什么是VAE与VQ-VAE
VQ-VAE就是使用encoder将图像编码,然后使用decoder将图像解码,其中encoder和decoder共享一个code book,编码器将图像x编码成E(x),之后这个向量根据它和标准的向量之间的距离进行量化,然后就是讲E(x)转化成距离它最近的标准编码,并且将这种标准编码给decoder 训练VQ-VAE编码器解码器生成图像一个VAE模型包括三个部分:后验分布(Posterior),
paper:https://arxiv.org/abs/1312.6114
VAE模型是Kingma(也是Adam的作者)大神在2014年发表的文章,是一篇非常非常经典,且实现非常优雅的生成模型,同时它还为bayes概率图模型难以求解的问题提供了一种有效的思路。论文原名为Auto-Encoding Variational Bayes,是一种通用的利用auto-encoding方法结合variational lower bound求解bayes图模型隐变量的方法论。而VAE(Variational Auto-Encoding)是在该方法论下的一个具体示例。
在推断和学习中,我们可以认为数据是根据某个隐变量生成的 — 可以从数据得到隐变量,也能够根据隐变量得到数据 — 就像一个编码、解码的过程。但是,通常隐变量的分布是未知的、复杂的,难以通过假定一个已知的分布来近似隐变量的真实分布。
简单谈一下个人对隐变量的理解:宽泛的讲,隐变量就像现实背后的某种神秘的、未知的因素,我们所见的现实背后蕴含着这种神秘的因素 — 隐变量,但我们通常是看不到隐变量的,也无法对它进行直接的观测,比如直接描述它是什么、它的形式、它发生的概率等等。但当我们得知隐变量后我们就像获得了某种神奇的力量,知道隐变量发生后现实中会发生什么。从数据的角度来看,隐变量可以是数据背后的“真理” — 特征、数据产生的原因。当我们能够描述隐变量后,我们就能够根据隐变量生成我们想要的数据。这就像一个编码-解码的过程,将原始数据编码为特征,再根据特征产生数据。
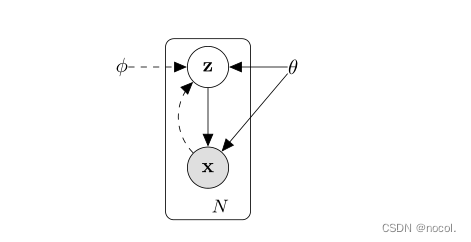
变分自动编码器(AEV)就是用于生成模型,结合了深度模型以及静态推理。简单来说就是通过映射学习将一个高位数据,例如一幅图片映射到低维空间Z。与标准自动编码器不同的是,X和Z是随机变量。所以可以这么理解,尝试从P(X|Z)中去采样出x,所以利用这个可以生成人脸,数字以及语句的生成。

上图直接明了的介绍了AEV,有朋友能直接看懂吗?假设我们有一堆图片X,图片分为很多类,那么Z就是决定X属性的神秘原因(内在因素),专业术语为隐藏因素。也就是说只要得到了Z,我们就可以获知X的相关属性。
那么怎么得到Z呢?开始推导,如果我们知道了z关于x的后验概率,那么已知x的分布,关于z的部分就很容易可以通过相应的公式获得。
但是这个p(z|x)后验概率本身是不好求的。所以聪明的人们就想说使用深度网络来推导q(z|x)来逼近p(z|x),通过·深度网络来来学习参数,一步步优化q这个逼近概率。通过这个方法我们就可以获得z的近似分布,从而把z给找出来。
为了使得q和p这两个之间的距离尽可能的小,作者还特地引入了KL散度,也许有朋友不了解什么叫KL散度,简单来说他就是衡量两个分布之间的距离,值越小两者越相近,值越大两者差距越大。首先假设对x的分布概率P(x)进行推导:
什么是VQ-VAE
VQ-VAE就是使用encoder将图像编码,然后使用decoder将图像解码,其中encoder和decoder共享一个code book,编码器将图像x编码成E(x),之后这个向量根据它和标准的向量之间的距离进行量化,然后就是讲E(x)转化成距离它最近的标准编码,并且将这种标准编码给decoder 训练VQ-VAE编码器解码器

生成图像

一个VAE模型包括三个部分:后验分布(Posterior),先验分布(Prior),以及似然(Likelihood)。其中后验分布用encoder网络来学习,似然用decoder网络来学习,而先验分布采用参数固定的标准正态分布。在VAE学习过程中,后验分布往往假定是一个对角方差的多元正态分布,而隐变量是一个连续的随机变量。

VQ-VAE与VAE的最主要的区别是VQ-VAE采用离散隐变量,如下图所示,对于encoder的输出通过向量量化(vector quantisation,VQ)的方法来离散化。至于为啥采用离散编码,论文的slides给出了三个主要原因:
-
许多重要的事物都是离散的,如语言;
-
更容易对先验建模,VQ-VAE采用PixelCNN来学习先验,离散编码只需要简单地采用softmax多分类;
-
连续的表征往往被encoder/decoder内在地离散化;

VQ-VAE-2算法思想
VQ-VAE-2是DeepMind团队于2019年提出的VQ-VAE的升级版,相比VQ-VAE,VQ-VAE-2采用多尺度的层级结构,如下图所示,这里采用了两个尺度的特征来进行量化。采用多尺度的好处是可以用将图像的局部特征和全局特征来分别建模,比如这里的Bottom Level的特征用于提取局部信息,而Top Level的特征用于提出全局信息。而且采用层级结构将可以用来生成尺寸较大的图像。

对于一张大小为256x256的图像,首先通过一系列卷积得到下采样1/4的中间特征,其大小为64x64,这个称为Bottom Level特征,然后进一步下采样1/2得到大小为32x32的特征,称为Top Level特征,这里对其量化得到Top Level特征对应的embeddings,将其和Bottom Level特征融合后得到增强的Bottom Level特征,然后进行量化;最后将Top Level和Bottom Level特征对应的embedding送入decoder来重建图像
同样地,VQ-VAE-2也采用PixelCNN来对先验建模,只不过这里也需要训练两个PixelCNN:分别用于生成Top Level和Bottom Level特征对应的离散编码。要注意的是第2个PixelCNN其实是一个建立在Top Level基础上的CondPixelCNN。 这里是以两个尺度的特征为例,其实也可以采用更多尺度的特征,即采用更多的层级。下图为采用3个层级的VQ-VAE-2模型的重建效果,可以看到,逐渐融合多个尺度的特征后,生成图像的细节越来越丰富。


开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐


 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)