
社区发现算法———CPM算法
派系过滤CPM方法(clique percolation method)注意:(1)派系过滤CPM方法(clique percolation method)用于发现重叠社区,派系(clique)是任意两点都相连的顶点的集合,即完全子图。在社区内部节点之间连接密切,边密度高,容易形成派系(clique)。因此,社区内部的边有较大可能形成大的完全子图,而社区之间的边却几乎不可能形成较大的完全子图,从
派系过滤CPM方法(clique percolation method)
注意:
(1)派系过滤CPM方法(clique percolation method)用于发现重叠社区,派系(clique)是任意两点都相连的顶点的集合,即完全子图。
在社区内部节点之间连接密切,边密度高,容易形成派系(clique)。因此,社区内部的边有较大可能形成大的完全子图,而社区之间的边却几乎不可能形成较大的完全子图,从而可以通过找出网络中的派系来发现社区。
(2)k-派系表示网络中含有k个节点的完全子图,如果一个k-派系与另一个k-派系有k-1个节点重叠,则这两个k-派系是连通的。由所有彼此连通的k-派系构成的集合就是一个k-派系社区。
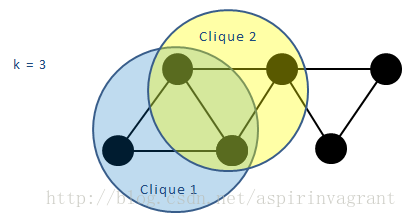
网络中会存在一些节点同时属于多个k-派系,但是它们所属的这些k-派系可能不相邻,它们所属的多个k-派系之间公共的节点数不足k-1个。这些节点同属的多个k-派系不是相互连通的,导致这几个k-派系不属于同一个k-派系社区,因此这些节点最终可以属于多个不同的社区,从而发现社区的重叠结构。
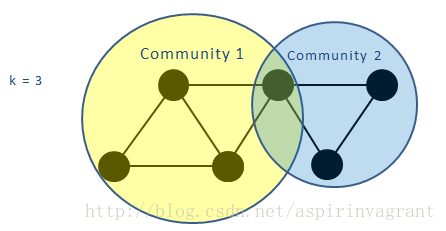
所以CPM算法的过程是首先寻找网络中极大的完全子图(maximal-cliques),这些极大完全子图简称为派系。(k-派系与派系的区别在于k-派系可以是更大的完全子图的子集。)然后利用这些完全子图来寻找k-派系的连通子图(即 k-派系社区),不同的k值对应不同的社区结构。找到所有的派系之后,可以建立这些派系的重叠矩阵(clique overlap matrix)。在这个对称的矩阵中,每一行(列)代表了一个派系,矩阵元素等于对应的两个派系之间的公共节点数,对角线项等于派系的大小。
对于给定k值的k-派系-社区等价于这样的连接集团组件,其中相邻的集团通过至少k−1个公共节点相互连接。将小于k-1的非对角线元素和小于k的对角线元素置为0,其他元素置为1,得到k-派系连接矩阵,每个连通部分构成了一个k-派系社区。
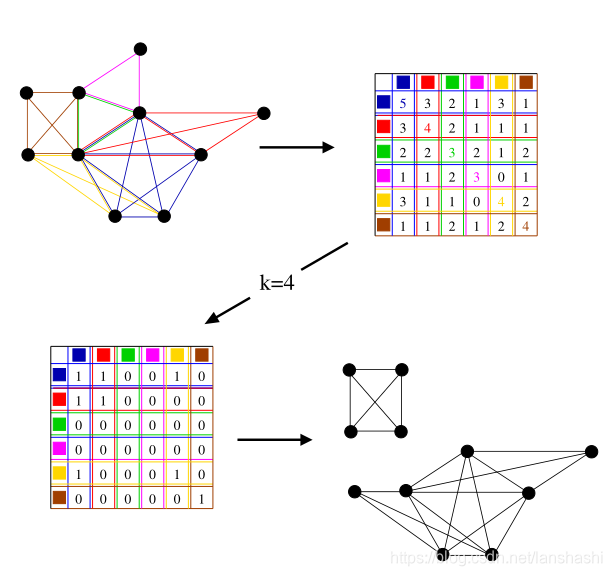
该方法的一个优点是,派系-派系重叠矩阵编码了对任意k值获取群落所需的所有信息,因此一旦构造了派系-派系重叠矩阵,就可以非常快速地获得k所有可能值的k-派系-社区。与此相反,在一个简单的k-派系查找方法中,对于每一个k值,都必须从头重新开始搜索k-派系。
由于k是个输入参数值,从而k的取值将会影响CMP算法的最终社区发现结果,当k取值越小社区将会越大,且社区结构为稀疏。但是实验证明k的取值影响不是很大,一般k值为4到6。然而,由于该算法是基于完全子图,因此CPM比较适用于完全子图比较多的网络,即边密集的网络,对于稀疏网络效率将会很低,且该算法还无法分配完全子图外的顶点。CPM的效率取决于寻找所有极大完全子图的效率,尽管寻找所有极大完全子图是NP完全问题,但在真实网络上是非常快的。
python代码如下:
def get_percolated_cliques(G, k):
cliques = list(frozenset(c) for c in nx.find_cliques(G) if len(c) >= k) # 找出所有大于k的最大k-派系
# print(cliques)
matrix = np.zeros((len(cliques), len(cliques))) # 构造全0的重叠矩阵
# print(matrix)
for i in range(len(cliques)):
for j in range(len(cliques)):
if i == j: # 将对角线值大于等于k的值设为1,否则设0
n = len(cliques[i])
if n >= k:
matrix[i][j] = 1
else:
matrix[i][j] = 0
else: # 将非对角线值大于等于k的值设为1,否则设0
