基于NoC的多处理器系统; NoC的基本结构和原理;Router;网络接口;流量控制机制;高速缓存一致性;Network on chip 片上网络; Multi-Processor System
基于NoC的多处理器系统是一种使用网络互连的架构,将多核CPU、GPU、FPGA等处理器和加速器通过高带宽、低延迟的通信通道连接起来,实现高性能、可扩展的并行计算。它提供了灵活性、节能性和可靠性,适用于高性能计算、嵌入式系统等领域,加速图形处理、人工智能和机器学习等任务。
基于NoC的多处理器系统
基于NoC的多处理器系统是一种使用网络互连的架构,将多核CPU、GPU、FPGA等处理器和加速器通过高带宽、低延迟的通信通道连接起来,实现高性能、可扩展的并行计算。它提供了灵活性、节能性和可靠性,适用于高性能计算、嵌入式系统等领域,加速图形处理、人工智能和机器学习等任务。
NoC-based MPSoCs(Network on chip; Multi-Processor System on Chip )设计面临的一个主要挑战是确保所有节点之间的通信效率和一致性,包括实现有效的 缓存一致性协议和 流量控制策略。
0. 前言:片上网络NoC区别于Bus总线结构

- 总线(Bus)结构:总线结构是最基础的连接方式,其中所有设备都连接到同一条总线上,数据传输需要在总线上进行,所有设备共享这条总线。这种结构简单且成本低,但当连接的设备数量增加时,性能会下降,因为所有的设备必须共享有限的总线带宽。
- 共享总线(Shared Bus)结构:在共享总线结构中,所有的处理器或核心都连接到同一条总线上。这意味着任何时候只有一个处理器可以使用总线。这种设计在低核心数量的系统中可能是有效的,但是在高并发的环境中会成为瓶颈,因为所有的处理器必须等待总线空闲才能发送数据。
- 矩阵连接(Matrix Connect)结构:在矩阵连接结构中,每个处理器都有一个专用的连接到每个其他处理器的路径。这使得在任何时候都可以有多个并行的通信,从而提供了更高的带宽和更低的延迟。然而,这种架构的缺点是需要大量的物理连接,这会增加设计的复杂性和成本。
- NoC(Network-on-Chip)结构:NoC设计为处理大规模和复杂的通信需求,例如在多核处理器和复杂的系统级集成(SoC)设计中。NoC使用标准的网络协议和技术(例如路由和分包)来管理在芯片上的数据流。NoC可以支持大量的并行通信,并提供比其他方法更高的带宽。然而,NoC的设计和实现比其他方法更复杂,可能需要更多的硬件资源。
1. NoC
1.1 NoC的概述
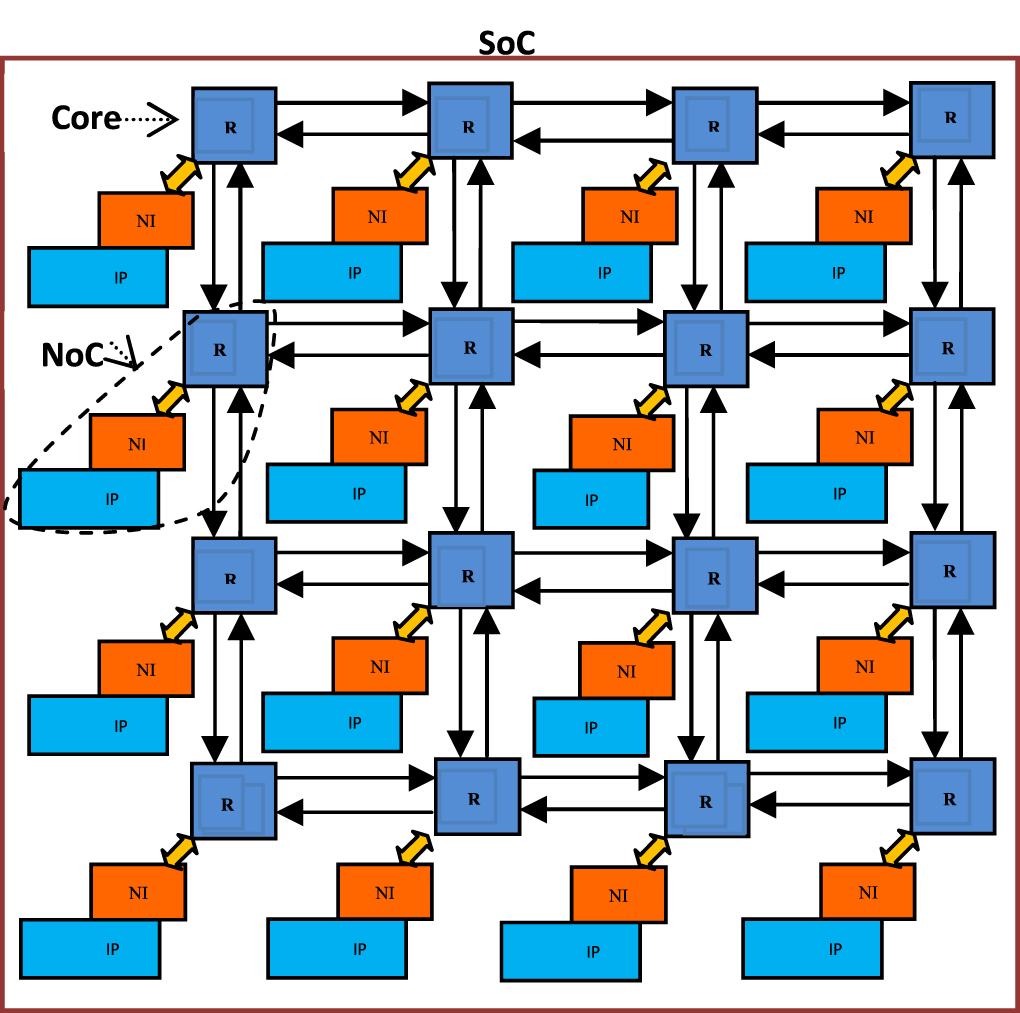
如图所示是一个基于NoC(Network on Chip)的MPSoCs(multiprocessor systems-on-chip),一共具有16个SoC(System on Chip)(可以是CPU、GPU、NPU、纯内存或其他功能SoC),每个SoC工作在 IP(intellectual property ) 上,NoC的运行基于路由器Router(R)以一定拓扑结构(Topology)的互相连接进行消息的传递,IP和Router间由NI(Network Interface)将IP中的数据抽象成通用的网络通信协议,以数据包的形式在共享相同的线路传递数据包。

