
LSTM复现(源github)
LSTM 时间序列预测
本文重点介绍如何使用深度LSTM神经网络架构来提供使用Keras和Tensorflow的多维时间序列预测 - 特别是在股票市场数据集上,以提供股票价格的动量指标。
此框架的代码可以在以下 GitHub 存储库中找到(它假定 python 版本 3.5.x 和需求.txt文件中的需求版本。偏离这些版本可能会导致错误):https://github.com/jaungiers/LSTM-Neural-Network-for-Time-Series-Prediction
以下文章部分将简要介绍LSTM神经元细胞,给出一个预测正弦波的玩具示例,然后通过应用程序浏览到随机时间序列。本文需要简单深度神经网络的基本知识作为基础。
什么是LSTM神经元?
长期困扰传统神经网络架构的基本问题之一是能够解释相互依赖信息和上下文的输入序列。该信息可以是句子中的前一个单词,以允许上下文预测下一个单词可能是什么,也可以是序列的时间信息,这将允许该序列中基于时间的元素的上下文。
简而言之,传统的神经网络每次都会接受一个独立的数据向量,并且没有记忆的概念来帮助它们完成需要内存的任务。
解决这个问题的早期尝试是对网络中的神经元使用简单的反馈类型方法,其中输出被反馈到输入中,以提供最后看到的输入的上下文。这些被称为递归神经网络(RNN)。虽然这些RNN在一定程度上起作用,但它们有一个相当大的缺点,即它们的任何重大用途都会导致一个称为消失梯度问题的问题。我们不会进一步扩展渐变问题,只是说RNN由于这个问题而不适合大多数现实世界的问题,因此,需要找到另一种解决上下文记忆的方法。
这就是长短期记忆(LSTM)神经网络拯救的地方。与RNN神经元一样,LSTM神经元在其管道中保留了内存上下文,以允许处理顺序和时间问题,而不会出现影响其性能的消失梯度的问题。
许多研究论文和文章可以在网上找到,这些论文和文章以非常详细的数学细节讨论了LSTM细胞的工作原理。然而,在本文中,我们不会讨论LSTM的复杂工作原理,因为我们更关心它们用于我们的问题。
下面是LSTM神经元的典型内部工作原理图。它由几层和逐点操作组成,这些操作充当数据输入,输出的门,并忘记哪个馈送LSTM单元状态。这种单元状态是在整个网络和输入中保持长期记忆和上下文的原因。

一个简单的例子 正弦函数
为了演示LSTM神经网络在预测时间序列中的应用,让我们从我们能想到的最基本的东西开始,那就是时间序列:可信的正弦波。让我们创建需要的数据来模拟这个函数的许多振荡,以便LSTM网络进行训练。
代码数据文件夹中提供的数据包含我们创建的正弦波.csv文件,其中包含正弦波的5001个时间段,其幅度和频率为1(角频率为6.28),时间增量为0.01。绘制时,结果如下所示:

现在我们有了数据,我们实际上想要实现什么?好吧,简单地说,我们希望LSTM从我们将提供给它的设定窗口大小的数据中学习正弦波,希望我们可以要求LSTM预测该系列中的下一个N步,它将继续输出正弦波。
我们首先将数据从CSV文件转换并加载到pandas数据帧,然后用于输出将馈送LSTM的numpy数组。Keras LSTM层的工作方式是采用3维(N,W,F)的numpy数组,其中N是训练序列的数量,W是序列长度,F是每个序列的特征数量。我们选择将序列长度(读取窗口大小)设置为50,可以瞥见每个序列处正弦波的形状,希望这样能够使它根据先前接收的窗口教会自己建立序列的模式。
序列本身是滑动窗口,因此每次偏移 1,从而与先前窗口的连续重叠。绘制序列长度为 50 的典型训练窗口如下所示:

