深度学习之RNN,LSTM,GRU,CNN-GRU,ABLSTM(pytorch实现)
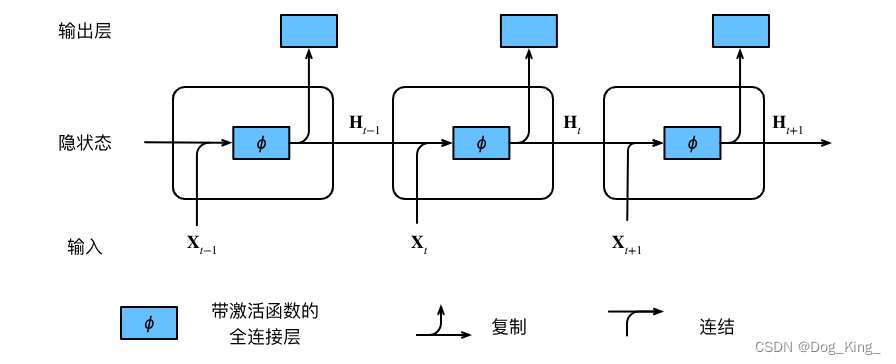
RNN模型最重要的贡献就是引入了隐藏层,隐状态存储的都是前一些时刻的相关特征信息,也是隐状态让模型有了记忆的能力。计算公式就类似于线性层。t时刻的H是由t-1时刻的H(也就是记忆的之前的信息),加上Xt(当前时刻的特征)GRU模型和前面的RNN模型很像,包括输入特征、隐藏态、输出。但是又有了改进,主要改进了隐藏态H的计算方法,通过门控制隐状态。这里引进了门,就是数电那种逻辑电路。这里引入了重置门和
前言
本文介绍了,循环神经网络(RNN),长短期记忆网络(LSTM),门循环控制单元(GRU)。这里顺便说了一下GRU-CNN并行网络和ABLSTM(基于注意力机制的双向LSTM网络)
一、RNN循环神经网络
卷积神经网络(CNN)只是对一个图片,或者一个样本进行特征提取,完全没有考虑到时序信息,前几刻的信息和这一刻信息的关联性。RNN模型的提出就解决了这个问题。
1.RNN模型介绍
RNN模型最重要的贡献就是引入了隐藏层,隐状态存储的都是前一些时刻的相关特征信息,也是隐状态让模型有了记忆的能力。计算公式就类似于线性层。

t时刻的H是由t-1时刻的H(也就是记忆的之前的信息),加上Xt(当前时刻的特征)