n = len(cliques[i].intersection(cliques[j]))
if n >= k - 1:
matrix[i][j] = 1
else:
matrix[i][j] = 0
# print(matrix)
# for i in matrix:
# print(i)
# l = [-1]*len(cliques)
l = list(range(len(cliques))) # l(社区号)用来记录每个派系的连接情况,连接的话值相同
for i in range(len(matrix)):
for j in range(len(matrix)):
if matrix[i][j] == 1 and i != j: # 矩阵值等于1代表,行派系与列派系相连,让l中的行列派系社区号变一致
l[j] = l[i] # 让列派系与行派系社区号相同(划分为一个社区)
# print(l)
q = [] # 用来保存有哪些社区号
for i in l:
if i not in q: # 每个号只取一次
q.append(i)
# print(q)
p = [] # p用来保存所有社区
for i in q:
print(frozenset.union(*[cliques[j] for j in range(len(l)) if l[j] == i])) # 每个派系的节点取并集获得社区节点
p.append(list(frozenset.union(*[cliques[j] for j in range(len(l)) if l[j] == i])))
return p
但是重叠社区用Q值评估划分结果不再合适,我们需要引入EQ值计算:

代码如下:
def cal_EQ(cover, G):
m = len(G.edges(None, False)) # 如果为真,则返回3元组(u、v、ddict)中的边缘属性dict。如果为false,则返回2元组(u,v)
# 存储每个节点所在的社区
vertex_community = collections.defaultdict(lambda: set())
# i为社区编号(第几个社区) c为该社区中拥有的节点
for i, c in enumerate(cover):
# v为社区中的某一个节点
for v in c:
# 根据节点v统计他所在的社区i有哪些
vertex_community[v].add(i)
total = 0.0
for c in cover:
for i in c:
# o_i表示i节点所同时属于的社区数目
o_i = len(vertex_community[i])
# k_i表示i节点的度数(所关联的边数)
k_i = len(G[i])
for j in c:
t = 0.0
# o_j表示j节点所同时属于的社区数目
o_j = len(vertex_community[j])
# k_j表示j节点的度数(所关联的边数)
k_j = len(G[j])
if G.has_edge(i, j):
t += 1.0 / (o_i * o_j)
t -= k_i * k_j / (2 * m * o_i * o_j)
total += t
return round(total / (2 * m), 4)
结果如下:
frozenset({1, 17, 25, 26, 27})
frozenset({32, 1, 5, 6, 41, 9, 13, 17, 54, 57})
frozenset({1, 19, 54, 7, 30})
frozenset({2, 10, 42})
frozenset({0, 8, 42, 10, 47, 20, 28, 30})
frozenset({8, 59, 3})
frozenset({8, 45, 15, 18, 51, 50, 21, 23, 24, 59, 29})
frozenset({33, 34, 36, 37, 38, 8, 40, 43, 44, 45, 14, 16, 50, 52, 20, 21})
frozenset({0, 40, 14, 15})
0.3229
代码与数据集下载github

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 5
5 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)