一文彻底搞懂大模型 - 基准测试(Benchmark)
最近这一两周看到不少互联网公司都已经开始秋招提前批面试了。不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。LLM(Large Language Model,大型语言模型)中的Benchmark(基准测试)是用于衡量和比较不同LLM性能的一组经过精心设计的测
最近这一两周看到不少互联网公司都已经开始秋招提前批面试了。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
总结链接如下:
喜欢本文记得收藏、关注、点赞。
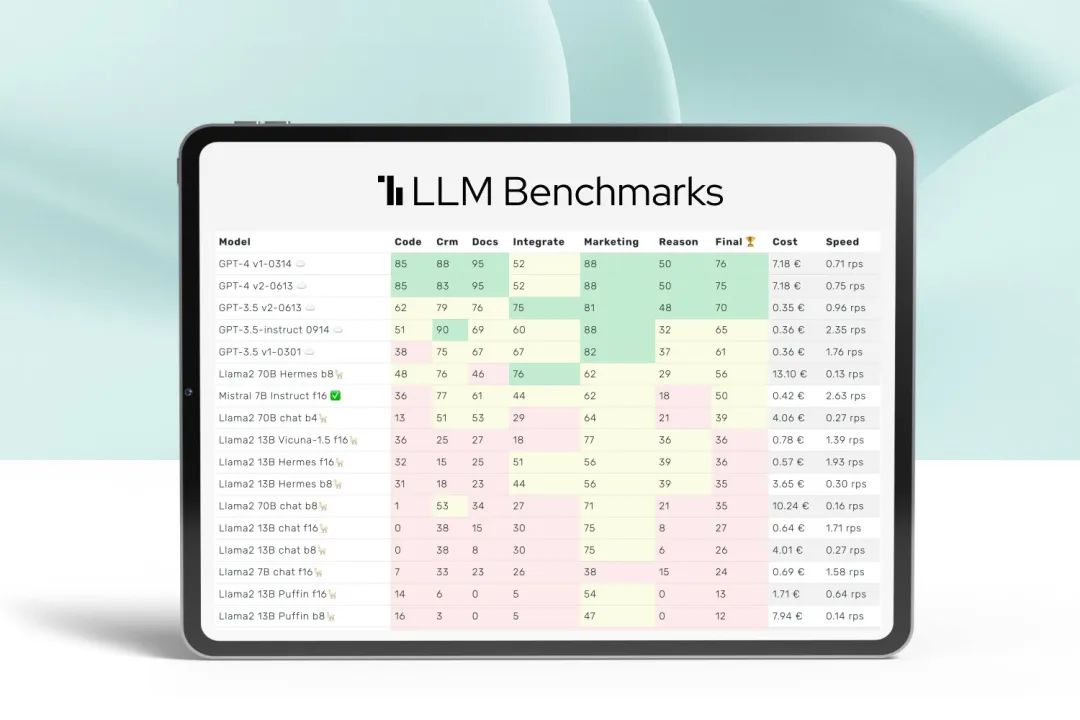
LLM(Large Language Model,大型语言模型)中的Benchmark(基准测试)是用于衡量和比较不同LLM性能的一组经过精心设计的测试任务、问题和数据集。这些基准测试遵循标准化的流程,以评估LLM在核心语言处理任务上的表现。
Benchmark
一、Benchmark
什么是基准测试(Benchmark)?评估AI系统或模型性能的一种标准化测试方法。它通过使用预定义的数据集、任务和评估指标,对AI模型在特定任务上的表现进行量化评估,以便比较不同模型之间的性能差异。
-
标准化评估:提供一套标准化的测试流程和评估指标,确保不同模型之间的比较具有公平性和一致性。
-
性能比较:帮助研究人员和开发者了解不同AI模型在同一任务上的性能差异,从而选择最适合的模型。
-
技术进步追踪:通过定期更新基准测试,追踪AI技术随时间的进步和发展。
Benchmark
基准测试(Benchmark)的核心要素是什么?使用公开认可的数据集,定义具体任务,并通过适当的评估指标全面评估AI模型在不同领域的性能。
-
数据集:使用公开、广泛认可的数据集,这些数据集通常包含多种类型的任务和场景,以全面评估AI模型的性能。
-
任务:定义一系列具体的任务,如文本分类、图像识别、语音识别等,以测试AI模型在不同领域的应用能力。
-
评估指标:选择适当的评估指标来衡量AI模型的性能,如准确率、召回率、F1值、延迟、能耗等。
Benchmark
二、NLP的_Benchmark
什么是NLP(自然语言处理)?NLP使用了统计学、机器学习、深度学习等多种技术,通过处理大量的文本数据和语言规则,从而提取出语义、情感、信息等。
NLP
NLP旨在使计算机能够识别、理解、解释和生成人类语言,从而实现与人类进行自然而智能的交互。
-
文本分类:将文本数据自动分类到预定义的类别中。
-
语义理解:理解文本的含义和上下文关系。
-
语言生成:根据输入生成自然语言文本。
-
机器翻译:将一种语言的文本自动翻译成另一种语言。
-
语音识别:将人类语音转换为文本。
-
问答系统:回答用户提出的问题。
NLP
自然语言处理(NLP)基准测试:如GLUE、SuperGLUE、SQuAD等,用于评估AI模型在自然语言理解方面的能力。
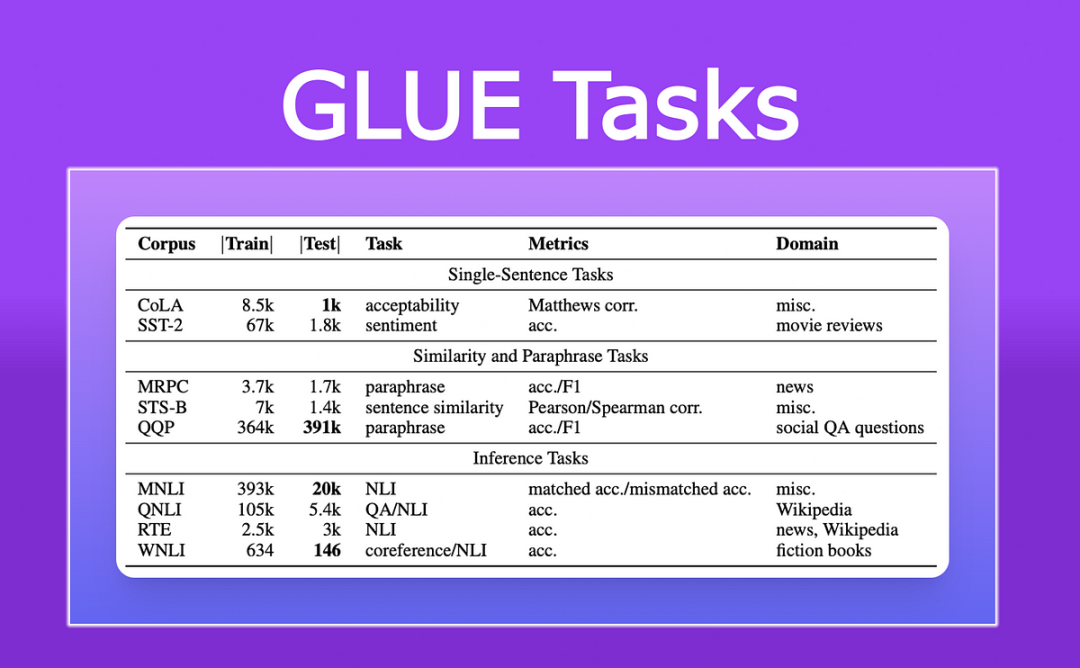
1. GLUE(General Language Understanding Evaluation)
GLUE是由纽约大学和斯坦福大学联合发起的自然语言理解基准测试平台,旨在推动研究者对广泛的任务进行深度学习模型的评估和比较。