2.RNN模型pytorch代码实现
一个简单的rnn模型用pytorch实现起来很简单,主要是用nn.RNN加一个nn.Linear方法就可以实现。
这里需要注意的是RNN的几个常用的参数:
self.rnn = nn.RNN(input_size=self.num_input,hidden_size=self.num_hiddens,num_layers=self.num_layers,bidirectional=False,batch_first=True)
首先我们一般输入训练数据的特征X一般的维度特征是3个维度(batch_size,num_steps,input_features)
input_size : 也就是指的input_features,特征的维度。
hidden_size :隐藏层的神经元h的个数
num_layers: 隐藏层的层数(默认每个隐藏层里的神经元个数全都是hidden_size)
nonlinearity:激活函数
dropout:是否应用dropout, 默认不使用,如若使用将其设置成一个0-1的数字即可
batch_first:我们一般的数据传入都是(batch_size,num_steps,input_features),也即是batch在第0维度,最前面,如果想这样直接扔进去进行RNN运算,batch_first需要设置为True,但是batch_first默认为False,需要我们利用permute函数,x=x.permute(1,0,2)把num_steps放在前面。
bidirectional:从前面的图片也可以看出,我们的RNN是单向,只能提取之前的信息,如果想提取双向的信息,这里需要把bidirectional设置为True。
说完了输入参数,在说一下输出。nn.RNN()的输出是一个元组(output, h_n),其中output是所有批次,每一个时间步的最后一层隐状态,h_n是所有批次最后一个时间步所有隐藏态。h_n是最后一个时间步的输出。当batch_first设置为True时,output的形状为(batch_size, seq_length, hidden_size),但是h_n的形状不会因为batch_first而改变为( num_layers * num_directions,batch_size, hidden_size)。
这两个信息,我们一般选择其一就可以提取需要的信息,经过线性层分类。
注意:代码中的倒数第二行out = self.fc(out.reshape(-1,out.shape[-1])) ,这里把out reshape 成(batch_size *num_steps,num_hiddens) ,这里的是每个以时间戳的特征x对应一个output,通过nn.Linear方法,输出最后变成(batch_size *num_steps,output_size)。
但是有时可能多个时间戳,才对应一个输出。(比如我最近在学习利用WIFI信号识别人体的动作,一个时间戳的信号肯定不可以对应一个输出,需要上百个时间戳才对应一个动作。)比如250个时间戳对应一个输出结果,我们只需要提取第250个时间戳里的最后一个对应的out,他包含之前全部时间戳的特征信息。
out= self.fc(out[:,-1,:]) #这里进行切片,对这个批次里的每个每组seq只提取最后一个时间步
class rnn_model(nn.Module): #这里来具体的实现RNN类
def __init__(self,voacb_size,num_hiddens,num_layers,**kwargs):
super(rnn_model,self).__init__(**kwargs)
self.num_input = voacb_size
self.num_output = voacb_size
self.num_hiddens = num_hiddens
self.num_layers = num_layers
#这里注意batch_first 就是维度放在第一维的是batch_size ,这样的设置在forward里就不要变换维度了
#但是需要注意batch_first = True 这个对隐藏态和细胞状态h和c的形状没有影响,其batch_size 都在第二维上
self.rnn = nn.RNN(input_size=self.num_input,hidden_size=self.num_hiddens,num_layers=self.num_layers,bidirectional=False,batch_first=True) #LSTM需要的参数,这里规定了输入的大小和规模
self.fc = nn.Linear(self.num_hiddens,self.num_output) #全连接层输出类别判断
def forward(self,X):
#需要注意下面的 out 是 h[-1]即为隐藏层的 整个序列的最后一层隐藏态
out,_ = self.rnn(X) #这里模型会自动给h0初始化zero,这里返回了out,这里的out时每一个元素对应的隐藏态的最后一层,而占位符对应的是最后的隐藏态这里的形状是(batch_sizes,num_layers×hidden_size)
#out,_ = self.lstm(X)
#out的形状是 batch_size *num _steps *num_hiddens
out = self.fc(out.reshape(-1,out.shape[-1])) #括号里面的形状变成,(batch_size *num_steps,num_hiddens)
return out
2.RNN模型一些问题
1.RNN模型容易发生梯度爆炸或者梯度消失,所有的数据公用Whx,这才进行反向传播计算梯度,会进行指数计算,导致梯度过大或者过小,导致模型训练效果不好。
为了应对这个问题,可以进行梯度裁剪。
梯度裁剪很容易理解
这里面的𝜃是给定的参数半径,下面的保证梯度的g不超过这𝜃,也就是把控制||g||<=𝜃

这个梯度裁剪用pytorch实现起来也很简单。
只需要每次l.backward()计算梯度后,使用nn.utils.clip_grad_norm_()方法,需要传入两个参数,一个是net的参数,一个是𝜃。
import torch
import torch.nn as nn
import torch.optim as optim
# 定义RNN模型
# 训练模型
num_epochs = 100
for epoch in range(num_epochs):
# 前向传播
outputs = model(x_train)
loss = criterion(outputs, y_train)
# 反向传播和梯度裁剪
optimizer.zero_grad()
loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), clip) # 梯度裁剪
optimizer.step()
# 打印训练信息
if (epoch+1) % 10 == 0:
print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item()))
# 预测
x_test = torch.tensor([[10, 11, 12]], dtype=torch.float32).unsqueeze(0)
y_pred = model(x_test)
print('Predicted value:', y_pred.item())
2.RNN模型的计算效率较低。由于RNN模型中的每个时间步都需要进行计算,使得模型的前向传播速度较慢。
3.RNN模型难以捕捉长期依赖关系。当序列长度较长时,RNN模型的记忆能力会逐渐减弱,导致难以建模长期依赖关系。
二、GRU门循环控制单元
GRU(Gate Recurrent Unit)是循环神经网络(RNN)的一种,可以解决RNN中不能长期记忆和反向传播中的梯度等问题,虽然比LSTM诞生的晚,但是相对简单。而且模型如其名。
1.GRU模型介绍
GRU模型和前面的RNN模型很像,包括输入特征、隐藏态、输出。但是又有了改进,主要改进了隐藏态H的计算方法,通过门控制隐状态。这里引进了门,就是数电那种逻辑电路。
这里引入了重置门和更新门,都是根据上一个时刻的隐藏态和t时刻的特征X计算得出。


