gemma 大模型(gemma 2B,gemma 7B)微调及基本使用
Gemma是Google推出的一系列轻量级、最先进的开放模型,基于创建Gemini模型的相同研究和技术构建。提供了 2B 和 7B 两种不同规模的版本,每种都包含了预训练基础版本和经过指令优化的版本。所有版本均可在各类消费级硬件上运行,无需数据量化处理,拥有高达 8K tokens 的处理能力:它们是文本到文本的、仅解码器的大型语言模型,提供英语版本,具有开放的权重、预训练的变体和指令调优的变体。
待整理…
gemma介绍
-
Gemma是Google推出的一系列轻量级、最先进的开放模型,基于创建Gemini模型的相同研究和技术构建。提供了 2B 和 7B 两种不同规模的版本,每种都包含了预训练基础版本和经过指令优化的版本。所有版本均可在各类消费级硬件上运行,无需数据量化处理,拥有高达 8K tokens 的处理能力:
-
它们是文本到文本的、仅解码器的大型语言模型,提供英语版本,具有开放的权重、预训练的变体和指令调优的变体。
-
Gemma模型非常适合执行各种文本生成任务,包括问答、摘要和推理。它们相对较小的尺寸使得可以在资源有限的环境中部署,例如笔记本电脑、桌面电脑或您自己的云基础设施,使每个人都能获得最先进的AI模型,促进创新。
-
Github地址:https://github.com/google/gemma_pytorch
-
论文地址:https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf
-
官方博客:Gemma: Google introduces new state-of-the-art open models
其它
BPE。
又称 digram coding 双字母组合编码,是一种数据压缩 算法,用来在固定大小的词表中实现可变⻓度的子词。该算法简单有效,因而目前它是最流行的方法。
peft
GPT,gemma,BERT这些大型预训练模型的训练成本非常高昂,需要庞大的计算资源和大量的数据,一般人难以承受。这也导致了一些研究人员难以重复和验证先前的研究成果。为了解决这个问题,研究人员开始研究Parameter-Efficient Fine-Tuning (PEFT)技术。
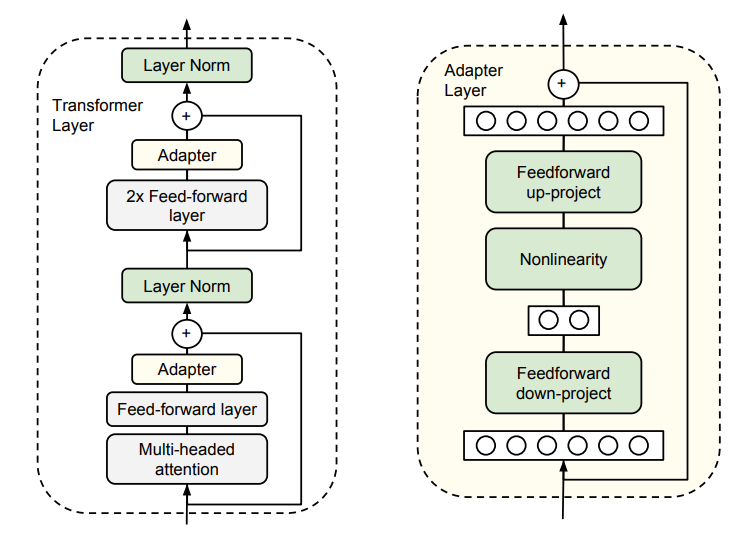
Adapter Tuning
谷歌的研究人员首次在论文《Parameter-Efficient Transfer Learning for NLP》提出针对BERT的PEFT微调方式,拉开了PEFT研究的序幕。他们指出,在面对特定的下游任务时,如果进行Full-fintuning(即预训练模型中的所有参数都进行微调),太过低效;而如果采用固定预训练模型的某些层,只微调接近下游任务的那几层参数,又难以达到较好的效果。
于是他们设计了如下图所示的Adapter结构,将其嵌入Transformer的结构里面,在训练时,固定住原来预训练模型的参数不变,只对新增的Adapter结构进行微调。同时为了保证训练的高效性(也就是尽可能少的引入更多参数),他们将Adapter设计为这样的结构:首先是一个down-project层将高维度特征映射到低维特征,然后过一个非线形层之后,再用一个up-project结构将低维特征映射回原来的高维特征;同时也设计了skip-connection结构,确保了在最差的情况下能够退化为identity。

从实验结果来看,该方法能够在只额外对增加的3.6%参数规模(相比原来预训练模型的参数量)的情况下取得和Full-finetuning接近的效果(GLUE指标在0.4%以内)。
Prefix Tuning
Prefix Tuning方法由斯坦福的研究人员提出,与Full-finetuning更新所有参数的方式不同,该方法是在输入token之前构造一段任务相关的virtual tokens作为Prefix,然后训练的时候只更新Prefix部分的参数,而Transformer中的其他部分参数固定。该方法其实和构造Prompt类似,只是Prompt是人为构造的“显式”的提示,并且无法更新参数,而Prefix则是可以学习的“隐式”的提示。
同时,为了防止直接更新Prefix的参数导致训练不稳定的情况,他们在Prefix层前面加了MLP结构(相当于将Prefix分解为更小维度的Input与MLP的组合后输出的结果),训练完成后,只保留Prefix的参数。
Prompt Tuning
《The Power of Scale for Parameter-Efficient Prompt Tuning》
总的来说就是,只要模型规模够大,简单加入Prompt tokens进行微调,就能取得很好的效果。