为了加载此数据,我们在代码中创建了一个 DataLoader 类,以便抽象化数据加载层。你会注意到,在初始化 DataLoader 对象时,将传入文件名,以及一个 split 变量(用于确定用于训练与测试的数据百分比)和一个列变量(允许选择一列或多列数据进行单维或多维分析)。
class DataLoader():
def __init__(self, filename, split, cols):
dataframe = pd.read_csv(filename)
i_split = int(len(dataframe) * split)
self.data_train = dataframe.get(cols).values[:i_split]
self.data_test = dataframe.get(cols).values[i_split:]
self.len_train = len(self.data_train)
self.len_test = len(self.data_test)
self.len_train_windows = None
def get_train_data(self, seq_len, normalise):
data_x = []
data_y = []
for i in range(self.len_train - seq_len):
x, y = self._next_window(i, seq_len, normalise)
data_x.append(x)
data_y.append(y)
return np.array(data_x), np.array(data_y)
在我们有一个可以加载数据的数据对象之后,我们开始构建深度神经网络模型。同样,为了抽象化构建模型,我们的代码框架使用 Model 类和 config.json 文件,它给定了所需的体系结构和存储在配置文件中的超参数。构建我们网络的主要函数是build_model()函数,它接受解析的配置文件。
该函数代码如下,可以轻松扩展以将来在更复杂的体系结构上使用。
class Model():
def __init__(self):
self.model = Sequential()
def build_model(self, configs):
timer = Timer()
timer.start()
for layer in configs['model']['layers']:
neurons = layer['neurons'] if 'neurons' in layer else None
dropout_rate = layer['rate'] if 'rate' in layer else None
activation = layer['activation'] if 'activation' in layer else None
return_seq = layer['return_seq'] if 'return_seq' in layer else None
input_timesteps = layer['input_timesteps'] if 'input_timesteps' in layer else None
input_dim = layer['input_dim'] if 'input_dim' in layer else None
if layer['type'] == 'dense':
self.model.add(Dense(neurons, activation=activation))
if layer['type'] == 'lstm':
self.model.add(LSTM(neurons, input_shape=(input_timesteps, input_dim), return_sequences=return_seq))
if layer['type'] == 'dropout':
self.model.add(Dropout(dropout_rate))
self.model.compile(loss=configs['model']['loss'], optimizer=configs['model']['optimizer'])
print('[Model] Model Compiled')
timer.stop()
加载数据并构建模型后,我们现在可以继续使用训练数据训练模型。为此,我们创建了一个单独的运行模块,该模块将利用我们的模型和DataLoader抽象来组合它们进行训练,输出和可视化。
下面是用于训练模型的常规运行线程代码:
configs = json.load(open('config.json', 'r'))
data = DataLoader(
os.path.join('data', configs['data']['filename']),
configs['data']['train_test_split'],
configs['data']['columns']
)
model = Model()
model.build_model(configs)
x, y = data.get_train_data(
seq_len = configs['data']['sequence_length'],
normalise = configs['data']['normalise']
)
model.train(
x,
y,
epochs = configs['training']['epochs'],
batch_size = configs['training']['batch_size']
)
x_test, y_test = data.get_test_data(
seq_len = configs['data']['sequence_length'],
normalise = configs['data']['normalise']
)
对于输出,我们将运行两种类型的预测:
第一种是逐点预测,即我们每次只预测一个点,将此点绘制为预测,然后将下一个窗口与完整的测试数据一起获取,并再次预测下一个点。
第二个预测是预测一个完整的序列,通过这种方式,我们只初始化一次训练窗口,其中包含训练数据的第一部分。然后,模型预测下一个点,然后我们移动窗口,就像逐点方法一样。
不同之处在于,我们使用在先前预测中预测的数据进行预测。在第二步中,这意味着只有一个数据点(最后一个点)将来自先前的预测。
在第三个预测中,最后两个数据点将来自先前的预测,依此类推。
在 50 次预测之后,我们的模型随后将根据自己的先前预测进行预测。这允许我们使用模型来预测前面的许多时间步,但是由于它是根据预测进行预测的,而预测又可以基于预测,这将增加预测的错误率,因为我们预测得越远。
下面我们可以看到逐点预测和全序列预测的代码和相应输出。
def predict_point_by_point(self, data):
#Predict each timestep given the last sequence of true data, in effect only predicting 1 step ahead each time
predicted = self.model.predict(data)
predicted = np.reshape(predicted, (predicted.size,))
return predicted
def predict_sequence_full(self, data, window_size):
#Shift the window by 1 new prediction each time, re-run predictions on new window
curr_frame = data[0]
predicted = []
for i in range(len(data)):
predicted.append(self.model.predict(curr_frame[newaxis,:,:])[0,0])
curr_frame = curr_frame[1:]
curr_frame = np.insert(curr_frame, [window_size-2], predicted[-1], axis=0)
return predicted
predictions_pointbypoint = model.predict_point_by_point(x_test)
plot_results(predictions_pointbypoint, y_test)
predictions_fullseq = model.predict_sequence_full(x_test, configs['data']['sequence_length'])
plot_results(predictions_fullseq, y_test)