GRU还引入了候选隐状态。可以从公式看出当Rt趋近于1时,就类似于前面说的RNN循环神经网络,当Rt趋近于0时候选隐状态的运算就想一层线性运算,整个网络也会想多层感知机靠近。


但是候选隐状态并不是最终的隐状态,每当更新门 𝐙𝑡 接近 1时,模型就倾向只保留旧状态。 此时,来自 𝐗𝑡的信息基本上被忽略, 从而有效地跳过了依赖链条中的时间步 𝑡 。 相反,当 𝐙𝑡接近 0 时, 新的隐状态 𝐇𝑡就会接近候选隐状态 𝐇̃ 𝑡。 这些设计可以帮助我们处理循环神经网络中的梯度消失问题, 并更好地捕获时间步距离很长的序列的依赖关系。 例如,如果整个子序列的所有时间步的更新门都接近于 1, 则无论序列的长度如何,在序列起始时间步的旧隐状态都将很容易保留并传递到序列结束。


可以看出
重置门有助于捕获序列中的短期依赖关系;
更新门有助于捕获序列中的长期依赖关系。
2.GRU模型pytorch实现
首先说一下nn.GRU()输入需要的参数和前面的RNN一模一样。
nn.GRU()的输出是一个元组(output, h_n)。如果batch_first为True,其中output是最后一个时间步的隐状态,h_n是最后一个时间步的输出。output的形状为(batch_size, seq_length, hidden_size),h_n的形状为(num_layers * num_directions, batch_size, hidden_size)。这里的num_directions是表示GRU模型是单向的还是双向的。
关于nn.GRU的输出,可以说和前面的RNN一模一样。nn.GRU()的输出是一个元组(output, h_n),其中output是最后一个时间步的隐状态,h_n是最后一个时间步的输出。output的形状为(batch_size, seq_length, hidden_size),h_n的形状为(num_layers * num_directions, batch_size,hidden_size)。
import torch
from torch import nn
gru_layer = nn.GRU(input_size=input_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True)
3.CNN-GRU串行网络
我们本篇介绍的RNN GRU LSTM都是处理序列关系、时间关系的时序模型。而CNN模型广泛应用于图像分类的特征提取领域。在某些预测问题中,单独使用CNN或时间学列模型可能无法充分挖掘数据的特征,因此我们需要将它们进行有效地融合。
CNN与循环网络可以连接成串行网络,也可以连接成并行网络。这里只介绍了和GRU的融合的网络,但是和其他序列的融合基本上是完全一样的,可以举一反三。
我们先说一下串行网络,其实很容易理解
数据集:这里用的CSI信号。可以简单理解input_size 250*90的数据,250代表时间戳,90代表一个时刻对应的特征,我们的目标是通过250个时间戳判断出人体的一种活动。
我们这里用一位卷积实现了一个self.encoder编码器,可以简单理解成encoder(CNN部分)进行了下采样,压缩了数据量,同时进行了特征提取。但是这里的时间通道维度并没有改变,我们可以直接把encoder输出的部分放入GRU模块提取时间特征。提取时间特征之后,把每个batch第250个时间戳对应的隐藏态的最后一层放入分类器,进行分类。
class CSI_serial_CNN_GRU(nn.Module):
def __init__(self):
super(UT_HAR_CNN_GRU,self).__init__()
self.encoder = nn.Sequential(
#input size: (250,90)
nn.Conv1d(250,250,12,3), #把时间戳当成通道,通道数始终不变,而每一个时刻的特征就是一维向量了,因此我们这里用了一位的卷积
nn.ReLU(True),
nn.Conv1d(250,250,5,2),
nn.ReLU(True),
nn.Conv1d(250,250,5,1)
# 250 x 8
)
self.gru = nn.GRU(8,128,num_layers=1)
self.classifier = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(128,7),
nn.Softmax(dim=1)
)
def forward(self,x):
# batch x 1 x 250 x 90
x = x.view(-1,250,90)
x = self.encoder(x)
# batch x 250 x 8
x = x.permute(1,0,2)
# 250 x batch x 8
_, ht = self.gru(x)
outputs = self.classifier(ht[-1])
return outputs
4.CNN-GRU并行网络
并向网络和串行网络有些区别,就像并联电路一样,CNN模块和GRU模块分别提取特征信息和,时序信息,两者提取出来不一样的特征,然后利用torch.cat(),将特征汇总,通过分类器实现分类。
我在阅读一篇论文时候,看到了一篇利用并行LSTM-CNN进行特征提取的论文。其框架大概如下。比如输入的CSI矩阵是250*90。250是250个时间戳,90是一个时间戳对应的特征。250个时间戳也就是一个CSI矩阵对应一个人体动作。
LSTM可以学习复杂的时间动态信息,而FCN可以通过提取动作在空间维度上的深层抽象特征来有效地预测动作。