GLUE
GLUE任务涵盖了词汇水平、句子水平和篇章级别的理解和推理。GLUE包含9个不同的自然语言理解任务,如句子对分类(MRPC)、情感分析(SST-2)、问答一致性评估(QNLI)、同义词替换检测(STS-B)等。
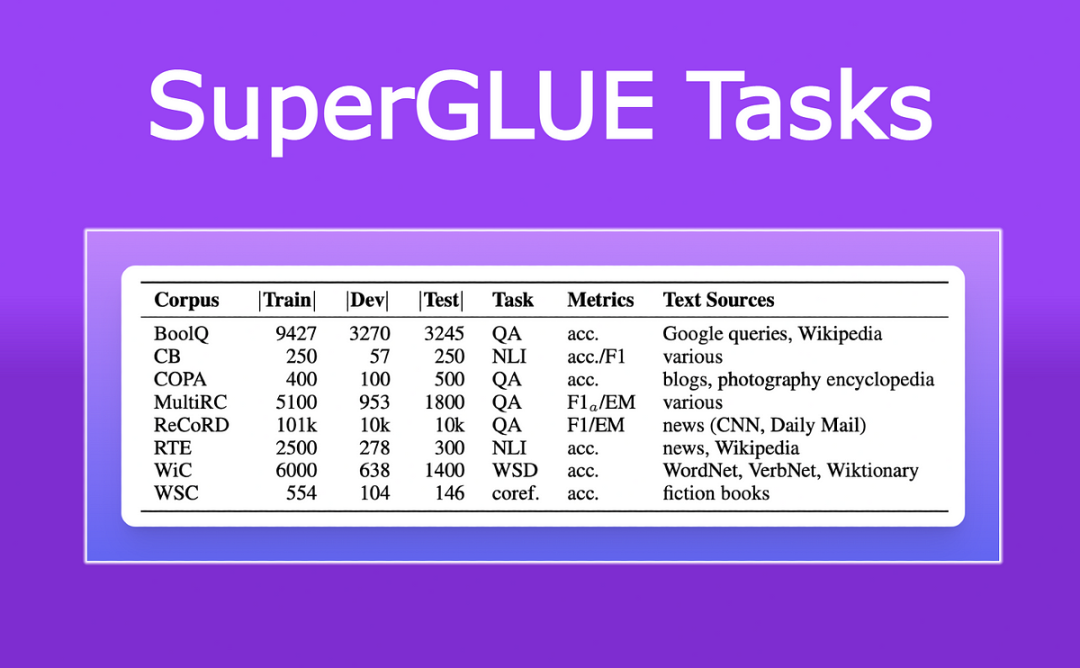
2. SuperGLUE(Super General Language Understanding Evaluation)
SuperGLUE是在GLUE基础上推出的一个更加全面和具有挑战性的评估平台,旨在推动NLP领域的发展。它由纽约大学、华盛顿大学、DeepSeek、艾伦人工智能研究所和Facebook AI Research共同开发。