该方法可以看作是Prefix Tuning的简化版本,只在输入层加入prompt tokens,并不需要加入MLP进行调整来解决难训练的问题,主要在T5预训练模型上做实验。似乎只要预训练模型足够强大,其他的一切都不是问题。作者也做实验说明随着预训练模型参数量的增加,Prompt Tuning的方法会逼近Fine-tune的结果。
作者做了一系列对比实验,都在说明:随着预训练模型参数的增加,一切的问题都不是问题,最简单的设置也能达到极好的效果。
a) Prompt长度影响:模型参数达到一定量级时,Prompt长度为1也能达到不错的效果,Prompt长度为20就能达到极好效果。
b) Prompt初始化方式影响:Random Uniform方式明显弱于其他两种,但是当模型参数达到一定量级,这种差异也不复存在。
c) 预训练的方式:LM Adaptation的方式效果好,但是当模型达到一定规模,差异又几乎没有了。
d) 微调步数影响:模型参数较小时,步数越多,效果越好。同样随着模型参数达到一定规模,zero shot也能取得不错效果。
P-Tuning
P-Tuning方法的提出主要是为了解决这样一个问题:大模型的Prompt构造方式严重影响下游任务的效果。
P-Tuning提出将Prompt转换为可以学习的Embedding层,只是考虑到直接对Embedding参数进行优化会存在这样两个挑战:
- Discretenes: 对输入正常语料的Embedding层已经经过预训练,而如果直接对输入的prompt embedding进行随机初始化训练,容易陷入局部最优。
- Association:没法捕捉到prompt embedding之间的相关关系。
作者在这里提出用MLP+LSTM的方式来对prompt embedding进行一层处理
与Prefix-Tuning的区别
这篇文章(2021-03)和Prefix-Tuning(2021-01)差不多同时提出,做法其实也有一些相似之处,主要区别在
- Prefix Tuning是将额外的embedding加在开头,看起来更像是模仿Instruction指令;而P-Tuning的位置则不固定。
- Prefix Tuning通过在每个Attention层都加入Prefix Embedding来增加额外的参数,通过MLP来初始化;而P-Tuning只是在输入的时候加入Embedding,并通过LSTM+MLP来初始化。
V2
论文《P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks》
P-Tuning v2的目标就是要让Prompt Tuning能够在不同参数规模的预训练模型、针对不同下游任务的结果上都达到匹敌Fine-tuning的结果。
那也就是说当前Prompt Tuning方法未能在这两个方面都存在局限性。
- 不同模型规模:Prompt Tuning和P-tuning这两种方法都是在预训练模型参数规模够足够大时,才能达到和Fine-tuning类似的效果,而参数规模较小时效果则很差。
- 不同任务类型:Prompt Tuning和P-tuning这两种方法在sequence tagging任务上表现都很差。
主要结构
相比Prompt Tuning和P-tuning的方法, P-tuning v2方法在多层加入了Prompts tokens作为输入,带来两个方面的好处:
- 带来更多可学习的参数(从P-tuning和Prompt Tuning的0.1%增加到0.1%-3%),同时也足够parameter-efficient。
- 加入到更深层结构中的Prompt能给模型预测带来更直接的影响。
几个关键设计因素
- Reparameterization:Prefix Tuning和P-tuning中都有MLP来构造可训练的embedding。本文发现在自然语言理解领域,面对不同的任务以及不同的数据集,这种方法可能带来完全相反的结论。
- Prompt Length: 不同的任务对应的最合适的Prompt Length不一样,比如简单分类任务下length=20最好,而复杂的任务需要更长的Prompt Length。
- Multi-task Learning 多任务对于P-Tuning v2是可选的,但可以利用它提供更好的初始化来进一步提高性能。
- Classification Head 使用LM head来预测动词是Prompt Tuning的核心,但我们发现在完整的数据设置中没有必要这样做,并且这样做与序列标记不兼容。P-tuning v2采用和BERT一样的方式,在第一个token处应用随机初始化的分类头。
LoRA
微软和CMU的研究者指出,现有的一些PEFT的方法还存在这样一些问题:
- 由于增加了模型的深度从而额外增加了模型推理的延时,如Adapter方法
- Prompt较难训练,同时减少了模型的可用序列长度,如Prompt Tuning、Prefix Tuning、P-Tuning方法