接下来,我们简化一下这个模型,并把LSTM换成GRU来实现。这里我直接偷懒,用了上面的代码先卷积成(batch_size,num_steps,8)的形状,再利用nn.Flattern()展平成(batch_size,2000)的形状。其实这里也可以直接利用二维卷积,二维卷积后再展平。
最后通过代码x = torch.cat((x1,x2),dim=1) 把特征维度连接起来,变成了(batch_size,100+80)的形状。最后经过一个线性层变成(batch_size,7)与csi对应的7种动作分别对应。
我们在实现模型的时候一定要注意 形状 ,因为后面又torch.cat操作。
这里还需要注意batch_first设置为true, _,h = self.gru(X)这里h的形状需要转换维度。
import torch
from torch import nn
class Parallel_CNN_GRU(nn.Module):
def __init__(self):
super(Parallel_CNN_GRU,self).__init__()
#这里cnn输出的特征是 (batch_size,num_steps, 8) 、
# batch_size,num_steps还是250,然后这个特征数量从原来的90变成了提取后的8
self.cnn = nn.Sequential(
#input size: (250,90)
nn.Conv1d(250,250,12,3), #把时间戳当成通道,通道数始终不变,而每一个时刻的特征就是一维向量了,因此我们这里用了一位的卷积
nn.ReLU(True),
nn.Conv1d(250,250,5,2),
nn.ReLU(True),
nn.Conv1d(250,250,5,1),
# 250 x 8
nn.Dropout(0.5), #drop一下防止过拟合
nn.Flatten(), #直接展平了,形状变成(batch_size,)
nn.Linear(250*8,100)
)
self.gru = nn.GRU(input_size=90,hidden_size=80, num_layers= 2, batch_first = True, bidirectional = False)
self.fc = nn.Linear(180,7)
def forward(self,X):
# x1的形状是(batch_size, num_steps(250) ,fetures(8))
x1 = self.cnn(X)
#h是每一批第250个时间戳对应的隐藏层状态
#h的形状是(batch_size, num_layers(2) , hidden_size(80))
_,h = self.gru(X) #即便batch_first = True 这个形状仍然是(num_layers,batch,hiddens_size)
h = h.permute(1,0,2)
# x2的形状是(batch_size, 1 , hidden_size(80))
x2= h[:,-1,:] #提取最后一层即可
x2 = x2.squeeze(1) #形状变成(batch_size, 1 , hidden_size(80))
#print(x1.shape,x2.shape,h.shape)
x = torch.cat((x1,x2),dim=1) #把特征维度连接起来 (bacth,180)
output = self.fc(x)
return output
用这个模型跑了一下几千个CSI数据来识别人体活动。准确率还不错,好像有点过拟合,调一下模型,应该还有上涨的可能。