SuperGLUE包含了一系列新的更困难的语言理解任务,如BoolQ(基于阅读理解的是非题)、CommitmentBank(判断句子与段落信息的一致性)、MultiRC(多选题阅读理解)等。这些任务涵盖了语言理解的不同方面,包括阅读理解、常识推理、代词消歧等。
3. SQuAD(Stanford Question Answering Dataset)
SQuAD是斯坦福大学于2016年推出的一个阅读理解数据集,用于评估算法从文章中找出问题答案的能力。
-
大规模:数据集包含107,785个问题以及配套的536篇文章,所有文章均选自维基百科。
-
广泛应用:由于其数据量和质量的优势,SQuAD已成为评估阅读理解模型性能的重要基准之一。

SQuAD广泛应用于各种NLP任务中,特别是阅读理解任务。通过在该数据集上的表现,可以评估模型在理解文本、提取关键信息以及生成答案等方面的能力。
三、CV的_Benchmark
什么是CV(计算机视觉)?计算机视觉(Computer Vision, CV)是指计算机利用摄像机、图像传感器等设备获取图像或视频,并通过复杂的算法对这些图像或视频进行处理和分析,以实现对图像或视频中的物体、场景以及其属性的理解和识别的技术领域。
-
图像处理:对图像进行预处理、增强、恢复、变换等操作,以提高图像的质量和可用性。
-
目标检测与识别:能够识别和分类图像中的物体、场景或者特定的图案。例如,面部识别、物体识别等。
-
视频分析:对视频进行分析和处理,包括视频监控、运动检测、人脸识别等。

计算机视觉(CV)基准测试:如ImageNet、COCO等,用于评估AI模型在图像分类、目标检测等任务上的性能。
1. ImageNet
ImageNet是一个由斯坦福大学李飞飞等人创建的大规模图像数据库,它包含了超过1400万张样例图片,这些图片被分为27个大类和超过2万个小类。ImageNet因其庞大的规模和丰富的类别而成为计算机视觉领域的重要资源。
-
计算机视觉研究和开发:ImageNet提供了一个大规模的图像数据库,可用于训练和评估图像分类、目标检测和图像识别等计算机视觉任务的算法和模型。
-
模型性能评估:作为一个广泛使用的基准测试数据集,ImageNet可用于评估不同模型在图像分类任务上的性能。通过在ImageNet上进行比较,可以更准确地评估和比较不同模型之间的优劣,并推动模型的改进和发展。
-
深度学习教育:ImageNet的广泛使用也使得它成为深度学习教育中重要的资源之一。许多教育机构和在线课程使用ImageNet作为实践项目,帮助学生理解和应用深度学习算法,并培养他们在计算机视觉领域的技能。

2. COCO(Microsoft Common Objects in Context)
COCO数据集是一个大型的、丰富的物体检测、分割和字幕数据集。它由微软于2014年出资标注,旨在推动计算机视觉领域在复杂场景下的理解和分析能力。COCO数据集包含超过33万张图片,其中超过20万张图片有详细的标注信息,涵盖了91类目标。
-
目标检测和图像分割:COCO数据集主要用于评估目标检测和图像分割等任务的性能。它提供了丰富的标注信息,包括目标的边界框、分割掩码等,使得研究人员能够更准确地评估模型在这些任务上的表现。
-
评估标准IOU指标:目标检测和图像分割的评估标准主要基于IOU(Intersection over Union)指标。IOU表示预测框或分割掩码与真实框或掩码之间的重叠程度,是评估模型性能的重要指标之一。


开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐


 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)