- 往往效率和质量不可兼得,效果差于full-finetuning。
有研究者对语言模型的参数进行研究发现:语言模型虽然参数众多,但是起到关键作用的还是其中低秩的本质维度(low instrisic dimension)。本文受到该观点的启发,提出了Low-Rank Adaption(LoRA),设计了如下所示的结构,在涉及到矩阵相乘的模块,引入A、B这样两个低秩矩阵模块去模拟Full-finetune的过程,相当于只对语言模型中起关键作用的低秩本质维度进行更新。


这么做就能完美解决以上存在的3个问题:
- 相比于原始的Adapter方法“额外”增加网络深度,必然会带来推理过程额外的延迟,该方法可以在推理阶段直接用训练好的A、B矩阵参数与原预训练模型的参数相加去替换原有预训练模型的参数,这样的话推理过程就相当于和Full-finetune一样,没有额外的计算量,从而不会带来性能的损失。
- 由于没有使用Prompt方式,自然不会存在Prompt方法带来的一系列问题。
- 该方法由于实际上相当于是用LoRA去模拟Full-finetune的过程,几乎不会带来任何训练效果的损失,后续的实验结果也证明了这一点。
在实验中,研究人员将这一LoRA模块与Transformer的attention模块相结合,在RoBERTa 、DeBERTa、GPT-2和GPT-3 175B这几个大模型上都做了实验,实验结果也充分证明了该方法的有效性。
UniPELT
Towards a Unified View of PETL
这篇ICLR2022的文章研究了典型的PEFT方法,试图将PEFT统一到一个框架下,找出它们起作用的具体原因,并进行改进。主要研究了三个问题:
- 典型的PEFT方法有什么联系?
- 典型的PEFT方法中是哪些关键模块在起作用?
- 能否对这些关键模块进行排列组合,找出更有用的PEFT方法?
通过对Prefix Tuning的推导,得出了和Adapter Tuning以及LoRA形式一致的形式。
根据这个统一的框架,还另外设计了三种变体Parallel Adapter、Multi-head Parallel Adapter、Scaled Parallel Adapter。
QLoRA
Efficient Finetuning of Quantized LLMs
这篇论文由 UW 的四位作者发表于 23 年5月底,一经发布就大火,在算力昂贵的时代,它这个新技术可以节约数十倍的显存且几乎没有损失性能。该技术降低了推理和训练大模型的门槛,让更广大的性价比玩家看到了希望。
新的微调方法取名为QLoRA,它可以显著减少内存使用,使得可以在单个48GB的GPU上微调一个有650亿参数的模型,同时保持16比特微调的性能。QLoRA通过冻结的、4比特量化的预训练语言模型来做 LoRA,进行反向传播梯度。作者提出的最佳模型命名为Guanaco,在Vicuna基准测试中超越了所有以前公开发布的模型,达到了ChatGPT性能水平的99.3%,而只需要在单个GPU上微调24小时。
QLORA引入了几项创新来节省内存而不牺牲性能,包括
- 一种新的数据类型4位NormalFloat(NF4);
- 双重量化以减少平均内存占用;
- 分页优化器来管理内存峰值。
作者使用 QLoRA 技术微调了 1000 多个模型来实验,在一些小型高质量数据集上可以做到 SOTA,甚至用更小的模型也能做到 SOTA。
4-bit NormalFloat Quantization
NormalFloat (简称NF)是一种数据类型,它是建立在 Quantile quantization(后译为分位数量化)基础上的,它是一种信息论上最优的数据类型,可以确保每个量化区间从输入张量中分配相同数量的值。分位数量化通过经验累积分布函数估计输入张量的分位数来工作。分位数量化的主要局限性在于分位数估计的这个过程会比较费力。
在神经网络中,预训练的权重通常具有零中心的正态分布,标准差为σ。通过缩放σ,可以使得分布恰好适应NF的范围。对于NF,作者设置了一个任意的范围[-1, 1]。因此,数据类型和神经网络权重的分位数都需要被归一化到这个范围。
对于范围在[-1, 1]内的零均值正态分布,他们计算了信息理论上最优的数据类型。这个过程包括:(1) 估计理论N(0, 1)分布的
- 1 个分位数,得到一个k位的分位数量化数据类型;(2) 将这个NF的值归一化到[-1, 1]范围;(3) 通过绝对最大值重标定,将输入权重张量归一化到[-1, 1]范围,然后进行量化。一旦模型权重范围和NF范围匹配,就可以像通常那样进行量化。这个过程等价于重新缩放权重张量的标准差,使其匹配k位数据类型的标准差。更具体的来看这个公式,展示了
到分位数的映射公式:

公式里的 Q x Q_x Qx 指的是分位数函数。在读到这个公式之后,突然感觉就恍然大悟了有没有!