作为参考,用于正弦波示例的网络架构和超参数可以在下面的配置文件中看到。
{
"data": {
"filename": "sinewave.csv",
"columns": [
"sinewave"
],
"sequence_length": 50,
"train_test_split": 0.8,
"normalise": false
},
"training": {
"epochs": 2,
"batch_size": 32
},
"model": {
"loss": "mse",
"optimizer": "adam",
"layers": [
{
"type": "lstm",
"neurons": 50,
"input_timesteps": 49,
"input_dim": 1,
"return_seq": true
},
{
"type": "dropout",
"rate": 0.05
},
{
"type": "lstm",
"neurons": 100,
"return_seq": false
},
{
"type": "dropout",
"rate": 0.05
},
{
"type": "dense",
"neurons": 1,
"activation": "linear"
}
]
}
}
用真实数据覆盖,我们可以看到,只有1个epoch和一个相当小的训练数据集,LSTM深度神经网络已经在预测正弦函数方面做得很好。
随着我们对未来的预测越来越多,误差幅度会增加,因为先前预测中的误差在用于未来预测时会越来越大。因此,我们看到,在全序列示例中,我们预测得越远,预测的频率和幅度与真实数据相比就越不准确。然而,由于sin函数是一个非常容易振荡的函数,噪声为零,它仍然可以很好地预测它而不会过度拟合 — 这很重要,因为我们可以通过增加Epoch数并取出drop层来拟合模型,使其在此训练数据上几乎完全准确,这与测试数据具有相同的模式, 但对于其他实际示例,将模型过度拟合到训练数据上会导致测试精度直线下降(plummet崩掉),因为模型不会泛化。
在下一步中,我们将尝试在此类真实数据上使用模型来查看效果。
一个并不简单的股市市场模拟
我们准确地逐点预测了正弦波的几百个时间步长。因此,我们现在可以在股票市场时间序列上做同样的事情,并立即获利,对吧?不幸的是,在现实世界中,这并不是那么简单。
与正弦波不同,股票市场时间序列不是任何可以映射的特定静态函数。描述股票市场时间序列运动的最佳属性是随机游走。作为一个随机过程,真正的随机游走没有可预测的模式,因此尝试建模是毫无意义的。幸运的是,许多方面一直在争论说,股票市场不是一个纯粹的随机过程,这使我们能够从理论上认为时间序列很可能具有某种隐藏的模式。由于可能有隐藏的特征,LSTM深度网络被寄予厚望。
此示例将使用的数据是数据文件夹中的 sp500.csv 文件。本文件包含 2000 年 1 月至 2018 年 9 月标准普尔 500 股票指数的开盘价、最高价、最低价、收盘价以及每日交易量。
首先,我们将仅使用收盘价创建单维模型。调整config.json文件以反映新数据,我们将保持大多数参数相同。然而,需要改变的一点是,与只有-1到+1之间的数字范围的正弦波不同,收盘价是股票市场不断变化的绝对价格。这意味着,如果我们试图在不规范化模型的情况下对其进行训练,它永远不会收敛。
为了解决这个问题,我们将获取每个n大小的训练/测试数据窗口,并对每个窗口进行标准化,以反映从该窗口开始的百分比变化(因此点i = 0处的数据将始终为0)。我们将使用以下等式进行归一化,然后在预测过程结束时进行反归一化,以从预测中获得真实世界的数字:
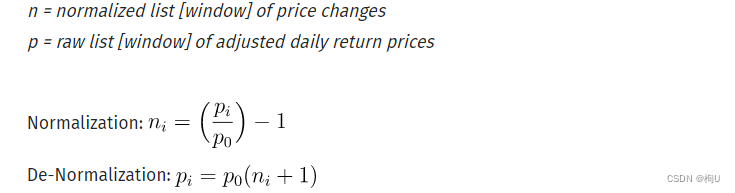
我们已将 normalise_windows() 函数添加到 DataLoader 类中以执行此转换,并且配置文件中包含一个布尔规范化标志,该标志表示这些窗口的标准化。
def normalise_windows(self, window_data, single_window=False):
'''Normalise window with a base value of zero'''
normalised_data = []
window_data = [window_data] if single_window else window_data
for window in window_data:
normalised_window = []
for col_i in range(window.shape[1]):
normalised_col = [((float(p) / float(window[0, col_i])) - 1) for p in window[:, col_i]]
normalised_window.append(normalised_col)
# reshape and transpose array back into original multidimensional format
normalised_window = np.array(normalised_window).T
normalised_data.append(normalised_window)
return np.array(normalised_data)
通过对窗口进行标准化,我们现在可以像对正弦波数据运行模型一样运行模型。但是,在运行此数据时,我们进行了重要的更改。我们没有使用我们框架的 model.train() 方法,而是使用我们创建的 model.train_generator() 方法。我们这样做是因为我们发现,在尝试训练大型数据集时,很容易耗尽内存,因为 model.train() 函数将整个数据集加载到内存中,然后将规范化应用于内存中的每个窗口,很容易导致内存溢出。因此,我们利用 Keras 的 fit_generator() 函数,允许使用 python 生成器动态训练数据集来绘制数据,这意味着内存利用率将显著降低。