三、LSTM长短期记忆网络
LSTM(Long short term memory)模型比RNN、GRU模型复杂了很多,但是思路和GRU很类似。
1.LSTM模型介绍
其实RNN GRU LSTM的核心都是引入了隐藏态H,而这三者的区别就是H的生成方式不同,RNN是直接用上一刻的H和此刻的特征X,利用全连接的方法直接就简单的实现了。而GRU比RNN更复杂一些,引入了重置门R,通过这个重置门R生成候选隐状态,这个重置门R可以控制是否记忆足够多的过去内容,还是遗忘或者忘记。同时还引入了更新门Z,用来对候选隐状态和前一刻的隐状态操作,决定更新的比例大还是,保存之前的信息更重要。到底哪样重要我们也不知道,训练结果会给出答案。
LSTM引入了输入门、记忆门,遗忘门,候选记忆单元和记忆元之类。前三者的门和GRU的门的生成一样。
在门控循环单元中,有一种机制来控制输入和遗忘(或跳过)。 类似地,在长短期记忆网络中,也有两个门用于这样的目的: 输入门 𝐈𝑡控制采用多少来自 𝐂̃ 𝑡的新数据, 而遗忘门 𝐅𝑡控制保留多少过去的 记忆元 𝐂𝑡−1∈ℝ𝑛×ℎ的内容。 使用按元素乘法如果遗忘门始终为 1且输入门始终为 0, 则过去的记忆元 𝐂𝑡−1将随时间被保存并传递到当前时间步。 引入这种设计是为了缓解梯度消失问题, 并更好地捕获序列中的长距离依赖关系。还要注意H的生成时引入了激活函数,可以有效的保证,Ht的范围再(-1,+1).。





2.LSTM模型pytorch 代码示范
这里的数据集的例子和上面的CSI一样(batch_size,时间戳(250),特征(90)),250*90的CSI矩阵代表着一个动作。
而且需要注意的是这个模型的输出与前两个模型有微小的区别。输出是otput、(隐状态h_t,单元状态c_t),多了一个前面提到的c。
import torch
from torch import nn
class LSTM_Net(nn.Module):
def __init__(self,input_size,output_size,num_hiddens=64,num_layers = 1):
super(LSTM_Net, self).__init__()
self.num_hiddens = num_hiddens
self.num_layers = num_layers
#分析这里的数据250*90
self.lstm = nn.LSTM(input_size=input_size,hidden_size=self.num_hiddens,num_layers=self.num_layers,batch_first=True)
self.fc = nn.Linear(num_hiddens,output_size)
def forward(self,X):
#X的形状是 batch_size,num_steps,90
out,_ = self.lstm(X) #这里的out是隐藏层的最后一层(batch_size *num _steps *num_hiddens)
#out = out.reshape(-1,out.shape[-1]) nlp的预测就是这种一个对应一个输出 转化成 (batch_size*num_steps , num_hiddens)
#这里需要是是提取250个时间步里面的最后一个时间步的隐藏态,因为250个时间不才输出一次
output = self.fc(out[:,-1,:]) #这里进行切片,对这个批次里的每个每组seq只提取最后一个时间步
return output #这里输出的形状就是(batch_size,1,output_num)
3.ABLSTM(基于注意力机制的双向LSTM网络)
从简单的开始说,先说一下BiLSTM,和BiGRU,BiRNN很类似的,举一反三。
先说双向LSTM和单向LSTM的区别。单向循环网络都是只能获取之前的信息。但是有时候我们不只想获取前面的信息,比如NLP领域,一段话我们想要获取上下文的信息。有上文和下文,着必然对应着两份隐藏层,分别从前往后训练得出,和从后往前训练得出,如下图所示。其实就是多了一套参数,多了一套隐藏层,理解起来比较容易。
在使用pytorch时只需要将bidirectional设置为True即可实现。只不过需要注意下面代码的out的形状是(batch_size, num _steps, 2*num_hiddens),而单向LSTM(batch_size, num _steps, num_hiddens)。