- Links:是物理连接节点并实现通信的链路。
- Routers:路由器,实现通信协议。
- Network Interface:网络接口 (NI)在 IP 核和网络之间建立逻辑连接。
- Tile:包括Router、NI、IP。是指构成系统的基本处理和通信元素的基本构建块或单元,Tile它可以被视为单个处理元素 (PE) 或处理核心及其相关资源。
- NI:网络接口(Network Interface)将cache messages(控制或数据)转换为packets。
Design Environment for the Support of Configurable Network Interfaces in NoC-based Platforms
1.2 拓扑结构

NoC里Router之间的link链路连接可以定义成不同的结构以改变通信测量和简化片上通信结构。
-
(a)Ring:环形,每个router都有2个相邻节点,虽然部署和故障排除相对容易,但主要缺点是其通信的距离也即环形的直径会增大,通信路径单一不能优化,扩展节点数量时会降低系统性能。另一个缺点是,当一个节点出现错误时会使得通信之间出错(容易受到攻击)。
-
(b)Octagon :八角形,除了8个节点连接到环路上以外,对角线上共4对节点两两相连,比环形的扩展性更强。
-
(c)Star:星形,在星形结构的中间有一个中心节点,它连接着周围所有的节点,这样的星形结构使得所有节点互相传递消息的距离为2(先传给中心节点,再传给星角上的另一个)。星角上的节点是分离的,所以星角上节点故障时可以改进不会影响其他节点。缺点是有着通信的瓶颈,且中心节点出错时会影响全局通信。
-
(d)Mesh:网状,是最广泛使用的互联拓扑结构,每个路由器都通过通信通道连接到一个计算资源和四个相邻路由器(分别是North,south,west,east),每个router都通过通信通道连接到一个PE和四个相邻routers。这种拓扑结构可以容忍某处的链路故障,而且可以根据传递消息的布线策略选择路径最短的路径传播消息。但它的直径随着节点数量的增加而显着增加。
-
(e)Torus:环面拓扑,解决了网状拓扑直径随网络规模增加的挑战。这是通过在同一列或行中的端节点之间添加直接连接来实现,从头到尾减少了一半的跳转数。然而,它的长环绕链接可能会导致不当延迟。
-
(f)Folded torus:折叠环面拓扑,相比环面,他的四个均匀分布在一个环上,并不是直接将首尾相连。从而提供更短的链路长度,从而减少互连链路之间数据包的实施面积和遍历时间。与环面相比,折叠环面提供了更多的路径多样性,使其更具容错性。
-
(g)Butterfly:蝴蝶拓扑,把所有节点分到两边,中间加一层过渡节点,负责通路上通信的开关,成本比较低。但有的节点可能只有唯一路径,故缺乏路径多样性,导致链路容错性低,带宽低。通常需要很长的电线,相关的复杂电线布局会导致更多的能源消耗
-
(h)Binary Tree Network:二叉树形,由顶部(根)节点和底部(叶)节点组成,随着树长度的增加,网络配置变得更加复杂。而且如果父节点出错会导致之后所有子节点都出错。
-
(i)胖树拓扑:基于使用中间路由器作为转发路由器并将离开路由器连接到子节点,虽然这种拓扑结构提供了出色的路径多样性和更好的带宽,但路由器与客户端的比率非常高,布线布局也很复杂。
-
特殊的结构:比如立体的四边形结构,降低关联节点度和/或最小化网络直径,同时保持尽可能小的直径。其他自定义的结构,基于聚类的概念并适用于特定应用程序进行优化集群通信的优化。
Network-on-Chip Topologies: Potentials, Technical Challenges, Recent Advances and Research Direction
Implementation of 4×4 2D Mesh NoC Architecture using FPGA
1.3 数据包packets格式:message -> packets -> flit -> phits
message是一组连续的比特流,想从源router传送到目的地router。将一个message分为若干packets,每个packets是routing路由和sequencing排序的基本单位。packet分为具有固定格式的flit组,包含header、body、tail。