下面的代码详细介绍了用于运行三种类型的预测(逐点、完整序列和多序列)的新运行线程。
configs = json.load(open('config.json', 'r'))
data = DataLoader(
os.path.join('data', configs['data']['filename']),
configs['data']['train_test_split'],
configs['data']['columns']
)
model = Model()
model.build_model(configs)
x, y = data.get_train_data(
seq_len = configs['data']['sequence_length'],
normalise = configs['data']['normalise']
)
# out-of memory generative training
steps_per_epoch = math.ceil((data.len_train - configs['data']['sequence_length']) / configs['training']['batch_size'])
model.train_generator(
data_gen = data.generate_train_batch(
seq_len = configs['data']['sequence_length'],
batch_size = configs['training']['batch_size'],
normalise = configs['data']['normalise']
),
epochs = configs['training']['epochs'],
batch_size = configs['training']['batch_size'],
steps_per_epoch = steps_per_epoch
)
x_test, y_test = data.get_test_data(
seq_len = configs['data']['sequence_length'],
normalise = configs['data']['normalise']
)
predictions_multiseq = model.predict_sequences_multiple(x_test, configs['data']['sequence_length'], configs['data']['sequence_length'])
predictions_fullseq = model.predict_sequence_full(x_test, configs['data']['sequence_length'])
predictions_pointbypoint = model.predict_point_by_point(x_test)
plot_results_multiple(predictions_multiseq, y_test, configs['data']['sequence_length'])
plot_results(predictions_fullseq, y_test)
plot_results(predictions_pointbypoint, y_test)
{
"data": {
"filename": "sp500.csv",
"columns": [
"Close"
],
"sequence_length": 50,
"train_test_split": 0.85,
"normalise": true
},
"training": {
"epochs": 1,
"batch_size": 32
},
"model": {
"loss": "mse",
"optimizer": "adam",
"layers": [
{
"type": "lstm",
"neurons": 100,
"input_timesteps": 49,
"input_dim": 1,
"return_seq": true
},
{
"type": "dropout",
"rate": 0.2
},
{
"type": "lstm",
"neurons": 100,
"return_seq": true
},
{
"type": "lstm",
"neurons": 100,
"return_seq": false
},
{
"type": "dropout",
"rate": 0.2
},
{
"type": "dense",
"neurons": 1,
"activation": "linear"
}
]
}
}
如上所述,在单个逐点预测上运行数据给出了与回报非常接近的东西。但这有点欺骗性。经过仔细检查,预测线由单一预测点组成,这些点背后有整个先前的真实历史窗口。因此,网络不需要对时间序列本身了解太多,除了每个下一个点很可能离最后一个点不会太远。因此,即使它对点的预测是错误的,下一个预测也会考虑真实的历史并忽略不正确的预测,再次允许犯错误。
虽然对于下一个价格点的准确预测来说,这最初听起来可能并不乐观,但它确实有一些重要的用途。虽然它不知道确切的下一个价格会是什么,但它确实给出了下一个价格应该在的范围内的非常准确的表示。
这些信息可用于波动率预测等应用程序(能够预测市场中的高波动性或低波动性时期对于特定的交易策略可能非常有利),或者除了交易之外,这也可以用作异常检测的良好指标。异常检测可以通过预测下一个点来实现,然后在进入时将其与真实数据进行比较,如果真实数据值与预测点明显不同,则可以为该数据点引发异常标志。