一些实验
哪种嵌入形式更好:Parallel or Sequencial?
答案是:Parallel更好
对哪块结构做修改更好?Attention or FFN?
当微调的参数量较多时,从结果来看,对FFN层进行修改更好。一种可能的解释是FFN层学到的是任务相关的文本模式,而Attention层学到的是成对的位置交叉关系,针对新任务并不需要进行大规模调整。
哪种组合方式效果更好?
从结果来看,缩放式的组合效果更好。
FlashAttention
是一种重新排序注意力计算的算法,它无需任何近似即可加速注意力计算并减少内存占用。
演示
可以在 Hugging Chat 上体验与 Gemma 指令模型的互动对话!点击此处访问:https://huggingface.co/chat?model=google/gemma-7b-it
模型下载:
模型文件这里是从modelscope 下载的,也可以从Huggingface 下,Huggingface没有modelscope方便。
gemma-2b地址:
https://modelscope.cn/models/AI-ModelScope/gemma-2b/files
gemma-7b地址:
https://modelscope.cn/models/AI-ModelScope/gemma-7b/files
当然还有“gemma-7b-it”等其它版本。
Prompt 提示词格式
Gemma 的基础模型不限定特定的提示格式。如同其他基础模型,它们能够根据输入序列生成一个合理的续接内容,适用于零样本或少样本的推理任务。这些模型也为针对特定应用场景的微调提供了坚实的基础。指令优化版本则采用了一种极其简洁的对话结构:
<start_of_turn>用户_ _
敲击<end_of_turn>
<start_of_turn>模型
谁在那里< end_of_turn >
< start_of_turn >用户
Gemma <end_of_turn>
<start_of_turn>模型_ _ _ _
杰玛是谁?<转弯结束>
要有效利用这一格式,必须严格按照上述结构进行对话。
使用 Transformers
借助 Transformers 的 4.38 版本,你可以轻松地使用 Gemma 模型,并充分利用 Hugging Face 生态系统内的工具,包括:
- 训练和推理脚本及示例
- 安全文件格式(safetensors)
- 集成了诸如 bitsandbytes(4位量化)、PEFT(参数效率微调)和 Flash Attention 2 等工具
- 辅助工具和帮助器,以便使用模型进行生成
- 导出模型以便部署的机制
另外,Gemma 模型支持 torch.compile() 与 CUDA 图的结合使用,在推理时可实现约 4 倍的速度提升!
确保你使用的是最新版本的 transformers:pip install -U transformers
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
# Hugging Face model id
model_id = "./gemma-7b"
# BitsAndBytesConfig int-4 config
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, bnb_4bit_use_double_quant=True, bnb_4bit_quant_type="nf4", bnb_4bit_compute_dtype=torch.bfloat16
)
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16,
quantization_config=bnb_config
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.padding_side = 'right' # to prevent warnings
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
示例
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("./gemma-7b")
model = AutoModelForCausalLM.from_pretrained("./gemma-7b", device_map="auto")
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
微调 Gemma 模型
低秩适应(LoRA)是一种用于大语言模型(LLM)的参数高效微调技术。它只针对模型参数的一小部分进行微调,通过冻结原始模型并只训练被分解为低秩矩阵的适配器层。PEFT 库 提供了一个简易的抽象,允许用户选择应用适配器权重的模型层。
我们将所有的 nn.Linear 层视为要适应的目标层。
from peft import LoraConfig
lora_config = LoraConfig(
r=8,
target_modules=["q_proj", "o_proj", "k_proj", "v_proj", "gate_proj", "up_proj", "down_proj"],
task_type="CAUSAL_LM",
)
我们首先下载模型和分词器 (tokenizer),其中包含了一个 BitsAndBytesConfig 用于仅限权重的量化。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
model_id = "./gemma-2b"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bnb_config, device_map={"":0})
在开始微调前,我们先使用一个相当熟知的名言来测试一下 Gemma 模型:
text = "Quote: Imagination is more"
device = "cuda:0"
inputs = tokenizer(text, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
模型完成了一个合理的补全,尽管有一些额外的 token:

Quote: Imagination is more important than knowledge. Knowledge is limited. Imagination encircles the world.