- message:从程序员的角度来看,message是一个信息单元,通信的目的是要完整传递这个message。 大小仅受用户内存空间的限制。
- packet:是最小的通信单元,控制状态被分配给一个数据包。包含路由信息(例如,目标地址)和其标头中的排序信息。 它的大小是数百或数千字节或单词的数量级。 它由header flit和data flit迁移组成。数据包可能被分成小段。
- Flit:是bandwidth 和storage allocation的基本单位。flit没有任何路由或序列信息,必须沿着整个所在的packet顺序传播。根据 NoC 链路宽度,packets被分解为一个或多个flits。
-
- Head flit, body flit, tail flit, head/tail flit.
- Head flit allocates channel state for a packet,and tail flit deallocates it,tail标记数据包的结尾。
- header flit里有destination adderss和sequence number。
- Phit: (physical transfer digits) 是在一个时钟周期内通过通道传输的单位。
Interconnection network performance of multi-core cluster architectures
- Packets or Flits?
Contradictory requirements on packets
- Packets should be very large in order to reduce overhead of routing and sequencing
- Packets should be very small to allow efficient and fine-grained resource allocation and minimize blocking latency
Flits try to eliminate this conflict
- Packets can be large (low overhead)
- Flits can be small (efficient resource allocation)
- Size: Phit, Flit, Packet
There are no fixed rules for the size of phits, flits and packets
- Message: arbitrarily long
- Packets: restricted maximum length
Typical values
- Phits: 1 bit to 64 bits
- Flits: 16 bits to 512 bits
- Packets: 128 bits to 1024 bits
1.4 路由选择算法routing algorithm
在NoC (Network-on-Chip)设计中,路由算法是决定数据包在网络中从源节点到目标节点传输路径的关键组成部分。以下是Gem5提供的两种常见的路由算法
- Mesh XY routing:这是一种常用于Mesh或Torus拓扑的确定性路由算法。在这种算法中,数据包首先在X轴上移动,直到它到达目标节点的列,然后在Y轴上移动,直到到达目标节点。这种路由方法的优点是简单和直接,缺点是可能导致网络中某些部分的通信瓶颈。
- Weight-based Table routing:这是一种更复杂的路由方法,其中每个可能的路径或链接都分配有一个权重值。路由决策基于这些权重值,数据包倾向于选择权重最高(或最低)的路径。权重可以根据许多因素进行分配,例如路径长度、拥塞状况或能耗。这种方法可以提供比XY routing更好的性能,但设计和实现更复杂,且可能需要更多的硬件资源。
在设计NoC系统时,需要根据特定的系统需求和设计目标进行选择和优化。
- Deterministic Routing:这是一种基本的路由方法,其中对于给定的源和目标,路由路径是固定的。Mesh XY routing是这类路由算法的一个例子。
- Oblivious Routing:在这种算法中,路由路径是由源和目标节点决定的,但是并不考虑网络的实时或历史拥塞信息。因此,即使某些路径出现拥塞,路由选择也不会改变。
- Adaptive Routing:这是一种更复杂的路由策略,可以在运行时根据网络条件(如拥塞)动态改变路由路径。例如,最小剩余容量优先(Minimal Adapative Routing)会优先选择拥塞程度最低的路径。
- Weight-based Routing:在这种方法中,每条路径或链接都有一个权重,路由选择依赖于这些权重。权重可以根据多种因素设置,如路径长度、拥塞程度、能耗等。
- DyAD - Dynamic Adaptive Decisions in On-Chip Routing: 这是一种特殊的自适应路由算法,能够在动态和静态路由决策之间进行平衡。在DyAD中,使用一种基于历史和实时拥塞信息的方法,根据网络条件动态地调整路由。
1.5 NoC失效的一些情况:死锁Deadlock、拥塞Congestion
- 死锁(Deadlock): 死锁是指在多任务系统中,两个或多个任务相互等待对方释放资源,导致任务无法继续进行的现象。在NoC中,例如,当网络路由器试图转发数据包时,如果所有可能的输出通道都被其他数据包占用,且这些数据包也在等待其他输出通道,就会形成一个循环等待,从而导致路由死锁。
- 饥饿(Starvation): 在NoC系统中,饥饿是指某些任务或数据包由于其他高优先级的任务或数据包不断占用资源,导致无法获得足够的资源来完成它们的操作。
- 拥塞(Congestion): 当数据包在NoC中的流量超过网络的处理能力,就可能会发生拥塞。这可能会导致数据包的延迟增加,甚至可能导致数据丢失。
- 路由问题(Routing Issues): 不正确或低效的路由策略可能会导致数据包在到达目的地之前需要经过更多的跳数,从而增加了传输延迟并降低了网络性能。
2. Router architecture
NoC中的路由器是一种专门为芯片级通信而设计的高度优化组件。它们基于特定的路由算法,使用多个输入/输出端口和缓冲区来实现数据传输和路由选择。路由器的设计目标是提供高性能、低延迟和可靠的通信,在大规模集成电路中支持高度并行的处理单元间的通信需求。

