sync(FULL_MASK, tid == 0);调用__ballot_sync函数从FULL_MASK出发计算mask1和mask2,分别 对应排除0号线程的掩码和仅保留0号线程的掩码。
if (tid == 0) printf("FULL_MASK = %x\n", FULL_MASK);
if (tid == 1) printf("mask1 = %x\n", mask1);
if (tid == 0) printf("mask2 = %x\n", mask2);输出3个掩码的十六进制表示(对应程序输出的第3-5行)

其中%x表示用16进制表示输出。
FULL_MASK是之前定义的全掩码,
mask1表示不包括除0号线程的掩码;
mask2表示只有包括除0号线程的掩码;
int result = __all_sync(FULL_MASK, tid);
if (tid == 0) printf("all_sync (FULL_MASK): %d\n", result);调用__all_sync函数,掩码为FULL_MASK。因为不是每个线程的predicate值 (这里取的线程号,线程号从0到15,0号线程的序号为0,bool返回假)都非零,故该函数的返回值为0(对应程序输出的第6行)。
![]()
再来说下__all_sync函数。

result = __all_sync(mask1, tid);
if (tid == 1) printf("all_sync (mask1): %d\n", result);![]()
继续调用__all_sync函数,掩码为mask1,排除了第0号线程。因为每个参与线程的predicate值(这里取的线程号)都非零,故该函数的返回值为1(对应程序输出的第7行)。
result = __any_sync(FULL_MASK, tid);
if (tid == 0) printf("any_sync (FULL_MASK): %d\n", result);![]()
调用__any_sync函数,掩码为FULL_MASK。因为不是每个线程的predicate值 (这里取的线程号)都为零,故该函数的返回值为1(对应程序输出的第8行)。(即全0才为0)

result = __any_sync(mask2, tid);
if (tid == 0) printf("any_sync (mask2): %d\n", result);![]()
继续调用__any_sync函数,掩码为mask2,只保留了第0号线程。因为该线 程的predicate值(这里取的线程号)为零,故该函数的返回值为0(输出的第9行),因为全部为0。
int value = __shfl_sync(FULL_MASK, tid, 2, WIDTH);
if (tid == 0) printf("shfl: ");
printf("%2d ", value);
if (tid == 0) printf("\n");![]()
调用__shfl_sync函数,将第2号线程的值广播到第0-7号线程,将第10号 线程的值广播到第8-15号线程(对应程序输出的第10行)。也就是说,线程束洗牌 函数是独立地作用在各个迷你版的“线程束”中的。

int value = __shfl_sync(FULL_MASK, tid, 2, WIDTH);再来看看这行代码。FULL_MASK,32位掩码且为0xffffffff,即表示线程束内的数据都将进行数据交换。tid是要共享的数据,即将下标当作数据,在个线程内进行交换。2表示线程束内的2号位置,从该位置获取数据。
如果你觉得难理解,看看这个图。

意思就是将线程束内线程号位2的元素值给线程束内的其他线程。这里付给的是该线程的下标,2,10。所以最后,块内线程号0~7是2,块内8~15是10。他们称作广播。本质是一种值平移
value = __shfl_up_sync(FULL_MASK, tid, 1, WIDTH);
if (tid == 0) printf("shfl_up: ");
printf("%2d ", value);
if (tid == 0) printf("\n");调用__shfl_up_sync函数,将第0-6号线程中的数据平移到第1-7号线程, 将第8-14号线程中的数据平移到第9-15号线程。第0号和第8号线程返回原来的输 入值(对应程序输出的第11行)
![]()
这里与上面一样传输的值还是下标tid值,因为是FULLMASK所以是所有线程参与交换,1表示线程的偏移量。


这就是交换的示意图。up表示的意思应该是上方线程的偏移值
value = __shfl_down_sync(FULL_MASK, tid, 1, WIDTH);
if (tid == 0) printf("shfl_down: ");
printf("%2d ", value);
if (tid == 0) printf("\n");调用__shfl_down_sync函数,将第1-7号线程中的数据平移到第0-6号线 程,将第9-15号线程中的数据平移到第8-14号线程。第7号和第15号线程返回原来 的输入值(对应程序输出的第12行)。
![]()

与up相同,但对象不同down是下方线程偏移量。

学累了吧,在坚持一下,还有最后一个函数。
value = __shfl_xor_sync(FULL_MASK, tid, 1, WIDTH);
if (tid == 0) printf("shfl_xor: ");
printf("%2d ", value);
if (tid == 0) printf("\n");调用__shfl_xor_sync函数。其中,第三个参数1的二进制表示为0001。它 与线程号0-7做按位异或计算,效果是将相邻的两个线程号交换(请读者验证);它与 线程号8-15做按位异或计算,效果也是将相邻的两个线程号交换。所以得到第13行 的程序输出。
![]()

