大数据平台架构包含哪些功能
大数据技术的核心是众多数据中挖掘价值,第一步需要做的就是弄清楚有什么样的数据、如何获取数据。在企业运行的过程中,特别是互联网企业,会产生各种各样的数据,如果企业不能正确获取数据或没有获取数据的能力,就无法挖掘出数据中的价值,浪费了宝贵的数据资源。Web 网站的很多数据来自用户的点击,可以使用低侵入的浏览器探针技术采集用户浏览数据、使用爬虫技术获取网页数据、使用组件Canal采集MySQL数据库的b
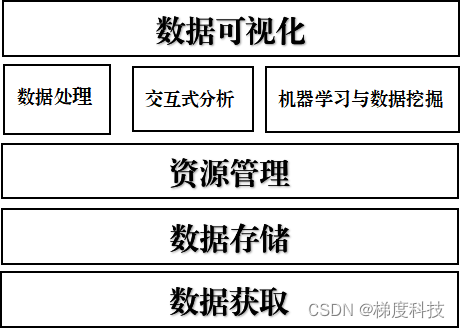
为了满足企业对于数据的各种需求,需要基于大数据技术构建大数据平台。结合大数据在企业的实际应用场景,如下图所示的大数据平台架构所示:

最上层为应用提供数据服务与可视化,解决企业实际问题。第2层是大数据处理核心,包含数据离线处理和实时处理、数据交互式分析以及机器学习与数据挖掘。第3 层是资源管理,为了支撑数据的处理,需要统一的资源管理与调度。第4层是数据存储,存储是大数据的根基,大数据处理框架都构建在存储的基础之上。第5层是数据获取,无论是数据存储还是数据处理,前提都是快速、高效地获取数据。
一、数据获取
大数据技术的核心是众多数据中挖掘价值,第一步需要做的就是弄清楚有什么样的数据、如何获取数据。在企业运行的过程中,特别是互联网企业,会产生各种各样的数据,如果企业不能正确获取数据或没有获取数据的能力,就无法挖掘出数据中的价值,浪费了宝贵的数据资源。数据从总体上可以分为结构化数据和非结构化数据。数据的来源不同、格式不同,获取数据所使用的技术也不同。Web 网站的很多数据来自用户的点击,可以使用低侵入的浏览器探针技术采集用户浏览数据、使用爬虫技术获取网页数据、使用组件Canal采集MySQL数据库的binlog日志,以及使用组件Flume采集Web服务器的日志数据。数据获取之后,为了方便不同应用消费数据,可以将数据存入Kafka消息中间件。
二、数据存储
存储是所有大数据技术组件的基础,存储的发展远远低于 CPU 和内存的发展,虽然硬盘存储容量多年来在不断地提升,但是硬盘的访问速度却没有与时俱进。所以对于大数据开发人员来说,对大数据平台的调优很多情况下主要集中在对磁盘I/O的调优。
三、数据处理
有了数据采集和数据存储系统,可以对数据进行处理。对于大数据处理按照执行时间的跨度可以分为∶离线处理和实时处理。
●离线处理,批量处理,用于时长跨越大、处理复杂数据。
●实时处理,流处理,用于处理实时数据流,通常数据处理的时间跨度在数百毫秒到数秒之间。
四、交互式分析
在实际应用中,经常需要对离线或实时处理后的历史数据,根据不同的条件进行多维分析查询并及时返回结果,这时就需要交互式分析。交互式分析是在历史数据上查询,因为是查询应用,所以交互式查询通常具有以下特点:
● 低延时
● 查询条件复杂
● 返回结果数据量小
● 查询范围大
● 并发数要求高
● 需要支持SQL等接口
五、机器学习与数据挖掘
在利用大数据技术对海量数据进行分析的过程中,常规的数据分析可以使用离线分析、实时分析和交互式分析,复杂的数据分析需要利用数据挖掘和机器学习的方法。
目前,使用较多、比较成熟的机器学习库是Spark框架中的Spark ML,大数据开发人员可以直接利用Spark ML 进行数据挖掘。当然也可以使用Flink框架中的Flink ML,不过Flink ML还在发展过程中,有待成熟和完善。
六、资源管理
资源管理的本质是集群、数据中心级别资源的统一管理和分配。首要解决的是多租户、弹性伸缩、动态分配等问题。
为了应对数据处理的各种应用场景,出现了很多大数据处理框架(如 MapReduce、Hive、Spark、Flink、JStorm等),相应地,也存在着多种应用程序与服务(如离线作业、实时作业等)。为了避免服务和服务之间、任务和任务之间的相互干扰,传统的做法是为每种类型的作业或服务搭建一个单独的集群。在这种情况下,由于每种类型作业使用的资源量不同,有些集群的利用率不高,而有些集群则满负荷运行、资源紧张。
为了提高集群资源利用率、解决资源共享问题,YARN在这种应用场景下应运而生。YARN资源管理系统对集群中的资源进行管理和调度。在实际企业应用中,一般都会将各种大数据处理框架部署到YARN集群上,方便资源的统一调度与管理。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)