
社区发现(三):SLPA算法(标签传播算法拓展)
引用:https://blog.csdn.net/itplus/article/details/9286905引用:https://baike.baidu.com/item/SLPA/19507920文章目录1. SLPA算法介绍2. 算法阶段3. 算法步骤4. 算法优点1. SLPA算法介绍SLPA(Speaker-listener Label Propagation Algorithm)由Ji
引用:https://blog.csdn.net/itplus/article/details/9286905
引用:https://baike.baidu.com/item/SLPA/19507920
1. SLPA算法介绍
SLPA(Speaker-listener Label Propagation Algorithm)由Jierui Xie等人于2011年提出。
相应的数据软件包(C++/Java)
GANXiS(https://sites.google.com/site/communitydetectionslpa/)
SLPA是一种重叠型社区发现算法,其中涉及一个重要阈值参数r,通过r的适当选取,可将其退化为非重叠型
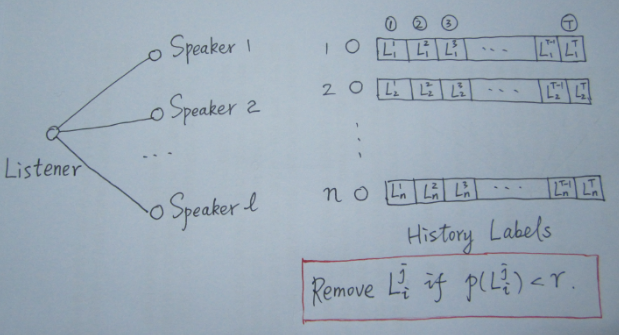
SLPA 中引入了 Listener 和 Speaker 两个比较形象的概念,你可以这么来理解:在刷新节点标签的过程中,任意选取一个节点作为 listener,则其所有邻居节点就是它的 speaker 了,speaker 通常不止一个,一大群 speaker 在七嘴八舌时,listener 到底该听谁的呢?这时我们就需要制定一个规则。
在 LPA 中,我们以出现次数最多的标签来做决断,其实这就是一种规则。只不过在 SLPA 框架里,规则的选取比较多罢了(可以由用户指定)。
当然,与 LPA 相比,SLPA 最大的特点在于:它会记录每一个节点在刷新迭代过程中的历史标签序列(例如迭代 T 次,则每个节点将保存一个长度为 T 的序列,如上图所示),当迭代停止后,对每一个节点历史标签序列中各(互异)标签出现的频率做统计,按照某一给定的阀值过滤掉那些出现频率小的标签,剩下的即为该节点的标签(通常有多个)。
SLPA 后来被作者改名为 GANXiS,且软件包仍在不断更新中…
2. 算法阶段
SLPA分为以下三个阶段:SLPA(T, r)
T:用户定义的做大迭代数
r:处理后的阈值
(1) 首先,每一个节点的存储器中初始化一个唯一的标签。
(2) 然后,重复进行以下步骤,直到达到最大迭代T:
a. 选择一个节点作为监听器。
b. 所选节点的每个邻居随机选择概率正比于该标签在其存储器中的出现频率的标签,把所选择的标签发送到听众。
c. 监听器增加接收到的最流行的标签到内存。
(3) 最后,根据在存储器里的标签和阈值r,后处理被用于输出社区。
3. 算法步骤
(1) 初始化所有节点的标签信息,使得每个节点拥有唯一的标签。
(2) 最为主要的是标签传播过程。
1.当前节点作为一个listener。
2.当前节点的每一个邻居节点根据一定的speaking策略传递标签信息。
3.当前节点从邻居节点传播的标签信息集中根据一定的listener策略选择一个标签作为本次迭代中的新标签。
4.算法收敛或遍历达到指定的次数,算法结束。否则,标签在不断的遍历过程中传播。
(3) 标签分类过程。后处理阶段根据节点的标签信息进行社区发现。
4. 算法优点
算法SLPA 不会像其它算法一样忘记上一次迭代中节点所更新的标签信息,它给每个节点设置了一个标签存储列表来存储每次迭代所更新的标签。最终的节点社区从属关系将由标签存储列表中所观察到的标签的概率决定,当一个节点观察到有非常多一样的标签时,那么,很有可能这个节点属于这个社区,而且在传播过程中也很有可能将这个标签传播给别的节点。更有益处的是,这种标签存储列表的设计可以使得算法可以支持划分重叠社区。

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐
 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)