Efficient Configurable Crossbar Switch Design For
Noc
2.1 Router的内部结构
一个典型的基于“Message Passing” Systems的NoC路由器Router的结构如图所示,他由InputUnit(输入单元)、OutputUnit(输出单元)、Routing Computation(路由计算器)、Switch Allocator(开关分配器)、Virtual Channel Allocator(虚拟通道分配器)、Crossbar(横梁交叉开关矩阵)组成。

- Input Unit(输入单元):输入单元主要负责接收来自其他节点的数据。这里面可能包括多个==虚拟通道==(Virtual Channels),每一个VC都有独立的缓存队列。输入单元由输入缓冲器(input buffer)和相关的链路控制逻辑组成。输入缓冲器由 SRAM 单元或寄存器构建。缓冲槽被组织成若干个队列,每个队列是一个VC。
- Output Unit(输出单元):每个路由器的Output Unit都会维护一个credit计数器或寄存器,用于记录每个目标路由器Input Unit的剩余credit。当一个数据包从Output Unit发送并被目标路由器的Input Unit成功接收和处理后,目标路由器会返回一个credit给源路由器,源路由器的Output Unit会相应地更新credit寄存器,增加对应目标路由器Input Unit的credit计数。输出单元会根据虚拟通道的调度策略,如循环调度或优先级调度,来决定下一个从哪个虚拟通道中取出数据。输出单元通过多个寄存器跟踪下游 VC 的状态。
- “input_vc”寄存器是下游VC被分配到的输入VC,VC进到从这个地方后出去到后续的Router。
- 当 1 位“idle”寄存器的值为“真”时,下游 VC 收到最后分配的数据包的尾部迁移,现在可以重新分配给其他数据包。
- “credits”寄存器记录credits数额
- Routing Computation(路由计算器):路由计算器根据预先定义的路由算法(如XY路由或者自适应路由等)来决定每一个数据包的下一个路由路径。这个过程通常依赖于数据包的目的地址和当前的网络状况。计算是根据head flit携带的目的地位置进行的,它为数据包产生输出端口和输出VC
- Switch Allocator(开关分配器):开关分配器用于决定在下一个时钟周期中,哪个输入单元的数据包将被分配到哪个输出单元。它需要协调可能的冲突,例如,当多个输入单元想要发送数据到同一个输出单元的时候。他控制着Crossbar。
- Virtual Channel Allocator(虚拟通道分配器):虚拟通道分配器用于管理输入单元中虚拟通道的使用。当一个数据包从一个输入单元的虚拟通道准备转移到另一个输出单元的虚拟通道时,需要虚拟通道分配器进行协调和分配。开关分配器(Switch Allocator)在决定给某个输出端口分配哪个输入端口的数据包时,就需要考虑这个输出端口剩余的信用(Credit)。只有当输出端口有足够的信用来接收新的数据包,开关分配器才会分配数据包到这个输出端口。Routing Computation 完成后,head flit 请求输出 VC。VC 分配器收集来自所有输入 VC 的请求,然后将输出 VC 分配给请求输入 VC。它保证一个输出VC最多分配给一个输入VC,并且每个输入VC最多被授予一个输出VC。
- Crossbar(横梁交叉开关矩阵):交叉开关一般用多个多路复用器来实现。这些多路复用器的控制信号由开关分配器生成。交叉开关矩阵是路由器的核心,它连接了所有的输入单元和输出单元,在每一个时钟周期中,根据Switch Allocator的决定,会建立或断开特定的输入单元到输出单元的连接。
VC 虚拟通道
VC(Virtual Channel,虚拟通道),是用于在同一物理连接中复用传输的技术,它可以有效地减少网络阻塞,提高带宽利用率。
在NoC (Network-on-Chip) 路由器中,一种常见的流量控制策略是使用信用(credit)系统。这种系统是为了防止发生数据堵塞和数据丢失。
具体来说,每个输出端口(或者说每个虚拟通道)会有一定数量的信用,这个数量等于它的缓冲区大小。每当从该输出端口发送一个数据包时,它就会消耗一个信用。当该输出端口的目的输入端口收到这个数据包,并且在其缓冲区中为这个数据包腾出了空间,它就会返回一个信用给原输出端口。