-Albert Einstein
I
但这并不完全是我们希望看到的答案格式。我们将尝试通过微调让模型学会以我们期望的格式来产生答案:
Quote: Imagination is more important than knowledge. Knowledge is limited. Imagination encircles the world.
Author: Albert Einstein
首先,我们选择一个英文“名人名言”数据集:
这个数据集我是下载下来使用的。
from datasets import load_dataset
data = load_dataset("./Abirate/english_quotes")
data = data.map(lambda samples: tokenizer(samples["quote"]), batched=True)
接下来,我们使用上述 LoRA 配置对模型进行微调:
import transformers
from trl import SFTTrainer
def formatting_func(example):
text = f"Quote: {example['quote'][0]}\nAuthor: {example['author'][0]}"
return [text]
trainer = SFTTrainer(
model=model,
train_dataset=data["train"],
args=transformers.TrainingArguments(
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
warmup_steps=2,
max_steps=10,
learning_rate=2e-4,
fp16=True,
logging_steps=1,
output_dir="outputs",
optim="paged_adamw_8bit"
),
peft_config=lora_config,
formatting_func=formatting_func,
)
trainer.train()
最终,我们再次使用先前的提示词,来测试模型:
text = "Quote: Imagination is"
device = "cuda:0"
inputs = tokenizer(text, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
这次,我们得到了我们期待的答案格式:
Quote: Imagination is more important than knowledge. Knowledge is limited. Imagination encircles the world.
Author: Albert Einstein
中文的意思是:
名言:想象力比知识更重要,因为知识是有限的,而想象力概括着世界的一切.
作者:阿尔伯特·爱因斯坦
在 TPU 环境下微调,可通过 SPMD 上的 FSDP 加速
from transformers import DataCollatorForLanguageModeling, Trainer, TrainingArguments
# Set up the FSDP config. To enable FSDP via SPMD, set xla_fsdp_v2 to True.
fsdp_config = {
"fsdp_transformer_layer_cls_to_wrap": ["GemmaDecoderLayer"],
"xla": True,
"xla_fsdp_v2": True,
"xla_fsdp_grad_ckpt": True
}
# Finally, set up the trainer and train the model.
trainer = Trainer(
model=model,
train_dataset=data,
args=TrainingArguments(
per_device_train_batch_size=64, # This is actually the global batch size for SPMD.
num_train_epochs=100,
max_steps=-1,
output_dir="./output",
optim="adafactor",
logging_steps=1,
dataloader_drop_last = True, # Required for SPMD.
fsdp="full_shard",
fsdp_config=fsdp_config,
),
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
trainer.train()
最后的结果如下:

程序最后放到一起是:可以根据需要自行整理。
gpu环境:

from peft import LoraConfig
lora_config = LoraConfig(
r=8,
target_modules=["q_proj", "o_proj", "k_proj", "v_proj", "gate_proj", "up_proj", "down_proj"],
task_type="CAUSAL_LM",
)
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
model_id = "./gemma-2b"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bnb_config, device_map={"":0})
text = "Quote: Imagination is more"
device = "cuda:0"
inputs = tokenizer(text, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
from datasets import load_dataset
data = load_dataset("./Abirate/english_quotes")
data = data.map(lambda samples: tokenizer(samples["quote"]), batched=True)
import transformers
from trl import SFTTrainer
def formatting_func(example):
text = f"Quote: {example['quote'][0]}\nAuthor: {example['author'][0]}"
return [text]
trainer = SFTTrainer(
model=model,
train_dataset=data["train"],
args=transformers.TrainingArguments(
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
warmup_steps=2,
max_steps=10,
learning_rate=2e-4,
fp16=True,
logging_steps=1,
output_dir="outputs",
optim="paged_adamw_8bit"
),
peft_config=lora_config,
formatting_func=formatting_func,
)
trainer.train()
text = "Quote: Imagination is"
device = "cuda:0"
inputs = tokenizer(text, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
使用HuggingFace的Accelerate库加载和运行超大模型:
https://zhuanlan.zhihu.com/p/605640431

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐

 32
32 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)