代码如下(示例):
import torch
from torch import nn
class LSTM_Net(nn.Module):
def __init__(self,input_size,output_size,num_hiddens=64,num_layers = 1):
super(LSTM_Net, self).__init__()
self.num_hiddens = num_hiddens
self.num_layers = num_layers
#分析这里的数据250*90
self.lstm = nn.LSTM(input_size=input_size,hidden_size=self.num_hiddens,
num_layers=self.num_layers,batch_first=True, bidirectional=True) #这里bidirectional设置为True
self.fc = nn.Linear(num_hiddens,output_size)
def forward(self,X):
#X的形状是 batch_size,num_steps,90
out,_ = self.lstm(X) #这里的out是隐藏层的最后一层(batch_size, num _steps, 2*num_hiddens)
#这里需要是是提取250个时间步里面的最后一个时间步的隐藏态,因为250个时间不才输出一次
output = self.fc(out[:,-1,:]) #这里进行切片,对这个批次里的每个每组seq只提取最后一个时间步
return output #这里输出的形状就是(batch_size,1,output_num)
那么我们再进一步,如何再BLSTM的基础上引入注意力机制,ABLSTM是我在下面这篇论文里看到的也是处理CSI信号的来识别人体动作的。

一个x对应一个时间戳的CSI信号,一个h对应一个双向的隐藏态。接下啦我们要在下面图片的基础上引入注意力机制。

这里使用的是注意力机制,先计算注意力分数,

然后通过softmax函数计算注意力权重。

注意力权重乘对应时刻隐藏态,即为v值。

通过上面的公式可以看出,这里通过注意力机制,选取更为重要的ht。
整体的模型框架如下图所示:

代码如下:
import torch
from torch import nn
#ABLSTM模型
class ABLSTM(nn.Module):
def init(self,input_size,output_size,seq_lens,num_hiddens,num_layers,dqk,dv,num_heads = 1):
super(ABLSTM,self).init()
self.lstm = nn.LSTM(input_size=input_size,hidden_size=num_hiddens,bidirectional=True,num_layers=num_layers,batch_first=True) #这里的LSTM是双向的呢
#self.attention = nn.MultiheadAttention(embed_dim=dqk, kdim=dqk,vdim= dv, num_heads = num_heads,batch_first=True)
self.attention = nn.MultiheadAttention(embed_dim=input_size, num_heads = num_heads,batch_first=True)
self.flatten = nn.Flatten()
self.query = nn.Linear(2 * num_hiddens, input_size)
self.key = nn.Linear(2 * num_hiddens, input_size)
self.value = nn.Linear(2 * num_hiddens, input_size)
self.fc1 = nn.Linear(input_size,2*num_hiddens)
self.fc2 = nn.Linear(num_heads * seq_lens *num_hiddens * 2, 128)
self.fc3 = nn.Linear(128,output_size)
def forward(self,x):
out,_= self.lstm(x) #目的是提取出来所有的隐藏层 out 的形状(batch_size,seq_len,2 * num_hidden) 这里h的形状是(num_layers * 2,batch,hiddens_size)
#print(h.shape,out.shape)
q = self.query(out)
k = self.key(out)
v = self.value(out)
atten,_ = self.attention(q,k,v) #atten的形状是(batch_size, num_steps, 90)
x = self.fc1(atten) + out # 线性变换 + 残差连接
x = self.flatten(x) # 形状变成了(batch_size, num_heads * seq * 2*num_hiddens)
x = self.fc2(x)
x = torch.relu(x)
x = self.fc3(x)
return x
总结
本文主要讲解了RNN、GRU、LSTM等网络,并进行了适当的扩展。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐


 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)