继续进行全序列预测,这似乎被证明是这种类型的时间序列最无用的预测(至少用这些超参数在此模型上训练)。我们可以在预测开始时看到一个轻微的颠簸,其中模型遵循某种动量,但是我们很快就可以看到模型决定最优化的模式是收敛到时间序列的某个平衡上。在这个阶段,这似乎并没有提供太多价值,但是平均回归交易者可能会介入那里,宣称该模型只是找到了价格序列将在波动性消除时恢复的平均值。

最后,我们为这个模型做了第三种类型的预测,我称之为多序列预测。这是完整序列预测的混合,因为它仍然使用测试数据初始化测试窗口,预测下一个点,并使用下一个点创建一个新窗口。但是,一旦它到达输入窗口完全由过去的预测组成的点,它就会停止,向前移动一个完整的窗口长度,使用真实的测试数据重置窗口,然后再次启动该过程。从本质上讲,这给出了对测试数据的多个趋势线般的预测,以便能够分析模型对未来动量趋势的了解程度。

从多序列预测中可以看出,网络似乎确实正确预测了大部分时间序列的趋势(和趋势幅度)。虽然并不完美,但它确实表明了LSTM深度神经网络在顺序和时间序列问题中的有用性。通过仔细的超参数调整,肯定可以实现更高的准确性。
多维的LSTM预测
到目前为止,我们的模型只接受单维输入(在我们的标准普尔500数据集中为“收盘价”)。但是对于更复杂的数据集,序列自然存在许多不同的维度,可用于增强数据集,从而提高模型的准确性。
在我们的标准S&P 500数据集中,我们可以看到我们有开盘价,最高价,最低价,收盘价和成交量,它们构成了五个可能的维度。我们开发的框架允许使用多维输入数据集,因此我们需要做的就是编辑列和Lstm第一层,input_dim值来运行我们的模型。在这种情况下,我将使用两个维度运行模型;“关闭”和“交易量”。
{
"data": {
"filename": "sp500.csv",
"columns": [
"Close",
"Volume"
],
"sequence_length": 50,
"train_test_split": 0.85,
"normalise": true
},
"training": {
"epochs": 1,
"batch_size": 32
},
"model": {
"loss": "mse",
"optimizer": "adam",
"layers": [
{
"type": "lstm",
"neurons": 100,
"input_timesteps": 49,
"input_dim": 2,
"return_seq": true
},
{
"type": "dropout",
"rate": 0.2
},
{
"type": "lstm",
"neurons": 100,
"return_seq": true
},
{
"type": "lstm",
"neurons": 100,
"return_seq": false
},
{
"type": "dropout",
"rate": 0.2
},
{
"type": "dense",
"neurons": 1,
"activation": "linear"
}
]
}
}

我们可以看到,随着第二个“交易量”维度与“关闭”一起添加,输出预测变得更加精细。预测器趋势线似乎具有更高的准确性来预测即将到来的轻微下跌,不仅从一开始就是主流趋势,而且趋势线的准确性在这种特殊情况下似乎也有所改善。
总结
虽然本文旨在给出LSTM深度神经网络在实践中的工作示例,但它只是触及了它们在顺序和时间问题中的潜力和应用的表面。
在撰写本文时,LSTM已成功用于许多现实世界的问题,从此处描述的经典时间序列问题,到文本自动更正,异常检测和欺诈检测,再到正在开发的自动驾驶汽车技术的核心。
目前,使用上述的普通LSTM存在一些限制,特别是在使用金融时间序列时,序列本身具有非常难以建模的非平稳属性(尽管在使用贝叶斯深度神经网络方法处理时间序列的非平稳性方面取得了进展)。此外,对于一些应用,还发现神经网络基于注意力的机制的新进展已经超过了LSTM(LSTM与这些基于注意力的机制相结合,本身的表现也优于它们)。
然而,截至目前,LSTM在更经典的统计时间序列方法上取得了重大进展,能够对关系进行非线性建模,并能够以非线性方式处理具有多个维度的数据。 我们开发的框架的完整源代码可以在GNU通用公共许可证(GPLv3)下找到,在以下GitHub页面上(我们要求信用明确归属为“Jakob Aungiers,Altum Intelligence ltd”,无论该代码在哪里被重用):https://github.com/jaungiers/LSTM-Neural-Network-for-Time-Series-Prediction
本文翻译自https://www.altumintelligence.com/articles/a/Time-Series-Prediction-Using-LSTM-Deep-Neural-Networks

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)