

基于t-SNE的Digits数据集降维与可视化
t-SNE(t-分布随机邻域嵌入)是一种基于流形学习的非线性降维算法,非常适用于将高维数据降维到2维或者3维,进行可视化观察。t-SNE被认为是效果最好的数据降维算法之一,缺点是计算复杂度高、占用内存大、降维速度比较慢。本任务的实践内容包括:1、 基于t-SNE算法实现Digits手写数字数据集的降维与可视化2、 对比PCA/LCA与t-SNE降维前后手写数字识别模型的性能。
基于t-SNE的Digits数据集降维与可视化
描述
t-SNE(t-分布随机邻域嵌入)是一种基于流形学习的非线性降维算法,非常适用于将高维数据降维到2维或者3维,进行可视化观察。t-SNE被认为是效果最好的数据降维算法之一,缺点是计算复杂度高、占用内存大、降维速度比较慢。
本任务的实践内容包括:
1、 基于t-SNE算法实现Digits手写数字数据集的降维与可视化
2、 对比PCA/LCA与t-SNE降维前后手写数字识别模型的性能
环境
-
操作系统:Windows 10、Ubuntu18.04
-
工具软件:Anaconda3 2019、Python3.7
-
硬件环境:无特殊要求
-
依赖库列表
matplotlib 3.3.4 scikit-learn 0.24.2
分析
Digits手写数字数据集包括1797张手写数字图片,每张图片代表0~9之间的1个数字,图片大小为8*8,即特征维度为64。任务中我们分别使用PCA、LDA和t-SNE三种算法将数据集降为2维,并可视化观察其数据分布情况,之后通过K-最近邻算法(K-NN)对三种算法降维后的数据集进行分类,对比其准确性。
本任务涉及以下几个环节:
a)加载Digits数据集
b)分别使用PCA、LDA、t-SNE算法进行降维(由64维降2维)
c)使用K-NN分类器分别在三种算法降维后的数据上建模
d)对比评估模型的准确性
实施
1、加载Digits数据集
import matplotlib.pyplot as plt
from time import time
from sklearn.datasets import load_digits
from sklearn.manifold import TSNE
from sklearn.decomposition import PCA
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
# 加载Digits数据集
digits = load_digits()
data = digits.data
target = digits.target
print(data.shape) # 查看数据维度(64)
# 可视化降维后的数据
def show_pic(new_data, target, label):
plt.title(label)
plt.scatter(new_data[:, 0], new_data[:, 1], c=target)
plt.show()
结果如下:
(1797, 64)
Digits数据集包括1797张图片样本,特征维度为64(图片大小8×8)。
2、使用不同算法将数据降为2维,并可视化
首先,分别使用PCA、LDA、t-SNE三种算法将Digits数据集由64维降为2维,然后调用上面自定义的show_pic方法将降维后的数据可视化。
# 使用不同的算法将数据降为2维
# 1、PCA降维可视化
pca = PCA(n_components=2).fit(data)
pca_data = pca.transform(data) # 降维转换
show_pic(pca_data, target, 'PCA')
# 2、LDA降维可视化
lda = LinearDiscriminantAnalysis(n_components=2).fit(data, target)
lda_data = lda.transform(data) # 降维转换
show_pic(lda_data, target, 'LDA')
# 3、TSNE降维可视化(计算复杂度高,较慢)
print(' t-SNE降维中,请耐心等待......')
start = time() # 开始时间
tsne = TSNE(n_components=2, init='pca', random_state=0)
tsne_data = tsne.fit_transform(data)
end = time() # 完成时间
show_pic(tsne_data, target, 't-SNE (cost {:.1f} seconds)'.format(end-start))
输出结果:
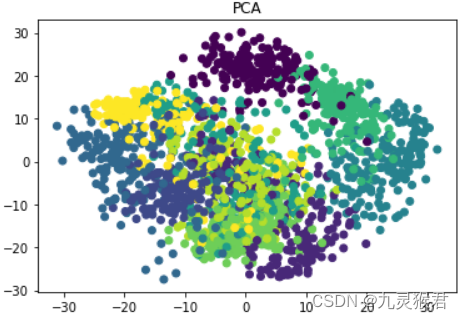
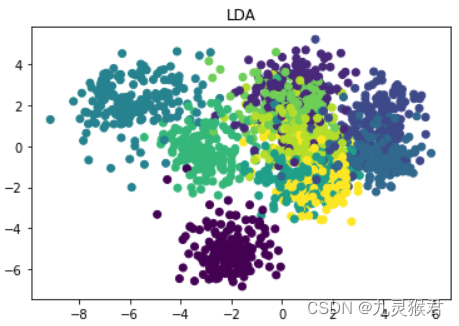
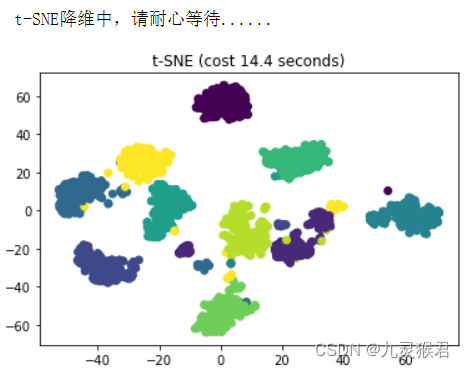
可以看到,将数据由64维降成2维后,PCA的数据已经混在一起,LDA数据可分性稍好一些,t-SNE的数据可分性最高,数据集中10种手写数字的样本彼此独立。t-SNE的降维效果十分出色,但算法的时间复杂度高。
3、评估三种算法降维后的分类准确性
接下来,使用K-NN分类器分别在上面三种算法降维后的数据上建立分类模型,并对比评估模型的准确性。
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# 评估三种算法降维后(均降成2维)的分类准确性(基于KNN算法)
def eval_model(new_data, target, label):
X_train, X_test, y_train, y_test = train_test_split(new_data, target, random_state=0) # 拆分数据集
model = KNeighborsClassifier(3).fit(X_train, y_train)
score = model.score(X_test, y_test) # 在测试集上评估模型成绩
print(label, score) # 打印模型成绩
print('Digits数据集由64维降成2维后,使用K-NN分类准确性对比:')
eval_model(pca_data, target, 'PCA accuracy:')
eval_model(lda_data, target, 'PDA accuracy:')
eval_model(tsne_data, target, 't-SNE accuracy:')
结果如下:
Digits数据集由64维降成2维后,使用K-NN分类准确性对比:
PCA accuracy: 0.5888888888888889
PDA accuracy: 0.6422222222222222
t-SNE accuracy: 0.9955555555555555
可以看到,在三种降维算法中,t-SNE降维后的数据分类准确性最高,该算法是目前效果最好的降维算法之一,Digits数据集即便被降成2维,依然保持了良好的可分性。

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)