开关分配器(Switch Allocator)在决定给某个输出端口分配哪个输入端口的数据包时,就需要考虑这个输出端口剩余的信用。只有当输出端口有足够的信用来接收新的数据包,开关分配器才会分配数据包到这个输出端口。
这样,信用系统就实现了反馈控制,有效地防止了由于缓冲区溢出而导致的数据丢失,也避免了无效的数据包传输,提高了数据传输的效率。
- 一个VC里存了一组flit吗?还是一个flit的一部分?
- 答:一个虚拟通道(Virtual Channel, VC)可以存储一个或多个完整的flit(flow control digit)。
- 增加虚拟通道的数量会有以下一些可能的影响
- 增加硬件复杂性和成本:每个虚拟通道都需要其自身的缓冲区和状态机来处理存储和转发数据包。因此,增加虚拟通道的数量将会增加设计的复杂性和硬件成本。
- 提高并行性和带宽:更多的虚拟通道意味着可以同时处理更多的数据包,从而提高系统的并行性和带宽。
- 改善网络性能:更多的虚拟通道可以提供更多的路由选择,从而改善网络的性能,特别是在网络拥塞的情况下。
- 可能会增加功耗:由于每个虚拟通道都需要处理和转发数据包,增加虚拟通道的数量可能会增加系统的功耗。
- 延迟可能会有所增加:虚拟通道分配器在决定哪个数据包使用哪个虚拟通道时可能需要更多的时间,这可能会增加数据包的传输延迟。
2.2 流水线,用于NoC内部router传递消息
流水线确保通过网络有效地路由数据包或消息。

- head flit 到达输入端口后,首先根据其在流水线阶段的缓冲区写入(BW) 阶段输入 VC 进行解码和缓冲。
- 接下来,路由逻辑执行路由计算 (RC) 以确定数据包的输出端口。
- head flit然后在VA阶段(Virtual Channel分配)仲裁与其输出端口对应的VC(即,在下一个路由器的输入端口的VC)。
- 成功分配 VC 后,头部 flit 进入开关分配 (SA) 阶段,在该阶段仲裁开关输入和输出端口。
- 在赢得输出端口后,然后从缓冲区中读取 flit 并进入交换机遍历 (ST) 阶段,在该阶段它遍历交叉开关。
- 最后,flit 在链路遍历 (LT) 阶段被传递到下一个节点。Body 和 tail flits 遵循类似的管道,只是它们不经过 RC 和 VA 阶段,而是继承由 head flit 分配的路由和 VC。tail flit 在离开路由器时,释放 head flit 保留的 VC。
1.1 BW: Buffer Write 缓冲区写入
在此阶段,传入的数据包或消息临时存储在输入缓冲区中。 路由器的每个输入端口都有自己的缓冲区来保存传入数据。 缓冲区写入阶段根据数据包的目标地址将传入数据写入适当的缓冲区。
1.2 RC: Route Compute 路由计算
在路由计算阶段,路由器为传入的数据包确定一个或多个适当的输出端口。 它使用路由算法或表来做出此决定。 路由决策基于数据包的目标地址和网络的当前状态。
1.3 VA: VC(Virtual Channel) Allocation 虚拟通道分配
Input VCs arbitrate for “output” VCs (Input VCs at next router) 输入 VC 仲裁
虚拟通道用于在物理链路内提供多个独立的通信路径。 在VC分配阶段,路由器将输入虚拟通道分配给输出虚拟通道。 这个过程允许拥塞管理,并通过允许数据包在不同的虚拟通道上同时传输来提供改进的性能。
1.4 SA: Switch Allocation 开关分配
Input ports arbitrate for output ports 输入端口仲裁输出端口
在交换机分配阶段,路由器的输入端口仲裁对输出端口的访问。 该仲裁过程确定哪个输入端口可以使用哪个输出端口来传输其数据。 目标是最大程度地减少争用并确保对网络资源的公平访问。
1.5 ST: Switch Traversal 切换遍历
在Switch Traversal阶段,根据交换机分配结果将数据包从输入端口转发到路由器的输出端口。 遵循前面阶段确定的路由路径,将数据包定向到它们指定的输出端口。
1.6 LT: Link Traversal 链接遍历
最后,在链路遍历阶段,数据包遍历连接网络中路由器的物理链路。 此阶段涉及通过链路实际传输数据包以到达其预定目的地。
3. 缓存一致的内存访问结构Cache Coherence Protocols
缓存一致性(Cache Coherence)是指在多处理器系统中,各处理器的缓存(Cache)之间如何保持一致的问题。具体来说,当多个处理器的缓存中存储了同一块主内存区域的副本时,任何对该内存区域的写操作都必须在所有缓存中体现出来,以保持所有的缓存一致。