这里第3个参数是,laneMask 参数是一个用于指定与哪些线程进行异或运算的掩码。例如,如果 laneMask 为1,表示与相邻线程进行异或运算;如果为3,表示与相邻两个线程进行异或运算;以此类推。
可以试试,0001 与 0000(0),0001(1),0010(2),0011(3),0100(4),0101(5),0110(6),0111(7)进行异或运算。
异或运算,相同为0,不同为1。
这里0~7的结果是,0001(2),0000(0),0011(3),0001(1)等等,后面可以自己对着算算。
第10章还有一些内容明天更。
---------------------------------------------------------------------------------------------------------------------------------
利用线程束洗牌函数进行归约计算,线程束洗牌函数, 其中函数__shfl_down_sync的作用是将高线程号的数据平移到低线程号中去,这正是 在我们的归约问题中需要的操作。
代码:
void __global__ reduce_shfl(const real* d_x, real* d_y, const int N)
{
// 参数 d_x 输入数组 ,d_y 输出结果,N,输入数组的长度
const int tid = threadIdx.x;//每个线程块内的线程id
const int bid = blockIdx.x; //当前线程所在的线程块id
const int n = bid * blockDim.x + tid; //当前线程全局索引id
extern __shared__ real s_y[]; //分配共享内存,每个线程块都有一个共享内存
s_y[tid] = (n < N) ? d_x[n] : 0.0; //将数据从全局内存(通常是 d_x 数组)拷贝到共享内存 s_y 中的操作。
//当n>N表示不是数组内的元素,给赋值为零
__syncthreads(); //等待所有线程块内的所有线程同步,确保共享内存数据已经准备好。
for (int offset = blockDim.x >> 1; offset >= 32; offset >>= 1)
{
if (tid < offset)
{
s_y[tid] += s_y[tid + offset];
}
__syncthreads();
}
//在每个线程块内的线程执行折半归约,用的是tid,不是n,所以是所有线程块同步执行
//for循环内线程块的线程执行折半归约,if (tid < offset)确保每次折半执行完成,
// 不会出现这次折半归约还没完成,下次就开始了
//__syncthreads(); 也是一种确保,线程块内的所有线程同步。
//存放的结果的位置还是共享内存
//offset初始为block大小的一般,每次减小一半,直到为一个线程束大小32.
real y = s_y[tid]; //这行代码从共享内存中获取每个线程块最终的归约结果
//存储在变量y中。一般y是在线程的寄存器中。
// s_y[tid]存储的是每个线程块折半归约计算的结果,所以y也是。
//但是因为s_y是在每个线程块中都有,所有不能单纯理解为只有一个
//而是每个线程块都有。按照上面应该是32个值。
for (int offset = 16; offset > 0; offset >>= 1)
{
y += __shfl_down_sync(FULL_MASK, y, offset);
}
//在线程束内进行归约折半。原理是一样的,但是在线程束内的用的是函数
// 这里使用的是线程块内线程束的洗牌函数__shfl_down_sync。
// __shfl_down_sync(FULL_MASK, y, offset),FULL_MASK是32个线程都参与,移动,y指的是移动的值,offset指每次移动量。
// down如果是在一维中表示向右,即向标号小的方向移动,每次偏移offset。
// 这里假设第一次偏移是16,那么就是16号偏移到0号,31号偏移到15号并与当前线程值做累加。
//进行再次归约折半。
//这样就得到每个线程块内的归约结果。
if (tid == 0)
{
atomicAdd(d_y, y);
}
//将所有线程块tid = 0中的y值拿出来累加,给d_y得到最终结果。
// 原子函数可以保证一个线程没进行完操作,下一个线程不会启动操作。
//使用原子操作将最终的归约结果 y 添加到全局内存的输出数组 d_y 中,以确保线程块之间的数据一致性。
}上面一些注释是我的一些理解,如果有问题,可以交流,我更正。
总结来说就是,先是从全局内存拿数据到共享内存,然后每个线程块内进行规约计算,每个线程块计算到线程束大小,将结果数据放到线程的寄存器中,再进行线程束规约计算,完了后再把每个线程块程块结果拿一块累加,得到最终累加结果。
y+=__shfl_down_sync(FULL_MASK,y,offset);这一句替换了
if(tid <offset) {
s_y[tid]+= s_y[tid+offset];
}
__syncwarp();第一,在进行线程束内的循环之前,这里将共 享内存中的数据复制到了寄存器。在线程束内使用洗牌函数进行规约时,不再需要明显地 使用共享内存。因为寄存器一般来说比共享内存更高效,所以能用寄存器就当然用寄存器 了。
第二,也就是说,去掉了同步函数,也去掉了对线程号的限制,因为洗牌函数能够自动处理同步与 读-写竞争问题。对全部参与的线程来说,上述洗牌函数总是先读取各个线程中y的值,再 将洗牌操作的结果写入各个线程中的y。另外,请读者仔细体会以上用洗牌函数与不用洗 牌函数的版本在结果上的等价性。实际上,在我们的归约问题中,将__shfl_down_sync换 成__shfl_xor_sync ,效果是一样的。
4.协作组
CUDA协作组详解_cuda cooperative group_扫地的小何尚的博客-CSDN博客
协作组这块在win上面的使用建议先看这篇博客对11.0协作组的讲解。
以及CUDA 11.6 工具包发布新版本 - NVIDIA 技术博客
因为我使用的是11.6,协作组这块命名空间,类,函数等已经有了很大的更新
而现在所学的CUDA编程与实践的这本书,还停留在老版本。
我在学习的过程中会综合其内容讲解。


在有些并行算法中,需要若干线程间的协作。要协 作,就必须要有同步机制。协作组(cooperativegroups)可以看作是线程块和线程束同步机制的推广,它提供了更为灵活的线程协作方式,包括线程块内部的同步与协作、线程块之间的(网格级的)同步与协作及设备之间的同步与协作。

使用协作组的头文件:
// Primary header is compatible with pre-C++11, collective algorithm headers require C++11
#include <cooperative_groups.h>
// Optionally include for memcpy_async() collective
#include <cooperative_groups/memcpy_async.h>
// Optionally include for reduce() collective
#include <cooperative_groups/reduce.h>
// Optionally include for inclusive_scan() and exclusive_scan() collectives
#include <cooperative_groups/scan.h>
协作组命名空间:
using namespace cooperative_groups;
// Alternatively use an alias to avoid polluting the namespace with collective algorithms
namespace cg = cooperative_groups;
以上是cuda11.0的。
由于学到这里,已经进入cuda编程后半期,其内容更难,需要花大量时间掌握,所以后面先看原理。后面会补充代码与结果。

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)