多种不同的缓存一致性协议,它们被设计用于处理这个问题,以下是一些常见的协议:
- MSI (Modified, Shared, Invalid):这是最基础的缓存一致性协议。在这个协议中,每个缓存块有三种可能的状态:Modified(修改过的,表示该缓存块已经被修改,并且是唯一的,即它的内容与主内存中的内容不同),Shared(共享的,表示该缓存块可能在多个缓存中存在),Invalid(无效的,表示该缓存块的内容已经过期或无效)。
- MESI (Modified, Exclusive, Shared, Invalid):这是一个在MSI的基础上增加了"Exclusive"状态的协议。Exclusive状态表示该缓存块只存在于当前缓存中,并且它的内容与主内存中的内容相同。这种状态可以在需要写操作时,避免访问总线以改变缓存块的状态。
- MOESI (Modified, Owner, Exclusive, Shared, Invalid):这是一个更进一步的协议,它在MESI的基础上增加了"Owner"状态。Owner状态表示该缓存块在多个缓存中存在,但是只有一个"Owner"缓存保存了最新的副本。
- MOSI (Modified, Owner, Shared, Invalid):这是一个类似于MOESI的协议,但是没有"Exclusive"状态。
以上只是一些基本的缓存一致性协议。实际上,有许多不同的缓存一致性协议,它们都有各自的优点和缺点,适用于不同的场景和需求。
以下是一些在NoC中可能使用的缓存一致性协议:
- Directory-based Protocols:在这类协议中,一个或多个目录被用来跟踪每个缓存行的状态和位置。当处理器需要读取或写入数据时,它首先检查目录来确定数据的状态和位置。目录可以位于单独的控制器中,也可以分布在所有处理器中。
- Snooping Protocols:在这类协议中,所有缓存都监听(或者说"snoop")所有的总线事务(即读取和写入请求)。如果缓存看到一个它有的地址被访问,它就会根据请求类型和缓存行的当前状态进行相应的操作。MSI、MESI、MOESI和MOSI就是snooping协议的例子。
- Token Coherence Protocols:这是一种较新的协议,它通过在缓存之间传递token来维护一致性。当一个缓存需要写入数据时,它必须首先收集所有的token。这个协议的好处是它可以更灵活地管理数据的传输,从而提高性能。
- Hybrid Protocols:这类协议结合了目录和snooping的优点,以提高大规模多处理器系统的缓存一致性。
All You Need Is Cache (Coherency) To Scale Next-Gen SoC Performance
4. 流量控制机制
Mesh_XY网络是一种基于网格结构的拓扑,通常用于多处理器系统-on-a-chip(MPSoC)或片上网络(Network-on-Chip,NoC)中。它由一个二维网格组成,其中每个节点(或处理器)与其相邻的节点直接连接。节点可以沿X轴和Y轴方向上的连接进行通信。
4.1 基于信用(credit-based)的流量控制机制
在基于信用的流量控制中,每个下游路由器都维护了一个信用计数器,用于跟踪其可用的缓冲空间。当一个数据包(或者说flit)被成功接收后,下游路由器会向上游路由器发送一个信用(credit),表示它已经释放了一个缓冲位置。当上游路由器收到信用后,它就知道可以发送一个新的数据包。
这种机制的好处是它可以避免网络拥塞和数据包的丢失。由于每个路由器都知道其下游路由器的可用缓冲空间,所以它们不会发送超出能力的数据包。

NoC Generation for Hermes TB
4.2 基于握手(handshaking)的流量控制机制
基于握手的流量控制,比如在AXI(Advanced eXtensible Interface)总线协议中使用的机制,是一种请求-确认协议。在这种机制中,发送者在发送数据包之前首先发送一个请求信号给接收者。如果接收者有足够的缓冲空间,它就会返回一个确认信号,然后发送者才会发送数据包。
这种机制的好处是它可以精确地控制数据的发送,从而避免网络拥塞。然而,由于每次发送数据都需要先进行请求和确认,所以它的性能可能会受到一些影响。

A flexible design of network on chip router based on handshaking communication mechanism
4.3 Wormhole packet switching flow-control
- Wormhole Packet Switching: 在NoC中,Wormhole路由是一种高效的数据包交换策略。在此策略中,一条消息被分割成多个小的数据包,或者称为flits(flow control digits)。这些flits会立即被发送到网络中,而不是等待整个消息都被装入缓冲区。这样可以减少数据在网络中的延迟时间。每个flit按照顺序路由,使得在路由过程中只需要很小的缓冲区。这就是它被称为“虫洞”路由的原因——数据就像是在虫洞中穿越,瞬间从一点传到另一点。
- Flow-Control: 在NoC中,流量控制是一种方法,用于管理数据包的发送,以防止接收端的缓冲区溢出。Wormhole路由策略中常见的一种流量控制策略是基于信用的流量控制,其中发送节点需要从接收节点获得信用(代表其可用的缓冲区大小)才能发送flit。这样可以确保接收端的缓冲区不会溢出,从而提高整个系统的稳定性。

4.4 其他流量控制机制
除了基于信用(credit-based)和基于握手(handshaking)的流量控制机制外,还有其他的流量控制策略,这些策略在不同的网络系统和应用场景中可能会更有效。下面是一些例子:
- 基于窗口(Window-based)的流量控制:这种方法通常用于传输控制协议(TCP)中。发送方维护一个窗口,窗口大小表示可以发送并且没有被确认的数据包的数量。当接收方确认了一个数据包,窗口就会向前滑动,允许发送方发送更多的数据包。
- 基于速率(Rate-based)的流量控制:这种方法中,发送者和接收者协商一个数据的发送速率,然后发送者根据这个速率来发送数据。这种方法可以在一些高速网络中使用,例如ATM(异步传输模式)网络。
- 基于反馈(Feedback-based)的流量控制:这种方法中,接收方根据其当前的资源使用情况(例如,缓冲区的使用情况或处理器的使用情况)向发送方反馈信息。发送方根据这个反馈来调整其数据的发送速度。
- 基于优先级(Priority-based)的流量控制:在这种策略中,数据包根据其重要性或紧急性被赋予不同的优先级。网络设备根据这些优先级来决定数据包的发送顺序。
5. 网络接口 Network Interface
NI (Network Interface,网络接口,有的文献也称为Network Adapter)作为独立的硬件实体,使得具有不同数据宽度和频率的 IP 内核连接到 NoC 成为可能。换句话说,通过将计算与通信解耦,NI允许 PE模块和互连设计彼此独立。NI的设计直接影响基于 NoC 的 SoC 关键参数,例如功耗、延迟、吞吐量和硅面积。NI的架构分为:
- 基于buffer(包括基于 FIFO 和基于 DMA);
- 基于Transaction(包括 OCP 兼容、AHP 兼容、DTL 兼容、Wishbone 兼容、VCI 兼容) , 和 AXI 兼容)。
5.1 基于FIFO的NI结构
基于FIFO的网络接口主要分为发送(TX)和接收(RX)部分。
-
发送部分的FIFO缓冲区用于存储要发送到网络的数据包,为网络忙碌时的数据提供了缓冲,防止丢失。当网络路径可用,数据包就从FIFO中取出并发送。FIFO的优点是能够容纳在网络忙碌时无法立即发送的数据包,从而提供一种缓冲机制,防止数据的丢失。当网络接口检测到网络上有可用的路径时,它会从FIFO中取出数据包并将其发送到网络上。
-
接收部分的FIFO存储从网络接收的数据包。数据包在处理器或内存模块准备接收之前,先被存放在FIFO中。这为接收数据提供了缓冲,使得网络接口可以在处理器或内存模块未准备好时继续接收数据。

3D IC 2-tier 16PE Multiprocessor with 3D NoC Architecture Based on Tezzaron Technology
5.2 符合 Wishbone 总线的NI结构
每个Tile里的计算单元或者SoC可能会用到总线,如果想了解这个SoC是怎么通过NI连接到NoC中,要了解一些总线的基本信息。
Wishbone 总线
Wishbone总线是由Silicon Labs开发的开放标准,广泛用于系统级集成(SoC)设计中的模块间通信。这种设计提供了一种标准化的方法,使不同的硬件模块可以通过统一的总线接口进行连接和通信。
ProNoC是一个可配置的网络芯片(NoC)生成器和配置工具,它允许设计师为他们的特定应用生成和配置网络芯片。在ProNoC中,Wishbone可能被用作模块间通信的总线协议。具体地,当各种IP核需要在SoC设计中进行交互时,Wishbone可以为这些核提供一种通信机制。
ProNoC:一种基于低延迟片上网络的多核片上系统原型设计平台

一种通用的 Wishbone 总线的NI结构

-
实现:将flits从IP写入/读取Router。
-
NoC里的通信都是由一组flit组成的packets。通过组装flits数量、header flit、精确的flits数量插入flit类型,对来自IP的传入信号进行打包,并根据IP核心规范解包来自路由器的信号。
-
在不丢失数据的情况下,将数据从一个时钟域转移到另一个时钟域。
ProNoC中的NI接口
网络接口(NI)作为处理器(PT)和网络芯片路由器(NoC router)之间的包装器。图6显示了在ProNoC中的NI的结构框图。
ProNoC:一种基于低延迟片上网络的多核片上系统原型设计平台
- 图左边的Wishbone Bus Interface连着每个Tile里的IP;
- 图右边的NoC Router Interface连着每个Tile里的Router;

-
NI有三个Wishbone(WB)接口:一个从接口和两个主接口。
-
NI和内存之间的通信采用突发模式,通过连接到多通道直接内存访问(DMA)的两个主接口进行处理。
-
每个DMA的通道处理一个路由器的虚拟通道(VC)。当突发交易完成或者活动VC的资源不再可用时,DMA会在通道之间切换。
-
NI还可以选择配置32位循环冗余校验(CRC32)代码生成器,以检测接收数据包中的意外错误。
-
主IP可以读取NI状态寄存器,或者通过WB从接口编程NI进行读/写数据包。
为什么在ProNoC的NI的总线端口里要有一个从接口和两个主接口?
在 ProNoC 的网络接口 (NI) 的Wishbone Bus Interface有一个从接口和两个主接口。其中:
- 从接口:连接到这个Tile里的 IP,用于接收来自IP的请求。这些请求可能是发送数据(写操作)或者接收数据(读操作)。
- 主接口:连接到多通道的直接内存访问(DMA)。DMA控制器可以管理多个数据传输通道,这种设计可以提高数据传输的并行性,从而提高整体系统性能。
两个主接口:每个主接口连接一个 DMA,每个 DMA 的通道处理一个路由器的虚拟通道(VC),这样可以允许 NI 同时进行多个内存访问操作。当一个突发事务完成或者当前活动的虚拟通道的资源不再可用时,DMA会在通道间进行切换。这种方式使得NI能够以突发模式与内存进行通信,实现高效的数据传输。
如何处理一个IP的信息并转化为packet消息发送到Router?
网络接口(NI)作为 IP 核心和 NoC 路由器之间的桥梁,起着非常重要的角色。它负责接收来自 IP 核的数据,然后将这些数据打包成可以在 NoC 中发送的数据包。ProNoC里NI中的Wishbone Bus Interface和NoC Router Interface是如何处理一个IP的信息并转化为packet信息发送到Router的?
- IP请求数据发送:首先,IP核(比如一个处理器或其他硬件模块)将数据和相关信息(如目标地址等)发送给 NI。这个过程通过 Wishbone Bus Interface 的从接口(slave interface)完成。
- 数据分组:NI 接收到这些数据后,将其分组(packetize),也就是将数据和相关信息封装成一个数据包。这个过程可能包括添加源和目标地址,生成错误检测和纠正码(如CRC),以及其他网络所需的信息。此外,根据网络的流量控制策略(如虫洞切换,虚拟切割等),可能还需要进一步将这个数据包分割成更小的分组(flit)。
- 数据缓存:然后,这些分组被放入一个队列(如FIFO队列)以等待发送。每个队列对应一个或多个虚拟通道(VC)。
- 数据发送:在适当的时间,NI 通过 Wishbone Bus Interface 的主接口(master interface)和 DMA 控制器启动对应的内存读/写操作,将数据送入 NoC Router Interface。然后,这些数据被送入相应的虚拟通道,并被发送到 NoC 路由器。
- 路由器处理:NoC 路由器接收到这些数据后,根据数据包的目标地址和路由算法,将其发送到目标网络接口。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐


 29
29 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)